第一、几种常用方法
读取TXT文档:urlopen()
读取PDF文档:pdfminer3k
第二、乱码问题
(1)、
from urllib.request import urlopen
#访问wiki内容
html = urlopen("https://en.wikipedia.org/robots.txt")
print(html.read())
输出的结果中出现乱码原因:
计算机只能处理0和1两个数字,所以想要处理文本,必须把文本变成0和1这样的数字,最早的计算机使用八个0和1表示一个字节,所以最大能够表示整数是255=11111111.如果想要表示更大的数,必须使用更多的字节。
由于计算机是美国人发明的,所以最早只有127个字符被编写进计算机,即常见的阿拉伯数字,字母大小写,以及键盘上的符号。此编码被称为ASCII编码,比如大写字母A的ASCII编码是65,65再被转换二进制01000001,即是计算机处理的东西。
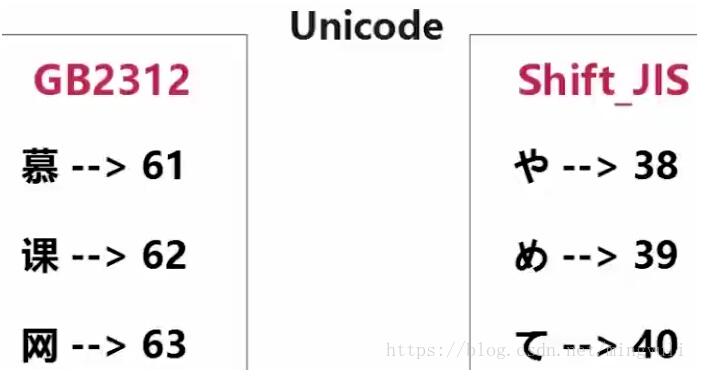
显然,ASCII不能表示中文,故中国制定了自己的GB2312编码,并且兼容ASCII编码。问题是:使用GB2312编码的慕课网三个字,假设编码为61,62,63.但在ASCII码表可能是其他字符。如下图示,日文中的616263编码成其他字符,打开后意思出错。

解决方法:
国际上的unicode编码,整合全世界所有编码。故unicode编码的内容在任一台计算机用unicode仍正常打开
又对于A,ASCII编码为01000001,Unicode编码:0000000001000001此时浪费空间
故出现UTF-8编码:01000001此时用两个八位存储中文。
(2)、记事本使用unicode编码,将记事本存到计算机时,将转化为utf-8储存。
在计算机中打开文本时,将转化为unicode编码
存储原因:使用utf-8储存节省空间,使用unicode打开保证最大的兼容
(3)、服务器读取uncode编码的文档,转化为utf-8格式传给浏览器。因为网络带宽昂贵,转化为了减少负担。
(4)、python3字符串默认使用Unicode编码,所以python3支持多种语言
以Unicode表示的str通过encode()方法可以编码为指定的bytes
如果bytes使用ASCII编码,遇到ASCII码表没有的字符会以\x##表示,此时只用‘\x##'.decode('utf-8')即可
(5)、解决方法
from urllib.request import urlopen
#访问wiki内容
html = urlopen("https://en.wikipedia.org/robots.txt")
print(html.read().decode("utf-8"))
第三、pdfminer3k安装
法一:
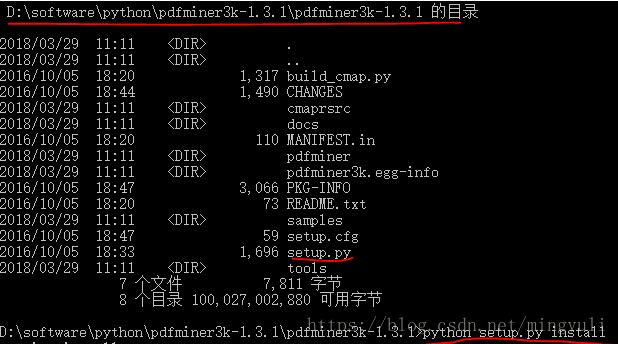
(1)、进入网址直接下载并解压:https://pypi.python.org/pypi/pdfminer3k/
(2)、以管理员身份运行命令行窗口,进入软件解压缩位置,运行python setup.py install
法二:
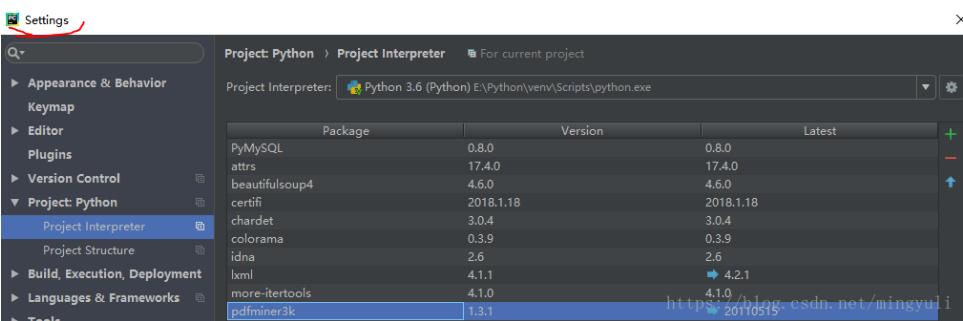
(3)、直接在pycharm中安装
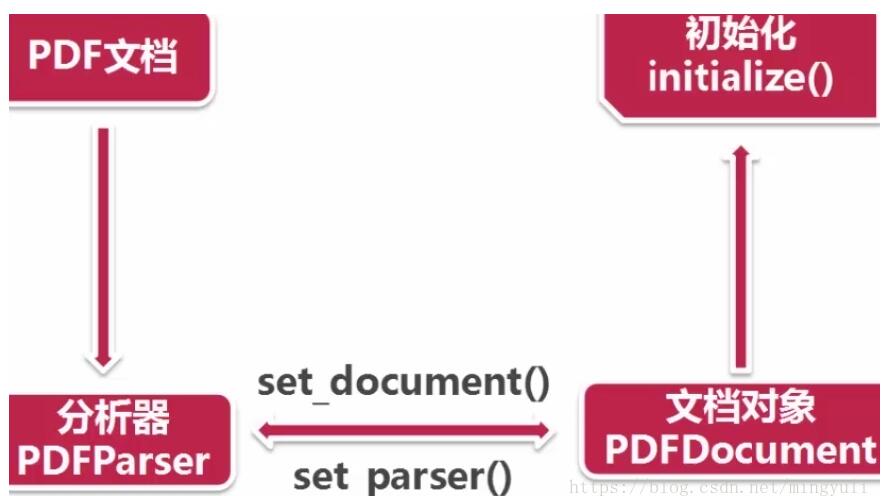
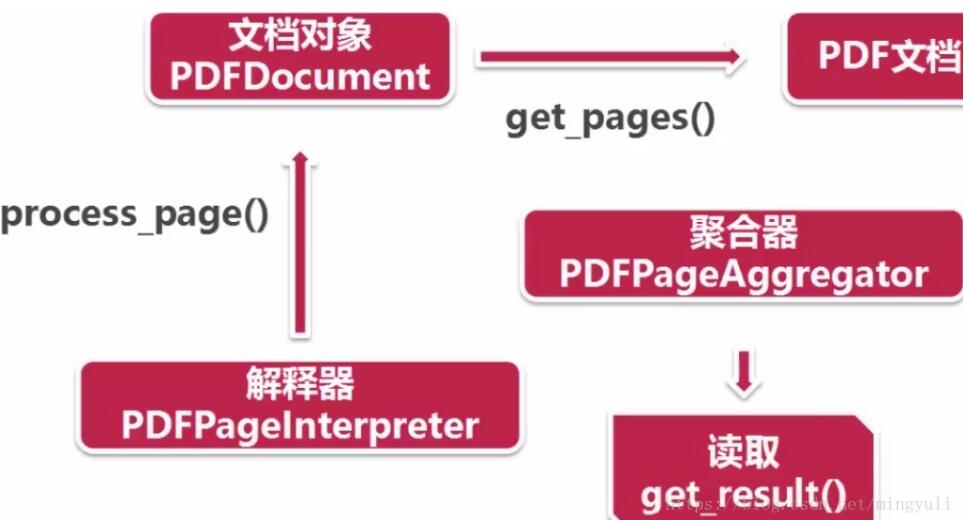
(4)、读取pdf过程:首先创建一个分析器pdfparser和文档对象pdfdocument,并通过两个方法相互关联,然后调用文档对象的初始化方法(可以传参数),此时资源内容被加载到文档对象中。
创建资源管理器和参数分析器,然后创建聚合器(整合资源管理器和参数分析器),通过聚合器创建解释器(对pdf文档进行编码,解释成python能识别的格式)

