目录
- 前言
- 一、CNN解决了什么问题?
- 二、CNN网络的结构
- 2.1 卷积层 - 提取特征
- 卷积运算
- 权重共享
- 稀疏连接
- 总结:标准的卷积操作
- 卷积的意义
- 1x1卷积的重大意义
- 2.2 激活函数
- 2.3 池化层(下采样) - 数据降维,避免过拟合
- 2.4 全连接层 - 分类,输出结果
- 三、Pytorch实现LeNet网络
- 3.1 模型定义
- 3.2 模型训练(使用GPU训练)
- 3.3 训练和评估模型
前言
在学计算机视觉的这段时间里整理了不少的笔记,想着就把这些笔记再重新整理出来,然后写成Blog和大家一起分享。目前的计划如下(以下网络全部使用Pytorch搭建):
专题一:计算机视觉基础
- 介绍CNN网络(计算机视觉的基础)
- 浅谈VGG网络,介绍ResNet网络(网络特点是越来越深)
- 介绍GoogLeNet网络(网络特点是越来越宽)
- 介绍DenseNet网络(一个看似十分NB但是却实际上用得不多的网络)
- 整理期间还会分享一些自己正在参加的比赛的Baseline
专题二:GAN网络
- 搭建普通的GAN网络
- 卷积GAN
- 条件GAN
- 模式崩溃的问题及网络优化
以上会有相关代码实践,代码是基于Pytorch框架。话不多说,我们先进行专题一的第一部分介绍,卷积神经网络。
一、CNN解决了什么问题?
在CNN出现之前,对于图像的处理一直都是一个很大的问题,一方面因为图像处理的数据量太大,比如一张512 x 512的灰度图,它的输入参数就已经达到了252144个,更别说1024x1024x3之类的彩色图,这也导致了它的处理成本十分昂贵且效率极低。另一方面,图像在数字化的过程中很难保证原有的特征,这也导致了图像处理的准确率不高。
而CNN网络能够很好的解决以上两个问题。对于第一个问题,CNN网络它能够很好的将复杂的问题简单化,将大量的参数降维成少量的参数再做处理。也就是说,在大部分的场景下,我们使用降维不会影响结果。比如在日常生活中,我们用一张1024x1024x3表示鸟的彩色图和一张100x100x3表示鸟的彩色图,我们基本上都能够用肉眼辨别出这是一只鸟而不是一只狗。这也是卷积神经网络在图像分类里的一个重要应用。【ps:卷积神经网络可以对一张图片进行是猫还是狗进行分类。如果一张图片里有猫有狗有鸡,我们要分别识别出每个区域的动物,并用颜色分割出来,基础的CNN网络还能够使用吗?这是一个拓展思考,有兴趣的读者可以看一下FCN网络。对比之下能够更好的理解CNN网络】

