示例文件
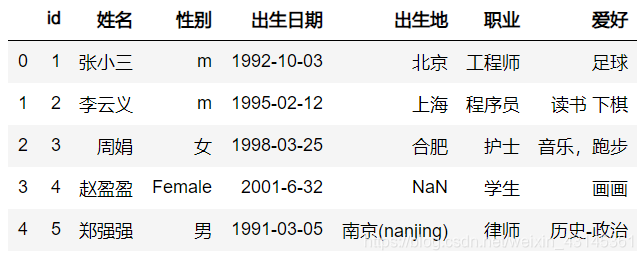
将以下内容保存为文件 people.csv。
id,姓名,性别,出生日期,出生地,职业,爱好
1,张小三,m,1992-10-03,北京,工程师,足球
2,李云义,m,1995-02-12,上海,程序员,读书 下棋
3,周娟,女,1998-03-25,合肥,护士,音乐,跑步
4,赵盈盈,Female,2001-6-32,,学生,画画
5,郑强强,男,1991-03-05,南京(nanjing),律师,历史-政治
如果一切正常的话,在Jupyter Notebook 中应该显示以下内容:
文件编码
文件编码格式是最容易出错的问题之一。如果编码格式不正确,就会完全读取不出文件内容,出现类似于以下的错误, 让人完全不知所措:
---------------------------------------------------------------------------
UnicodeDecodeError Traceback (most recent call last)
ipython-input-6-8659adefcfa6> in module>
----> 1 pd.read_csv('people.csv', encoding='gb2312')
C:\ProgramData\Anaconda3\lib\site-packages\pandas\io\parsers.py in parser_f(filepath_or_buffer, sep, delimiter, header, names, index_col, usecols, squeeze, prefix, mangle_dupe_cols, dtype, engine, converters, true_values, false_values, skipinitialspace, skiprows, skipfooter, nrows, na_values, keep_default_na, na_filter, verbose, skip_blank_lines, parse_dates, infer_datetime_format, keep_date_col, date_parser, dayfirst, cache_dates, iterator, chunksize, compression, thousands, decimal, lineterminator, quotechar, quoting, doublequote, escapechar, comment, encoding, dialect, error_bad_lines, warn_bad_lines, delim_whitespace, low_memory, memory_map, float_precision)
683 )
684
--> 685 return _read(filepath_or_buffer, kwds)
686
687 parser_f.__name__ = name
C:\ProgramData\Anaconda3\lib\site-packages\pandas\io\parsers.py in _read(filepath_or_buffer, kwds)
455
456 # Create the parser.
--> 457 parser = TextFileReader(fp_or_buf, **kwds)
458
459 if chunksize or iterator:
C:\ProgramData\Anaconda3\lib\site-packages\pandas\io\parsers.py in __init__(self, f, engine, **kwds)
893 self.options["has_index_names"] = kwds["has_index_names"]
894
--> 895 self._make_engine(self.engine)
896
897 def close(self):
C:\ProgramData\Anaconda3\lib\site-packages\pandas\io\parsers.py in _make_engine(self, engine)
1133 def _make_engine(self, engine="c"):
1134 if engine == "c":
-> 1135 self._engine = CParserWrapper(self.f, **self.options)
1136 else:
1137 if engine == "python":
C:\ProgramData\Anaconda3\lib\site-packages\pandas\io\parsers.py in __init__(self, src, **kwds)
1915 kwds["usecols"] = self.usecols
1916
