偶然从pytorch讨论论坛中看到的一个问题,KL divergence different results from tf,kl divergence 在TensorFlow中和pytorch中计算结果不同,平时没有注意到,记录下
一篇关于KL散度、JS散度以及交叉熵对比的文章
kl divergence 介绍
KL散度( Kullback–Leibler divergence),又称相对熵,是描述两个概率分布 P 和 Q 差异的一种方法。计算公式:
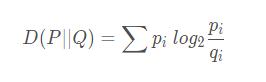
可以发现,P 和 Q 中元素的个数不用相等,只需要两个分布中的离散元素一致。
举个简单例子:
两个离散分布分布分别为 P 和 Q
P 的分布为:{1,1,2,2,3}
Q 的分布为:{1,1,1,1,1,2,3,3,3,3}
我们发现,虽然两个分布中元素个数不相同,P 的元素个数为 5,Q 的元素个数为 10。但里面的元素都有 “1”,“2”,“3” 这三个元素。
当 x = 1时,在 P 分布中,“1” 这个元素的个数为 2,故 P(x = 1) = 2/5 = 0.4,在 Q 分布中,“1” 这个元素的个数为 5,故 Q(x = 1) = 5/10 = 0.5
同理,
当 x = 2 时,P(x = 2) = 2/5 = 0.4 ,Q(x = 2) = 1/10 = 0.1
当 x = 3 时,P(x = 3) = 1/5 = 0.2 ,Q(x = 3) = 4/10 = 0.4
把上述概率带入公式:
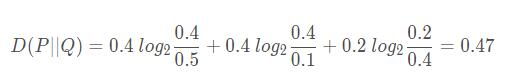
至此,就计算完成了两个离散变量分布的KL散度。
pytorch 中的 kl_div 函数
pytorch中有用于计算kl散度的函数 kl_div
torch.nn.functional.kl_div(input, target, size_average=None, reduce=None, reduction='mean')

计算 D (p||q)
1、不用这个函数的计算结果为:

与手算结果相同
2、使用函数:
(这是计算正确的,结果有差异是因为pytorch这个函数中默认的是以e为底)

注意:
1、函数中的 p q 位置相反(也就是想要计算D(p||q),要写成kl_div(q.log(),p)的形式),而且q要先取 log
2、reduction 是选择对各部分结果做什么操作,默认为取平均数,这里选择求和
好别扭的用法,不知道为啥官方把它设计成这样
补充:pytorch 的KL divergence的实现
看代码吧~
import torch.nn.functional as F
# p_logit: [batch, class_num]
# q_logit: [batch, class_num]
def kl_categorical(p_logit, q_logit):
p = F.softmax(p_logit, dim=-1)
_kl = torch.sum(p * (F.log_softmax(p_logit, dim=-1)
- F.log_softmax(q_logit, dim=-1)), 1)
return torch.mean(_kl)
以上为个人经验,希望能给大家一个参考,也希望大家多多支持脚本之家。
您可能感兴趣的文章:- pytorch 实现计算 kl散度 F.kl_div()
- 浅谈pytorch 模型 .pt, .pth, .pkl的区别及模型保存方式
- Pytorch 计算误判率,计算准确率,计算召回率的例子


 咨 询 客 服
咨 询 客 服