对于第二个问题,CNN网络利用了类似视觉的方式保留了图像的特征,当图像做翻转、旋转或者变换位置的时候,它也能有效的识别出来是类似的图像。
以上两个问题的解决,都是由于CNN网络具有以下优势和特点:局部区域连接、权值共享。在解释这三个特点之前,我们先看一下CNN网络的三大主要结构,卷积层、池化层(或者叫做汇聚层)、全连接层。
二、CNN网络的结构
2.1 卷积层 - 提取特征
卷积运算
了解卷积层,我们先要了解一下卷积运算。别看它叫做卷积,但是和严格意义上的数学卷积是不同的。深度学习所谓的卷积运算是互相关( cross-correlation )运算。【实际上,经过数学证明发现无论用严格卷积或互相关运算,卷积层的输出不会受太大影响。而互相关运算比严格卷积运算简洁的多,所以我们一般都采用互相关运算来替代严格意义上的卷积运算。】我们以二维数据为例(高 x 宽),不考虑图像的通道个数,假设输入的高度为3、宽度为3的二维张量,卷积核的高度和宽度都是2,而卷积核窗口的形状由内核的高度和宽度决定:
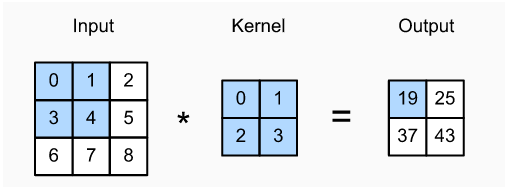
二维的互相关运算。阴影部分是第一个输出元素,以及用于计算这个输出的输入和核张量元素: 0 x 0 + 1x1 + 3x2 +4x3 = 19。由此可见互相关运算就是一个乘积求和的过程。在二维互相关运算中,卷积窗口从输入张量的左上角开始,从左到右、从上到下滑动。这里我们设置步长为1,即每次跨越一个距离。当卷积窗口滑到新一个位置时,包含在该窗口中的部分张量与卷积核张量进行按元素相乘,得到的张量再求和得到一个单一的标量值,由此我们得到了这一位置的输出张量值。 【我们这里频繁提到了张量,张量(Tensor)是一个多维数组,它是标量、向量、矩阵的高维拓展。】
看了上面的内容,可能有读者开始思考,如果这个输入矩阵是 4x4,卷积核是3x3,步长为1的时候,在向右移动时,我们发现如果要和卷积核进行卷积操作,左便的输入矩阵还缺少了一列;在行的方向也是如此。如果我们忽略边缘的像素,我们可能就丢失了边缘的细节。那么这种情况下我们如何处理呢?这时我们可以进行填充操作(padding),在用pytorch实现时我们可以在Convd函数中对padding进行设置,这里我们可以设置padding=1,就能够在行和列上向外扩充一圈。【ps:实际上当处理比较大的图片,且任务是分类任务时,我们可以不用进行padding。因为对于大部分的图像分类任务,边缘的细节是是无关紧要的,且边缘的像素点相比于总的像素来讲,占比是很小的,对于整个图像分类的任务结果影响不大】
