场景描述:语音合成解决的主要问题就是如何将文字信息转化为可听的声音信息,涉及语言和语音两部分。TTS技术(又称文语转换技术)隶属于语音合成,它是将计算机自己产生的、或外部输入的文字信息转变为可以听得懂的、流利的汉语口语输出的技术。
关键词:多语言语音合成和跨语言语音克隆
我们知道目前端到端神经TTS模型已经可以实现对说话者身份和未标记的语音属性(如韵律)的控制。当使用language-dependent输入表示或模型组件时,特别是当每种语言的训练数据量不平衡时,扩展这些模型以支持多种不相关的语言并非易事。例如,在汉语和英语等语言之间的文本表示没有重叠。此外,收集双语者的录音也很昂贵。因此,最常见的情况是训练集中的每个说话者只说一种语言,所以说话者的身份与语言是完全相关的。这使得在不同语言之间语音转换变得困难。此外,对于外来词或共享词的语言,如西班牙语(ES)和英语(EN)中的专有名词,同一文本的发音可能不同。当经过简单训练的模型有时为特定的说话者生成重音时,这就更加难以捉摸。
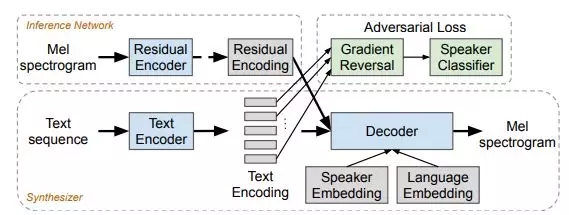
针对以上问题,最近学者们提出了一种基于Tacotron(中文语音合成)的多人多种语言文本到语音(TTS)的合成算法。
这种算法能够在多种语言中生成高质量的语音。此外,模型是能够跨语言传递声音。模型结构采用基于注意力机制的序列到序列模型,根据输入文本序列生成倒谱梅频(log-mel,来自MFCC梅尔频率倒谱系数)图帧序列。
该模型是通过使用音位输入表示来设计的,以激励跨语言的模型容量共享。它还包含了一个对抗性的损失,以帮助理清它的说话者表示。通过对每种语言的多名使用者进行训练,加入自动编码输入,并在训练期间来帮助稳定注意力,从而进一步扩大了训练规模。
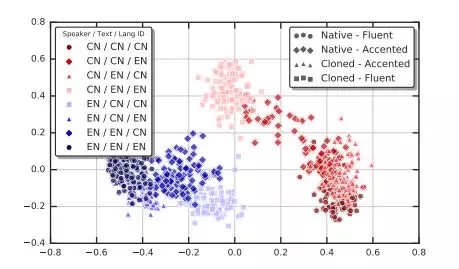
经过计算,实现了语音克隆和重音控制效果的可视化。嵌入向量集群聚在一起(左下角和右下角),这意味着当说话者的原始语言与嵌入的语言匹配时,无论文本语言是什么,都会有很高的相似性。然而,使用文本中的语言ID(正方形),修改说话者的口音使其能够流利地说话,与母语和口音(圆形)相比,会损害相似性。
该模型对三种语言的高质量语音合成和语音训练的跨语言传输具有重要的应用潜力。例如,不需要任何双语或并行语言的训练,它就能够使用英语使用者的声音合成流利的西班牙语。此外,该模型在学习说外语的同时还会适量调节口音,并对代码切换有基本的支持。
在未来的工作中,学者们还将计划研究扩大利用大量低质量培训数据的方法,并支持更多的使用者和语言。
论文链接:https://arxiv.org/pdf/1907.04448.pdf


 咨 询 客 服
咨 询 客 服