pytorch_pretrained_bert将tensorflow模型转化为pytorch模型
BERT仓库里的模型是TensorFlow版本的,需要进行相应的转换才能在pytorch中使用
在Google BERT仓库里下载需要的模型,这里使用的是中文预训练模型(chinese_L-12_H-768_A_12)
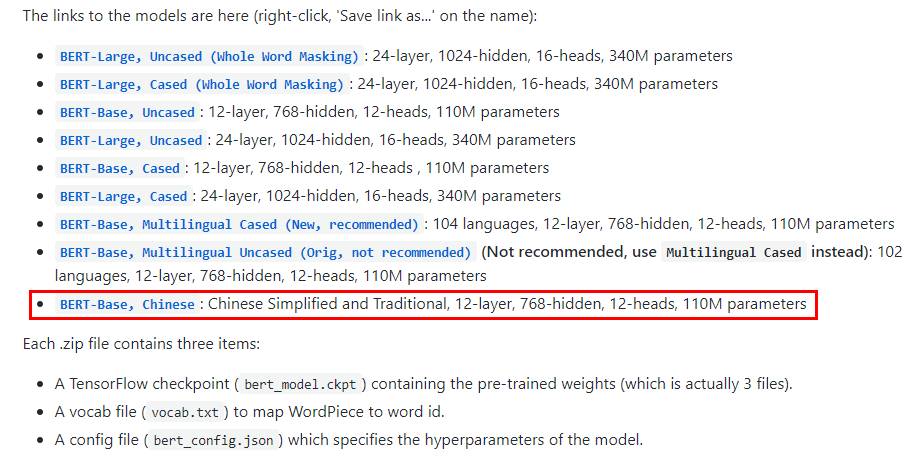
下载chinese_L-12_H-768_A-12.zip后解压,里面有5个文件
chinese_L-12_H-768_A-12.zip后解压,里面有5个文件
bert_config.json
bert_model.ckpt.data-00000-of-00001
bert_model.ckpt.index
bert_model.ckpt.meta
vocab.txt
使用bert仓库里的convert_bert_original_tf_checkpoint_to_pytorch.py将此模型转化为pytorch版本的,这里我的文件夹位置为:D:\Work\BISHE\BERT-Dureader\data\chinese_L-12_H-768_A-12,替换为自己的即可
python convert_tf_checkpoint_to_pytorch.py --tf_checkpoint_path D:\Work\BISHE\BERT-Dureader\data\chinese_L-12_H-768_A-12\bert_model.ckpt --bert_config_file D:\Work\BISHE\BERT-Dureader\data\chinese_L-12_H-768_A-12\bert_config.json --pytorch_dump_path D:\Work\BISHE\BERT-Dureader\data\chinese_L-12_H-768_A-12\pytorch_model.bin
注:这里让我疑惑的是模型有5个文件,为什么转化的时候使用的是bert_model.ckpt,而且这个文件也不存在呀,是我对TensorFlow的模型不太熟悉,查阅资料之后将5个文件的作用说明如下:
$ tree chinese_L-12_H-768_A-12/
chinese_L-12_H-768_A-12/
├── bert_config.json - 模型配置文件
├── bert_model.ckpt.data-00000-of-00001 - 保存断点文件列表,可以用来迅速查找最近一次的断点文件
├── bert_model.ckpt.index - 为数据文件提供索引,存储的核心内容是以tensor name为键以BundleEntry为值的表格entries,BundleEntry主要内容是权值的类型、形状、偏移、校验和等信息。
├── bert_model.ckpt.meta - 是MetaGraphDef序列化的二进制文件,保存了网络结构相关的数据,包括graph_def和saver_def等
└── vocab.txt - 模型词汇表文件
0 directories, 5 files
在调用模型时使用chinese_L-12_H-768_A-12\bert_model.ckpt即可。
TensorFlow 读取ckpt文件中的tensor,将ckpt模型转为pytorch模型
想用MobileNet V1训练自己的数据,发现pytorch没有MobileNet V1的预训练权重,只好先下载TensorFlow的预训练权重,再转成pytorch模型。
读取ckpt中的Tensor名称以及Tensor值
TensorFlow的MobileNet V1预训练权重文件如下:
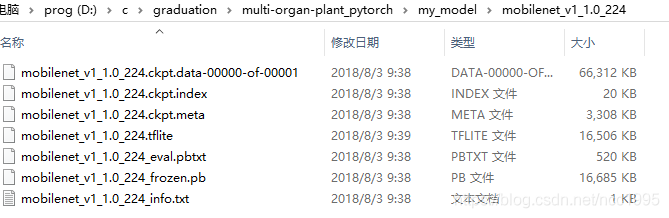
解压完文件后,发现没有.ckpt文件,文件名只需'./my_model/mobilenet_v1_1.0_224/mobilenet_v1_1.0_224.ckpt'这样写就行。
写一半发现Tensor名称好难对应起来。希望能给大家一个参考,也希望大家多多支持脚本之家
您可能感兴趣的文章:- 教你使用TensorFlow2识别验证码
- TensorFlow中tf.batch_matmul()的用法
- Tensorflow与RNN、双向LSTM等的踩坑记录及解决
- tensorflow中的数据类型dtype用法说明
- tensorflow基本操作小白快速构建线性回归和分类模型


 咨 询 客 服
咨 询 客 服