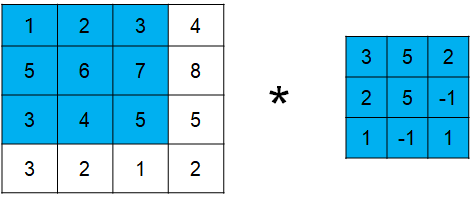
对于卷积操作,我们有一个统一的计算公式。且学会相关的计算对于了解感受野和网络的搭建至关重要。学会相关的计算,我们在搭建自己的网络或者复现别人的网络,才能够确定好填充padding、步长stride以及卷积核kernel size的参数大小。一般这里有一个统一的公式:
假设图像的尺寸是 input x input,卷积核的大小是kernel,填充值为padding,步长为stride,卷积后输出的尺寸为output x output,则卷积后,尺寸的计算公式为:

ps:如果输入的图像尺寸是 mxn类型的,可以通过裁剪 or 插值转换成 mxm or nxn类型的图像;或者分别计算图像的高和宽大小也可以,公式都是类似的。
权重共享
我们在前面有提到过CNN网络的一个特性是权重共享(share weights)也正是体现在通道处理的过程中。一般的神经网络层与层之间的连接是,每个神经元与上一层的全部神经元连接,这些连接线的权重独立于其他的神经元,所以假设上一层是m个神经元,当前层是n个神经元,那么共有mxn个连接,也就有mxn个权重。权重矩阵是mxn的形式。那么CNN是如何呢?权重共享是什么意思?我们引入下面这样一张图来帮助我们理解:
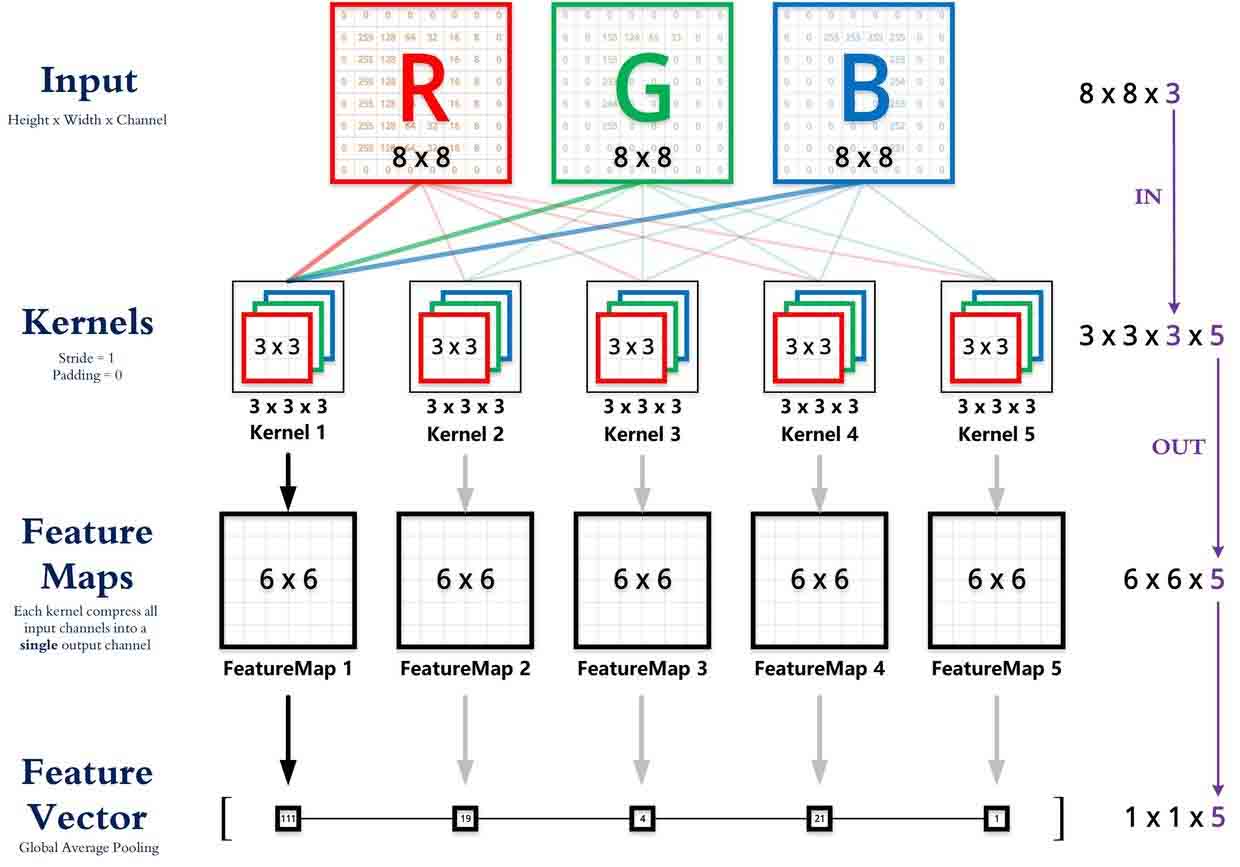
我们先说明上图中各个模块的矩阵格式及关系:
- 输入矩阵格式:(样本数,图像高度,图像宽度,图像通道数)
- 输出矩阵格式:(样本数,图像高度、图像宽度、图像通道数)
- 卷积核的格式:(卷积核高度、卷积核宽度、输入通道数、输出通道数)
- 卷积核的输入通道数(in depth)由输入矩阵的通道数所决定。(红色标注)
- 输出矩阵的通道数(out depth)由卷积核的输出通道所决定。(绿色标注)
- 输出矩阵的高度和宽度,由输入矩阵、卷积核大小、步长、填充共同决定,具体计算公式见上文。
当输入一张大小为8x8x3的彩色图时,我们已经提前设计好了卷积核后的输出通道为5,即卷积核的个数为5【即五个偏置,一个卷积核一个偏置】(通道数的设计一般是实验后得到的较优结果)。每个卷积核去和输入图像在通道上一一对应进行卷积操作(即互相关操作,除非刻意强调,这里所说的卷积都是互相关,步长为1,填充为0),得到了3个6x6的feature map。