-> 1917 self._reader = parsers.TextReader(src, **kwds)
1918 self.unnamed_cols = self._reader.unnamed_cols
1919
pandas\_libs\parsers.pyx in pandas._libs.parsers.TextReader.__cinit__()
pandas\_libs\parsers.pyx in pandas._libs.parsers.TextReader._get_header()
UnicodeDecodeError: 'gb2312' codec can't decode byte 0x93 in position 2: illegal multibyte sequence
目前对于中文而言,最常使用的有 utf-8 和 gb2312 两种格式,只需要指定正确的编码。在不知道编码的情况下,只需要尝试两次即可。padas默认的文件编码格式是 utf-8,所以如果出现以上错误,只需使用 encoding=gb2312 再尝试一下即可,如 pd.read_csv(file, encoding='gb2312')。
空值
空值是csv中也非常常见,比如以下内容:
import pandas as pd
df = pd.read_csv('people.csv')
v1=df['出生地'][3]
print(v1, type(v1))
输出为:
由此可见,空值也是有数据类型的,为 float 类型。
如何判断空值有两种方法,可以使用 math.isnan(x) 也可以使用 isinstance(float)。我们知道,DateFrame对象是包括Series对象,而在一个Series对象中,所有的数据类型默认是一样的,所以如果其数据类型推断为字符串(str),那么直接使用 math.isnan(x) 则会报错 TypeError: must be real number, not str 错误,即必需为实数,不能是字符串。所以,这时我们还需要使用 isinstance(x, flaot) 方法。
具体请看这个示例:
df.出生地=df.出生地.map(lambda x: '其他' if isinstance(x, float) else x)
df
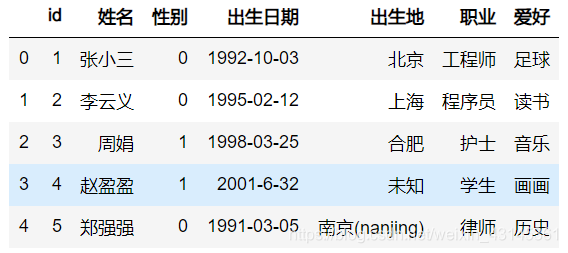
函数映射
方法1:直接使用labmda表达式
需要对数据列进行复杂操作的时候,我们可以使用以下函数时行相应的操作。
df=df.fillna('未知')
df.爱好=df.爱好.map(lambda x: x.split(' ')[0].split('-')[0].split(',')[0])
df
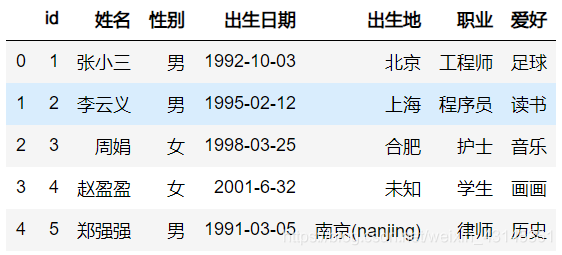
方法二:使用自定义函数
在进行映射时,如果操作比较简单,可以使用字典的方式进行数值映射映射(参见下文)。但是如果操作比较复杂,则需要使用函数进行映射。请看这个示例,读取到性别时,内容有 ‘m', ‘M', ‘Female' 等内容,现在需要其全部转换为 男 或 女:
def set_sex(s):
if s.lower() == 'm' or s.lower() == 'male':
return '男'
elif s.lower() == 'female':
return '女'
return s
df = pd.read_csv('people.csv', converters={'性别': lambda x : set_sex(x)})
df
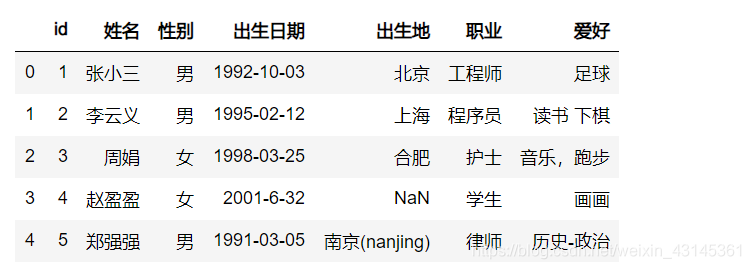
方法三:使用数值字典映射
在数据处理时,数值型往往比字符串效率更高,所以在可能的情况下,我们希望将数据转换成字符串处理。请看这个示例,将输入的数据的性别中的男性转换为1 女性转换为0。操作如下:
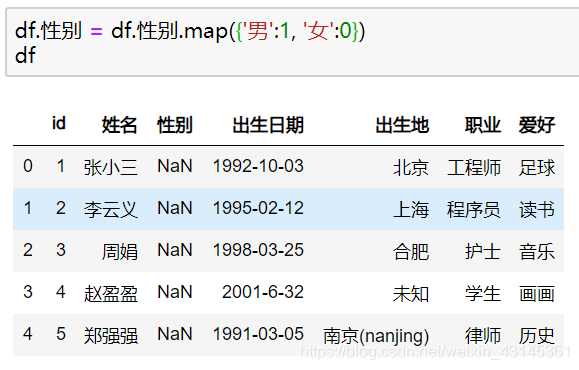
到此这篇关于使用Python pandas读取CSV文件应该注意什么?的文章就介绍到这了,更多相关pandas读取CSV文件内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
您可能感兴趣的文章:- Python Pandas分组聚合的实现方法
- python中pandas对多列进行分组统计的实现
- 详解python pandas 分组统计的方法
- Python Pandas实现数据分组求平均值并填充nan的示例
- Python学习笔记之pandas索引列、过滤、分组、求和功能示例
- Python Pandas的简单使用教程
- Python pandas入门系列之众数和分位数
- Python pandas求方差和标准差的方法实例
- python geopandas读取、创建shapefile文件的方法
- 利用python Pandas实现批量拆分Excel与合并Excel
- python pandas分组聚合详细


 咨 询 客 服
咨 询 客 服