呼叫中心的核心价值是连接人与服务。随着互联网对传统行业改造的深化,派生出很多线上、线下互动的应用场景,例如:订餐、订外卖、订酒店等。而线上线下信息链结合最简单、最高效的工具莫过于电话。因此,呼叫中心也从原来仅仅提供客户服务和营销服务,演变为与企业业务流程深度结合,全方位实现企业与客户沟通的工具。天润融通的云呼叫中心作为一个开放的呼叫中心能力平台,使得企业只需要使用非常简单的API或SDK即可轻松实现低成本、高可靠的语音服务。
开放化的语音平台结合场景化的应用,使得云呼叫中心平台对容量和稳定性提出了更大的要求。如何满足客户弹性业务需求,应对业务时段峰值?下面就以某订餐业务模型为例,探讨下云呼叫中心架构该如何应对?
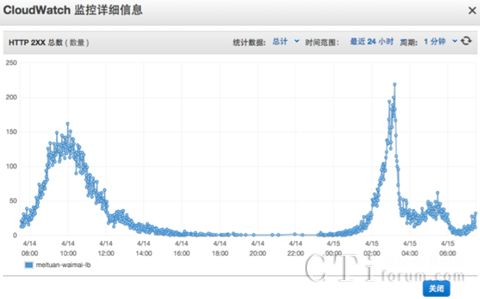
某外卖业务模型
某外卖业务流量图
每天中午11:00-12:30,晚上17:00-19:00订餐业务高峰,极不均衡
设计原则
在智能云呼叫中心平台设计之初,我们根据平台客户的业务需求特点,对平台架构设计确认了如下几点原则:
1.平台架构应基于开放成熟的云IaaS服务;
2.在云端进行架构设计时要保持悲观,假设所有事物都会发生故障。换句话来说,架构需要面向故障的自动化恢复来设计,实施和部署。平台任何模块必须是HA架构,消除单点模块;
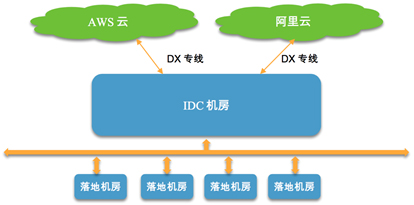
3.应用云IaaS服务与IDC机房由DX专线组成混合架构云;
4.分布式架构,必须非常容易扩容,支持自动弹性伸缩;
5.平台中模块之间的关系降低耦合,便于业务的快速演进;
6.以业务监控、日志和统计为运营核心构建平台;
7.具备跨机房级别的高可用结构;
8.完善的完全机制,自我保护与服务降级能力;
实践之路
凭借“云中优势”进行系统组网。
基于云平台的架构在组网结构上具备明显的商业优势。体现在几乎为零的启动成本,灵活的资源按需付费模式,快速的扩容上线能力等方面。
在技术层面云平台架构也存在明显优势。可实现自动化构建和部署,自动扩展无需人工干预,可将测试持续注入到开发过程各个阶段,实现改进的可预测性。
天润融通智能云呼叫中心平台,基于AWS云/阿里云+DX直连IDC组建的混合架构云,既能利用云平台的“云中优势”又能兼容特殊应用让平台的运行上线无缝切换。在网络架构上,将核心机房和落地机房通过专线打通,形成环线。其中任何一点的专线故障都可以通过整体的网络调度,由其他专线或互联网进行切换传送,从而不影响业务的正常运转。
高可用的组网结构图
在基础IaaS云服务上构建大容量高可用的系统。
在基础IaaS云服务方面,AWS与阿里云差别不大,以下仅以AWS为例说明如何在基础IaaS服务之上构建大容量高可用的系统。
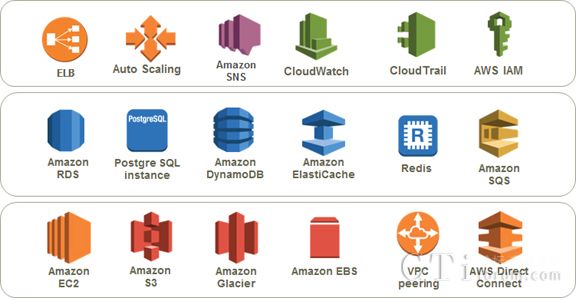
目前智能云呼叫中心平台架构基于AWS所提供的3层基础服务:
AWS云平台组件服务
第一层。 基础计算、存储和网络组件,包括EC2,S3,EBS,VPC和DX等等。其中S3服务由AWS提供11个9的持久性,DX专线采用2条互为备份的1G直连保证了网络性能。
第二层。高可用的数据库RDS,Cache,SNS和SQS应用组件,支持跨机房的高可用和可灵活扩容。实时处理部分全部使用Rediscache降低数据库压力,大量使用SQS做异步化处理实现削峰填谷。
第三层。应用层的ELB负载均衡器,AutoScaling弹性伸缩,以及完善的监控和日志服务。系统各模块首先全部是无状态的,AutoScaling的应用使得通过ELB收集采样来的当前负载和伸缩策略相结合,能够动态调整EC2的实例个数,当业务高峰时启动大量实例承接业务,而低谷时减小实例降低成本。
在平台架构设计中必须意识到,故障和故障切换是作为系统架构的一部分存在的。通过AWS/阿里云等云环境提供的容错架构,大大降低了系统运维方面的复杂性,实际上这部分架构是由云环境完成了。与基础硬件故障设计一样,平台软件方面也必须进行故障切换的架构设计,比如:如果一个模块down掉,平台上的应用怎么办?如果接口请求超时或异常怎么处理?如果突发请求超过系统容量又怎么办?