然后再将三个6x6的Feature map按照Eletwise相加进行通道融合得到最终的feature map,大小为6x6(也就是将得到的三个矩阵逐元素相加,之后所有元素再加上该矩阵的偏置值,得到新的6x6矩阵)。权重共享也是体现在这个过程中。我们单独提取出第一个卷积核,当它的第一个通道(3x3)与输入图像的第一个通道(8x8)进行卷积操作时,按照普通的神经网络连接方式其权重矩阵是9 x 81。但是这里我们要注意,我们在窗口滑动进行卷积的操作权重是确定的,都是以输入图像的第一个通道为模板,卷积核的第一个通道3x3矩阵为权重值,然后得到卷积结果。这个过程中权重矩阵就是3x3,且多次应用于每次计算中。权重的个数有9x81减少到3x3,极大的减少了参数的数量。综合起来,对于第一个卷积核来讲,它的权重矩阵就是3x3x3+1,整个卷积过程的权重大小为3x3x3x5+5,而不是8x8x3x3x3x3x5。权重共享大大减少了模型的训练参数。权重共享意味着当前隐藏层中的所有神经元都在检测图像不同位置处的同一个特征,即检测特征相同。因此也将输入层到隐藏层的这种映射称为特征映射。由上我们可以理解,从某种意义上来说,通道就是某种意义上的特征图。输出的同一张特征图上的所有元素共享一个卷积核,即共享一个权重。通道中某一处(特征图上某一个神经元)数值的大小就是当前位置对当前特征强弱的反应。而为什么在CNN网络中我们会增加通道数目,其实就是在增加通道的过程中区学习图像的多个不同特征。
稀疏连接
通过上面对于卷积的过程以及权重共享的解释,我们能够总结出CNN的另一个特征。有心的读者其实能够自己总结出来。我们在上面提到过,对于普通的神经网络,隐藏层和输入层之间的神经元是采用全连接的方式。然而CNN网络并不是如此。它的在局部区域创建连接,即稀疏连接。比如,对于一张输入的单通道的8x8图片,我们用3x3的卷积核和他进行卷积,卷积核中的每个元素的值是和8x8矩阵中选取了3x3的矩阵做卷积运算,然后通过滑动窗口的方式,卷积核中的每个元素(也就是神经元)只与上一层的所有神经元中的9个进行连接。相比于神经元之间的全连接方式,稀疏连接极大程度上的减少了参数的数量,同时也一定程度上避免了模型的过拟合。这种算法的灵感是来自动物视觉的皮层结构,其指的是动物视觉的神经元在感知外界物体的过程中起作用的只有一部分神经元。在计算机视觉中,像素之间的相关性与像素之间的距离同样相关,距离较近的像素间相关性强,距离较远则相关性比较弱,由此可见局部相关性理论也适用于计算机视觉的图像处理。因此,局部感知(稀疏连接)采用部分神经元接受图像信息,再通过综合全部的图像信息达到增强图像信息的目的。(至于我们为什么现在经常采用3x3卷积核,因为实验结果告诉我们,3x3卷积核常常能达到更好的实验效果。)
