如下:

将html文件下载后,使用BeauifulSoup读取文件,并且使用html.parser
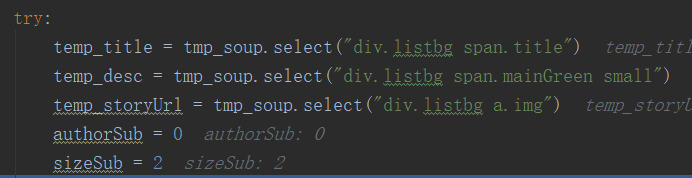
tmp_soup.select里面的参数为:
div标签中class中带有listbg 下面 span标签中带有title,这种意思:
并且他们的类型如下:
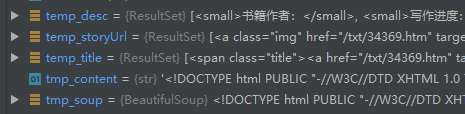
都是ResultSet类型。

可以通过下面这种方式获取,
find('某个标签')['中包含的域']
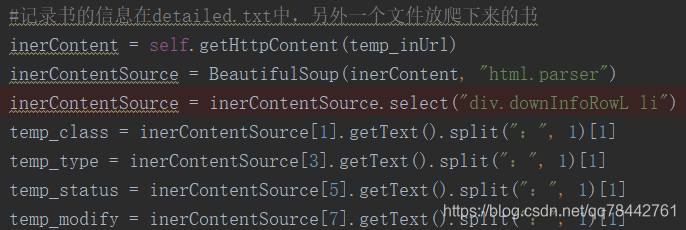
当为li标签的时候,可以通过这样的方式获取:
到此这篇关于Python BeautifulSoup基本用法(通过标签及class定位元素)的文章就介绍到这了,更多相关Python BeautifulSoup用法内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
您可能感兴趣的文章:- python beautiful soup库入门安装教程
- python爬虫学习笔记--BeautifulSoup4库的使用详解
- Python爬虫进阶之Beautiful Soup库详解
- python爬虫beautifulsoup库使用操作教程全解(python爬虫基础入门)
- python网络爬虫精解之Beautiful Soup的使用说明


 咨 询 客 服
咨 询 客 服