我们的经验是基于SOA面向服务的架构理念,构建组件之间的关键是减小组件之间的依赖。如果一个组件挂了没有响应或响应时间过长,系统中其他组件应该能继续工作。组件之间尽量相互独立,通过异步交互方式使用消息队列设计组件间的接口。这样即使某些功能暂时不能用,整个系统仍然继续运行,当出问题的组件恢复后仍然可以使用消息队列中的数据恢复运行状态。
基于SOA面向服务的架构理念,我们解耦和拆分构建了大量的生态子系统,系统之间通过API调用构建完整的功能生态链,比如NOSS网管中心,BOSS营帐中心,NMC码号中心,TTS-proxy语音合成中心,SMSC短信平台等等,整体架构如下图所示意:
整体架构图
除了整体生态系统层面做了解耦和面向微服务架构的拆分工作,智能云呼叫中心核心交换平台也进行了大量微模块拆分。共计拆分了25个子系统,其中主要的子系统如下:
| 模块名 |
用途 |
支持集群 |
主要协议 |
| sip-media-server |
核心交换服务 |
支持 |
SIP/RTP |
| sip-proxy |
核心调度服务 |
支持 |
SIP/TCP |
| Webrtc-gateway |
Webrtc接入网关 |
支持 |
SIP/Websocket |
| realtime |
运行时实时数据服务 |
支持 |
HTTP |
| cdr |
话单采集和处理服务 |
支持 |
HTTP |
| webcall |
Webcall接口模块 |
支持 |
HTTP |
| PredictDialer |
预测外呼模块 |
支持 |
HTTP |
| ASR |
智能语音转写模块 |
支持 |
HTTP |
| conf-api |
配置接口服务 |
支持 |
HTTP |
| data-api |
业务数据接口 |
支持 |
HTTP |
| control-api |
控制接口服务 |
支持 |
HTTP |
| task-engine |
任务引擎服务 |
支持 |
HTTP |
| agent-gateway |
坐席管理模块 |
支持 |
Websocket/Redis |
| big-queue |
统一排队服务 |
支持 |
HTTP |
上述子系统,全部实现了无状态逻辑,用集群堆叠的方式实现高可用和高性能。架构实现要点有:
1.对上层提供统一的接口服务,接口服务版本可灵活扩展;
2.ConfDB和CacheDB完全分离,实时业务不依赖于配置库,只使用高性能缓存库;
3.将超大量数据存储和运行时数据存储完全分离,使用云环境对象存储和nosql数据库实现海量数据的存储和处理;
4.AutoScaling弹性伸缩时实例自举,实例向控制服务询问:“我是谁?我该干什么?”尽量减少人为部署失误,创建一个自愈环境;
5.使用开源dubbo自动管理服务;
6.要有完整的监控服务。
核心交换平台模块架构图
云服务的安全机制
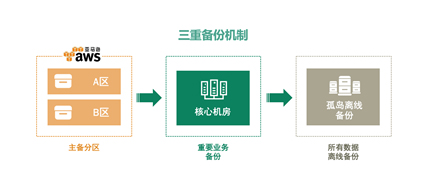
云时代所面临的安全问题极其重要。天润融通智能云呼叫中心平台的架构设计准备了三重备份机制:第一基于AWS云平台。首先在AWSA/B机房实现双活的数据中心;第二将业务数据在核心机房进行热备,一旦AWS云服务出现全局问题立刻切换业务到核心机房保持业务持续服务;第三将数据进行孤岛离线冷备份,确保数据可恢复。
在安全架构上,除了技术上防范比如sql注入,web漏洞,暴力破解等,还采用一系列安全架构提供安全保障,包括对外的入侵检测系统、WAF防护、网络防火墙,和对内的账号权限管理审计等。
实践成果
天润融通大容量高可用的呼叫中心平台架构,使云呼叫中心在性能上可以有能力比肩,甚至超过原有的以硬件为核心的呼叫中心系统,彻底打破了人们对曾经云呼叫中心只能做小客户的固有印象。具体实践成果如下:
1、解决大容量并发问题。
基本指标包括:呼叫并发能力超过10000线;并发坐席超过20000席;CPS(每秒处理呼叫数)能力在200-400之间;支持单平台最大1000租户;呼叫响应时间小于1秒;每天处理200万分钟通话;TTS平均响应时间少于1秒;消息响应时间小于1秒;录音转换效率应通话结束后小于1分钟可用;每天处理800G录音(压缩后);
2.解决平台高可用问题,消除单点,跨机房级负载均衡,平台有超高稳定性
3.弹性伸缩能力解决业务峰值问题
4.完整的生态子系统解决运营成本问题
凭借大容量高可用的智能云呼叫中心平台,天润融通收获了各行业客户的认可。快速灵活可扩展的云模式,也更加适应未来技术及业务的成长性需求,让呼叫中心的能力在未来可以持续增长。



 咨 询 客 服
咨 询 客 服