总结:标准的卷积操作
在进行上面的解释后,相信大家已经对于什么是卷积,卷积的两点特点:稀疏链接和权重共享已经有了了解。下面我们来总结一般意义的标准的卷积操作:当输入的feature map数量(即输入的通道数)是N,卷积层filter(卷积核)个数是M时,则M个filter中,每一个filter都有N个channel,都要分别和输入的N个通道做卷积,得到N个特征图,然后将这N个feature map按Eletwise相加(即:进行通道融合),再加上该filter对应的偏置(一个filter对应一个共享偏置),作为该卷积核所得的特征图。同理,对其他M-1个filter也进行以上操作。所以最终该层的输出为M个feature map(即:输出channel等于filter的个数)。可见,输出的同一张特征图上的所有元素共享同一个卷积核,即共享一个权重。不同特征图对应的卷积核不同。
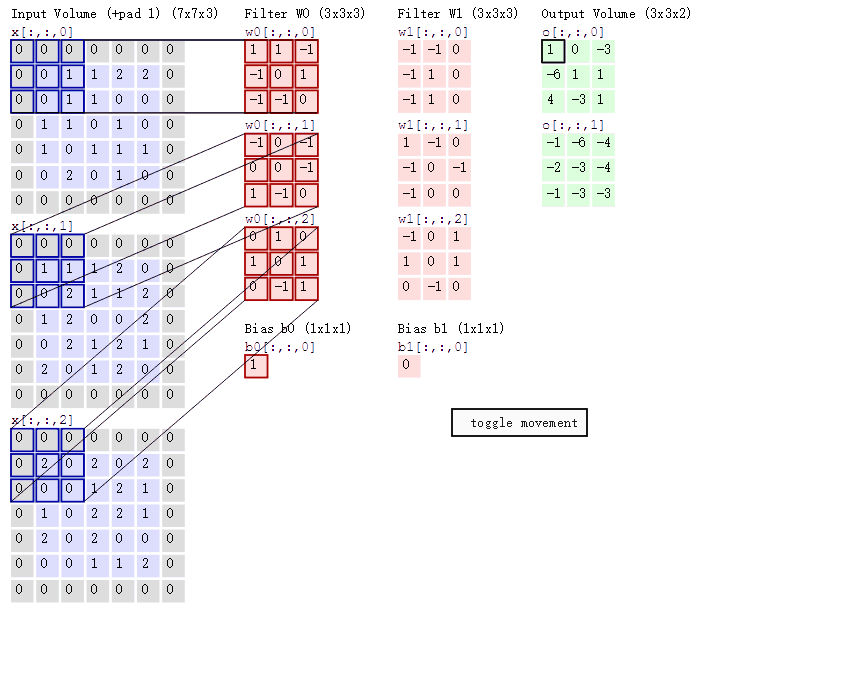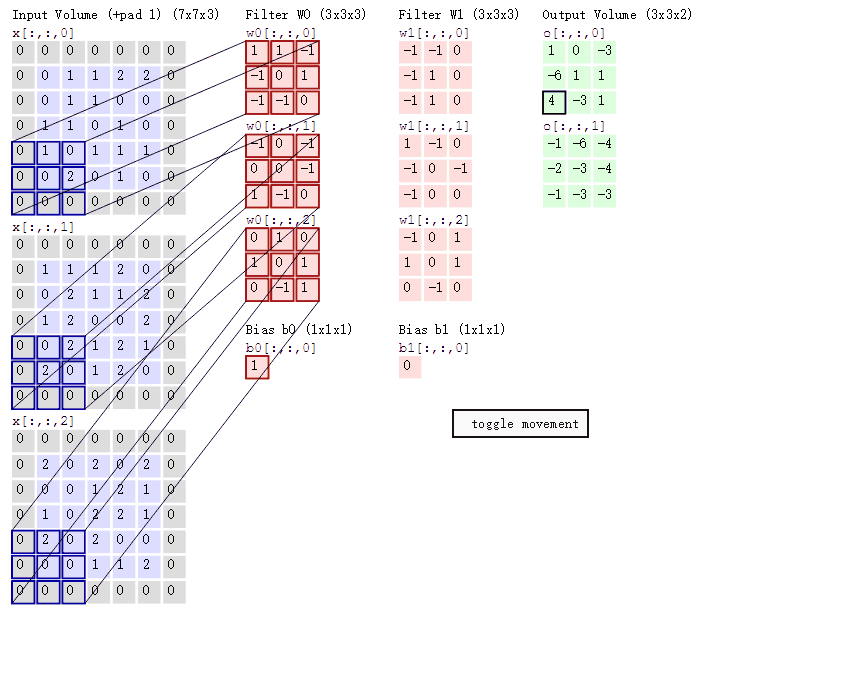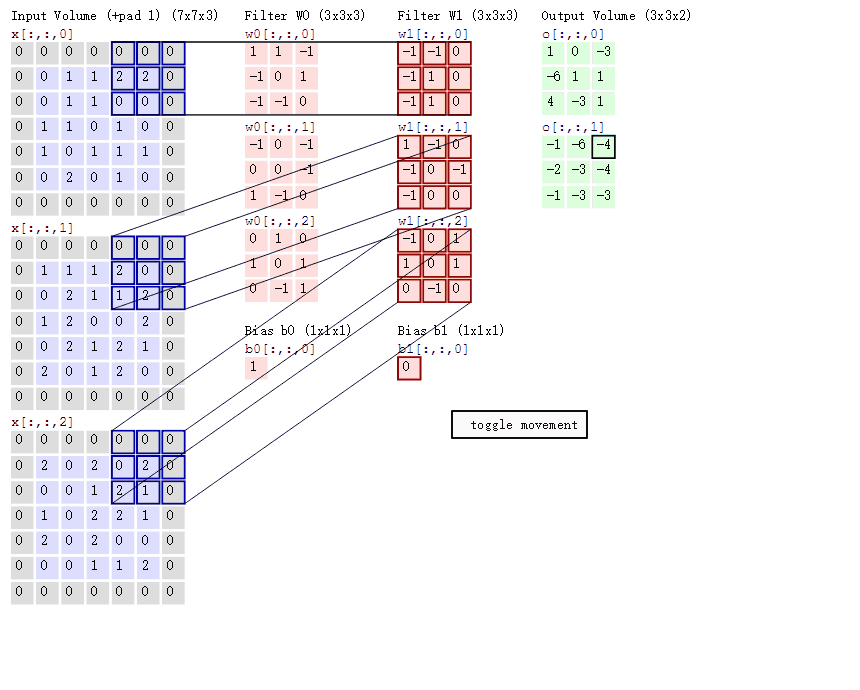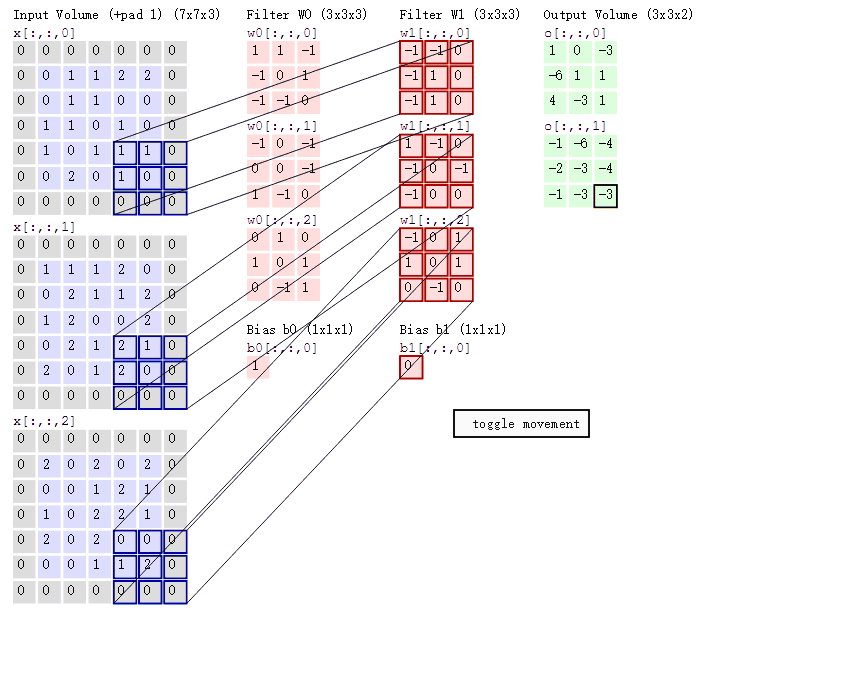
卷积的意义
如果用图像处理上的专业术语,我们可以将卷积叫做锐化。卷积其实是想要强调某些特征,然后将特征强化后提取出来,不同卷积核关注图片上不同的特征,比如有的更关注边缘而有的更关注中心地带等。当完成几个卷积层后(卷积 + 激活函数 + 池化)【后面讲解激活函数和池化】,如图所示:
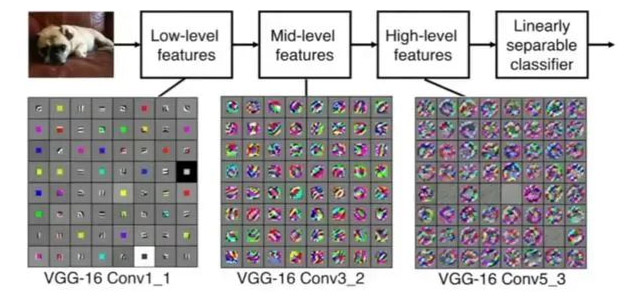
在CNN中,我们就是通过不断的改变卷积核矩阵的值来关注不同的细节,提取不同的特征。也就是说,在我们初始化卷积核的矩阵值(即权重参数)后,我们通过梯度下降不断降低loss来获得最好的权重参数,整个过程都是自动调整的。
1x1卷积的重大意义
按照道理讲,我是不该这么快就引入1x1卷积的,不过考虑到它在各种网络中应用的重要性并且也不难理解,就在这里提前和大家解释一下1x1卷积是什么,作用是什么。
如果有读者在理解完上文所提到的卷积后,可能会发出疑问:卷积的本质不是有效的提取相邻像素间的相关特征吗?1x1卷积核的每个通道和上一层的通道进行卷积操作的时候不是没法识别相邻元素了吗?