(5)、读取pdf文档:通过文档对象的get_pages()方法得到pdf每一页的内容,通过解释器的process_page()方法读取一页一页。
(6)、实例演示
from pdfminer.converter import PDFPageAggregator
from pdfminer.layout import LAParams
from pdfminer.pdfparser import PDFParser, PDFDocument
from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter
from pdfminer.pdfdevice import PDFDevice
#获得文档对象,以二进制读方式打开
fp = open("naacl06-shinyama.pdf", "rb")
#创建一个与文档关联的分析器
parser = PDFParser(fp)
#创建一个pdf文档的对象
doc = PDFDocument()
#连接解释器与文档对象
parser.set_document(doc)
doc.set_parser(parser)
#初始化文档,如果文档有密码,写与此。
doc.initialize("")
#创建pdf资源管理器
resource = PDFResourceManager()
#参数分析器
laparam = LAParams()
#创建聚合器
device = PDFPageAggregator(resource, laparams=laparam)
#创建pdf页面解释器
interpreter = PDFPageInterpreter(resource, device)
#使用文档对象得到页面的集合
for page in doc.get_pages():
#使用页面解释器读取
interpreter.process_page(page)
#使用聚合器来获得内容
layout = device.get_result()
for out in layout:
if hasattr(out, "get_text"):
print(out.get_text())
一下用于读取网站上pdf内容
fp = urlopen(http://www.tencent.com/zh-cn/articles/8003251479983154.pdf)
补充内容:
以上为个人经验,希望能给大家一个参考,也希望大家多多支持脚本之家。如有错误或未考虑完全的地方,望不吝赐教。
您可能感兴趣的文章:- Python爬虫爬取全球疫情数据并存储到mysql数据库的步骤
- Python爬取腾讯疫情实时数据并存储到mysql数据库的示例代码
- MySQL和Python交互的示例
- 配置python连接oracle读取excel数据写入数据库的操作流程
- Python 对Excel求和、合并居中的操作
- 如何用python合并多个excel文件
- python基于pyppeteer制作PDF文件
- python操作mysql、excel、pdf的示例


 咨 询 客 服
咨 询 客 服