其实不然,1x1卷积层的确是在高度和宽度的维度上失去了识别相邻元素间的相互作用的能力,并且通过1x1卷积核后的输出结果的高和宽与上一层的高和宽是相同的。但是,通道数目可能是不同的。而1x1卷积的唯一计算也正是发生在通道上。它通过改变1x1卷积核的数量,实现了多通道的线性叠加,使得不同的feature map进行线性叠加。我们通过下图来更好的认识1x1卷积的作用:

上图使用了2个通道的1x1卷积核与3个通道的3x3输入矩阵进行卷积操作。由图可知,这里的输入和输出具有相同的高度和宽度,输出的每个元素都是从输入图像的同一位置的元素的线性组合。我们可以将1x1卷积层看做是每个像素位置应用的全连接层。同时,我们发现输出结果的通道数目发生了改变,这也是1x1卷积的一个重要应用。可以对输出通道进行升维或者降维,并且不改变图像尺寸的大小,有利于跨通道的信息交流的内涵。降维之后我们可以使得参数数量变得更少,训练更快,内存占用也会更少。如果是在GPU上训练,显存就更加珍贵了。
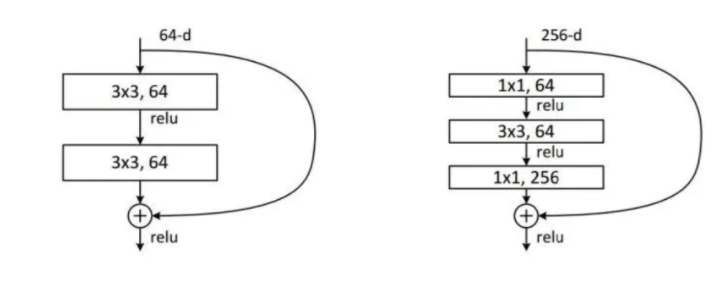
卷积网络的一个非常重要的应用就是ResNet网络,而ResNet网络结构,已经应用于各种大型网络中,可以说是随处可见。这里先贴个ResNet中应用了1x1卷积的残差块,后面会有一篇文章来解读ResNet网络:ResNet paper download
2.2 激活函数
由前述可知,在CNN中,卷积操作只是加权求和的线性操作。若神经网络中只用卷积层,那么无论有多少层,输出都是输入的线性组合,网络的表达能力有限,无法学习到非线性函数。因此CNN引入激活函数,激活函数是个非线性函数,常用于卷积层和全连接层输出的每个神经元,给神经元引入了非线性因素,使网络的表达能力更强,几乎可以逼近任意函数,这样的神经网络就可应用到众多的非线性模型中,我们可以用公式来定义隐藏层的每个神经元输出公式:

其中,\(b_l\)是该感知与连接的共享偏置,Wl是个nxn的共享权重矩阵, 代表在输入层的nxn的矩形区域的特征值。
代表在输入层的nxn的矩形区域的特征值。
当激活函数作用于卷积层的输出时:

这里的σ是神经元的激励函数,可以是Sigmoid、tanh、ReLU等函数。
2.3 池化层(下采样) - 数据降维,避免过拟合
在CNN中,池化层通常在卷积或者激励函数的后面,池化的方式有两种,全最大池化或者平均池化,池化主要有三个作用:
- 一是降低卷积层对目标位置的敏感度,即实现局部平移不变性,当输入有一定的平移时,经过池化后输出不会发生改变。CNN通过引入池化,使得其特征提取不会因为目标位置变化而受到较大的影响。
- 二是降低对空间降采样表示的敏感性
- 三是能够对其进行降维压缩,以加快运算速度 ,防止过拟合。
与卷积层类似的是,池化层运算符有一个固定的窗口组成,该窗口也是根据步幅大小在输入的所有区域上滑动,为固定的形状窗口遍历每个位置计算一个输出。
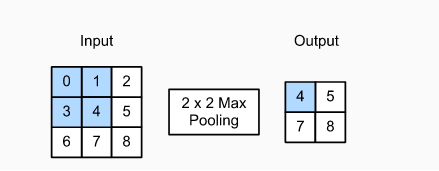
输出的张量高度为2,宽度为2,这四个元素为每个池化窗口中的最大值(stride=1,padding=0):
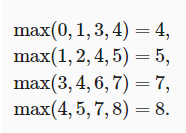
但是,不同于卷积层中的输入与卷积核之间的互相关计算,池化层不包含参数。池化层的运算符是确定性的,我们通常计算池化窗口中所有元素的最大值或平均值(些操作分别被称为最大池化层和平均池化层),而不是像卷积层那样将各通道的输入在互相关操作后进行eletwise特征融合,这也意味着池化层的输出通道数和输入通道数目是相同的。池化操作的计算一般形式为,设输入图像尺寸为WxHxC,宽x高x深度,卷积核的尺寸为FxF,S:步长,则池化后图像的大小为:

2.4 全连接层 - 分类,输出结果
我们刚给讲了卷积层、池化层和激活函数,这些在全连接层之前层的作用都是将原始数据映射到隐层特征空间来提取特征,而全连接层的作用就是将学习到的特征表示映射到样本的标记空间。换句话说,就是把特征正和岛一起(高度提纯特征),方便交给最后的分类器或者回归。
我们也可以把全连接层的过程看做一个卷积过程,例如某个网络在经过卷积、ReLU激活后得到3x3x5的输出,然后经过全连接层转换成1x4096的形式:


从上图我们可以看出,我们用一个3x3x5的filter去卷积激活函数的输出,得到的结果是全连接层的一个神经元,因为我们有4096个神经元,我们实际上就是用一个3x3x5x4096的卷积层去卷积激活函数的输出【不带偏置】。因此全连接层中的每个神经元都可以看成一个不带偏置加权平均的多项式,我们可以简单写成 。
。
这一步卷积还有一个非常重要的作用,就是把分布式特征representation映射到样本标记空间,简单说就是把特征整合到一起,输出为一个值,这样可以大大减少特征位置对分类带来的影响。
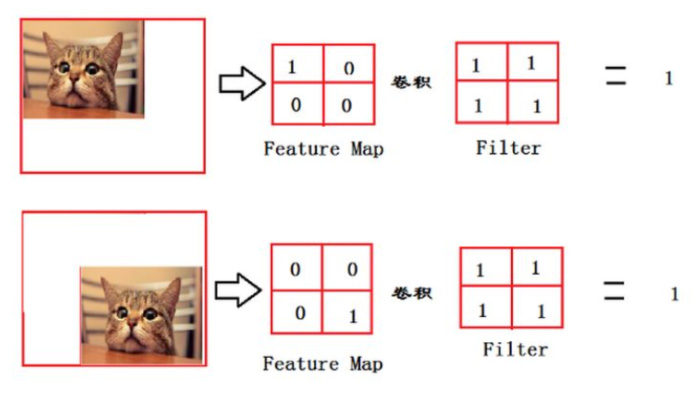
从上面的图,我们可以看出,猫在不同的位置,输出的特征值相同,但是位置不同;对于电脑来说,特征值相同,但是特征值位置不同,那分类结果可能是不一样的。此时全连接层的作用就是,在展平后忽略其空间结构特性,不管它在哪儿,只要它有这个猫,那么就能判别它是猫。这也说明了它是一个跟全局图像的问题有关的问题(例如:图像是否包含一只猫呢)。这也说明了全连接层的结构不适合用于在方位上找patter的任务,例如分割任务(后面的FCN就是将全连接层改成了卷积层)。不过全连接层有一个很大的缺点,就是参数过于多。所以后面的像ResNet网络、GoogLeNet都已经采用全局平均池化取代全连接层来融合学到的特征。另外,参数多了也引发了另外一个问题,模型复杂度提升,学习能力太好容易造成过拟合。
三、Pytorch实现LeNet网络
LeNet模型是最早发布的卷积神经网络之一,它是由ATT贝尔实验室的研究院Yann LeCun在1989年提出的,目的是识别图像中的手写数字,发表了第一篇通过反向传播成功训练卷积神经网络的研究。我们现在通过pytorch来实现:LeNet - Paper Download 。
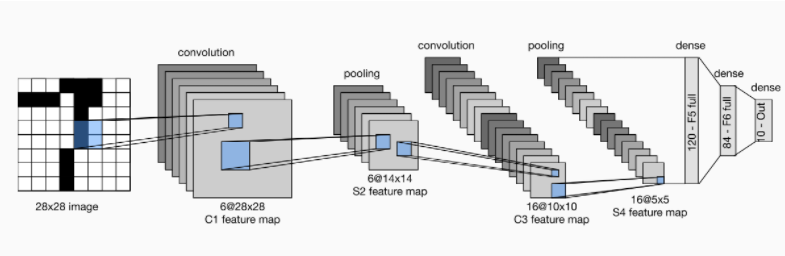
LeNet它虽然很小,但是包含了深度学习的基本模块。我们先对LeNet结构进行一个具体的分析,这也是我们搭建任何一个神经网络之前要提前知道的:
每个卷积块中的基本单元是一个卷积层、一个Sigmod激活函数和平均池化层。(虽然ReLU函数和最大池化层很有效,但是当时还没有出现)。每个卷积层使用5x5卷积核和一个Sigmoid激活函数。第一个卷积层有6个输出通道,第二个卷积层有16个输出通道。每个2x2赤化操作通过空间下采样将维数减少4倍。卷积的输出形状由(批量大小,通道数,高度,宽度)决定。LeNet中有三个全连接层,分别有120、84、10个输出,因为我们在执行手写数字的分类任务(一共有0-9共10个数字),所以输出层的10维对应于最后输出的结果的数量。
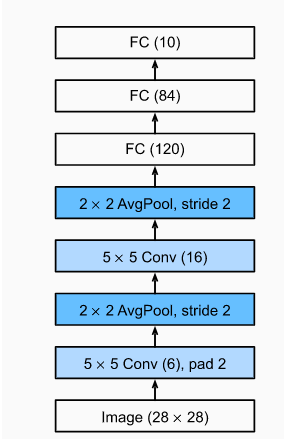
把上面的模型简化一下,网络结构大概就是这个样子:
3.1 模型定义
import torch
from torch import nn
from d2l import torch as d2l
class Reshape(torch.nn.Module):
def forward(self, x):
# 通过view函数把图像展成标准的Tensor接收格式,即(样本数量,通道数,高,宽)
return x.view(-1, 1, 28, 28)
net = torch.nn.Sequential(
Reshape(),
# 第一个卷积块,这里用到了padding=2
nn.Conv2d(1, 6, kernel_size=5, padding=2),
nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2),
# 第二个卷积块
nn.Conv2d(6, 16, kernel_size=5),
nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2),
# 稠密块(三个全连接层)
nn.Flatten(),
nn.Linear(16 * 5 * 5, 120), nn.Sigmoid(),
nn.Linear(120, 84), nn.Sigmoid(),
nn.Linear(84, 10))
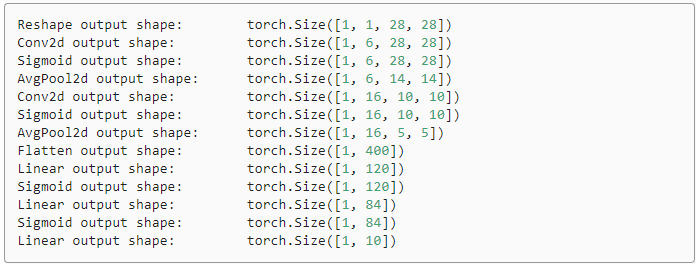
X = torch.rand(size=(1, 1, 28, 28), dtype=torch.float32)
for layer in net:
X = layer(X)
print(layer.__class__.__name__,'output shape: \t',X.shape)
输出结果为:
3.2 模型训练(使用GPU训练)
我们用LeNet在Fashion-MNIST数据集上测试模型表现结果:
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size=batch_size)
def evaluate_accuracy_gpu(net, data_iter, device=None): #@save
"""使用GPU计算模型在数据集上的精度。"""
if isinstance(net, torch.nn.Module):
net.eval() # 设置为评估模式
if not device:
device = next(iter(net.parameters())).device
# 正确预测的数量,总预测的数量
metric = d2l.Accumulator(2)
for X, y in data_iter:
if isinstance(X, list):
X = [x.to(device) for x in X]
else:
X = X.to(device)
y = y.to(device)
metric.add(d2l.accuracy(net(X), y), y.numel())
return metric[0] / metric[1]
#@save
def train_ch6(net, train_iter, test_iter, num_epochs, lr, device):
"""用GPU训练模型。"""
def init_weights(m):
if type(m) == nn.Linear or type(m) == nn.Conv2d:
nn.init.xavier_uniform_(m.weight)
net.apply(init_weights)
print('training on', device)
net.to(device)
optimizer = torch.optim.SGD(net.parameters(), lr=lr)
loss = nn.CrossEntropyLoss()
animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs],
legend=['train loss', 'train acc', 'test acc'])
timer, num_batches = d2l.Timer(), len(train_iter)
for epoch in range(num_epochs):
# 训练损失之和,训练准确率之和,范例数
metric = d2l.Accumulator(3)
net.train()
for i, (X, y) in enumerate(train_iter):
timer.start()
optimizer.zero_grad()
X, y = X.to(device), y.to(device)
y_hat = net(X)
l = loss(y_hat, y)
l.backward()
optimizer.step()
with torch.no_grad():
metric.add(l * X.shape[0], d2l.accuracy(y_hat, y), X.shape[0])
timer.stop()
train_l = metric[0] / metric[2]
train_acc = metric[1] / metric[2]
if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:
animator.add(epoch + (i + 1) / num_batches,
(train_l, train_acc, None))
test_acc = evaluate_accuracy_gpu(net, test_iter)
animator.add(epoch + 1, (None, None, test_acc))
print(f'loss {train_l:.3f}, train acc {train_acc:.3f}, '
f'test acc {test_acc:.3f}')
print(f'{metric[2] * num_epochs / timer.sum():.1f} examples/sec '
f'on {str(device)}')
3.3 训练和评估模型
lr, num_epochs = 0.9, 10
train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
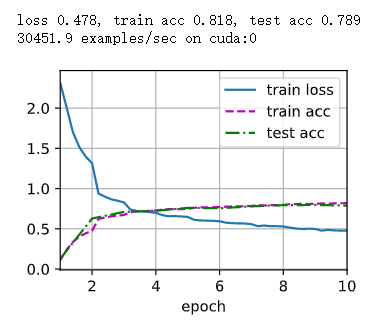
这个是我的训练结果,大概就酱紫,结束了结束了,累死我了。
到此这篇关于一文带你了解CNN(卷积神经网络)的文章就介绍到这了,更多相关CNN(卷积神经网络)内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
您可能感兴趣的文章:- Numpy实现卷积神经网络(CNN)的示例
- 使用卷积神经网络(CNN)做人脸识别的示例代码
- PyTorch上实现卷积神经网络CNN的方法
- TensorFlow深度学习之卷积神经网络CNN
- TensorFlow实现卷积神经网络CNN


 咨 询 客 服
咨 询 客 服


 代表在输入层的nxn的矩形区域的特征值。
代表在输入层的nxn的矩形区域的特征值。


 。
。