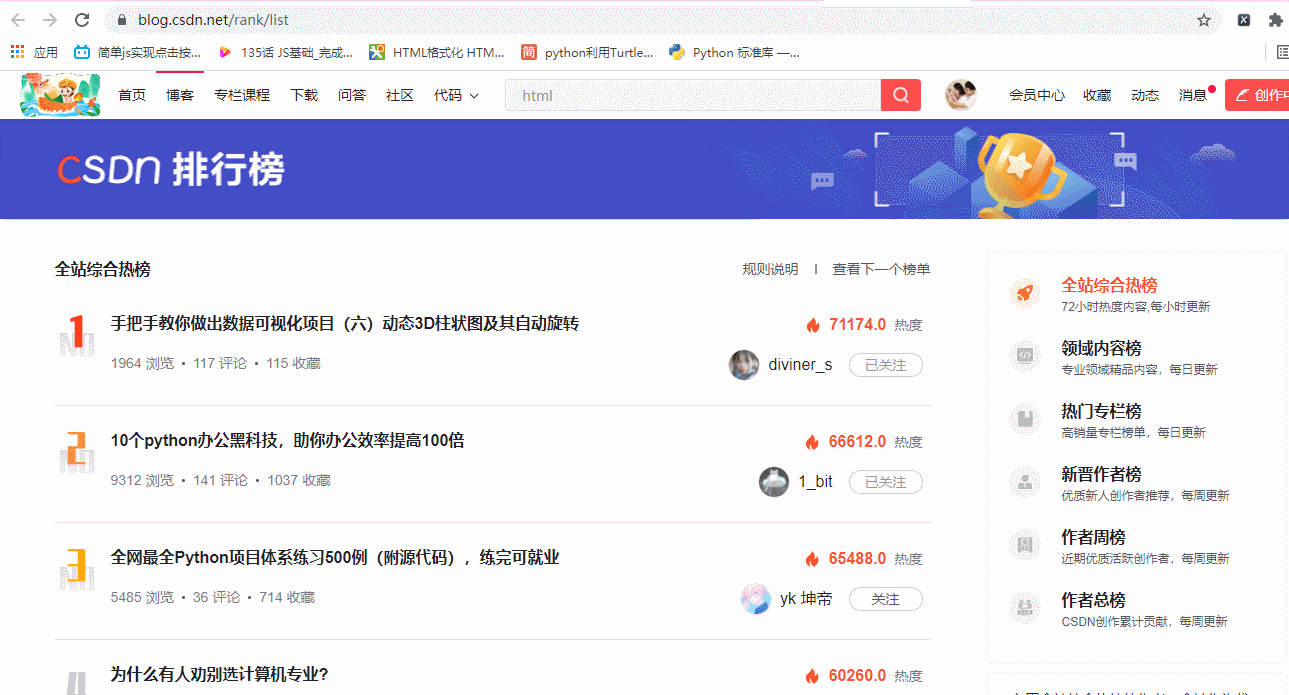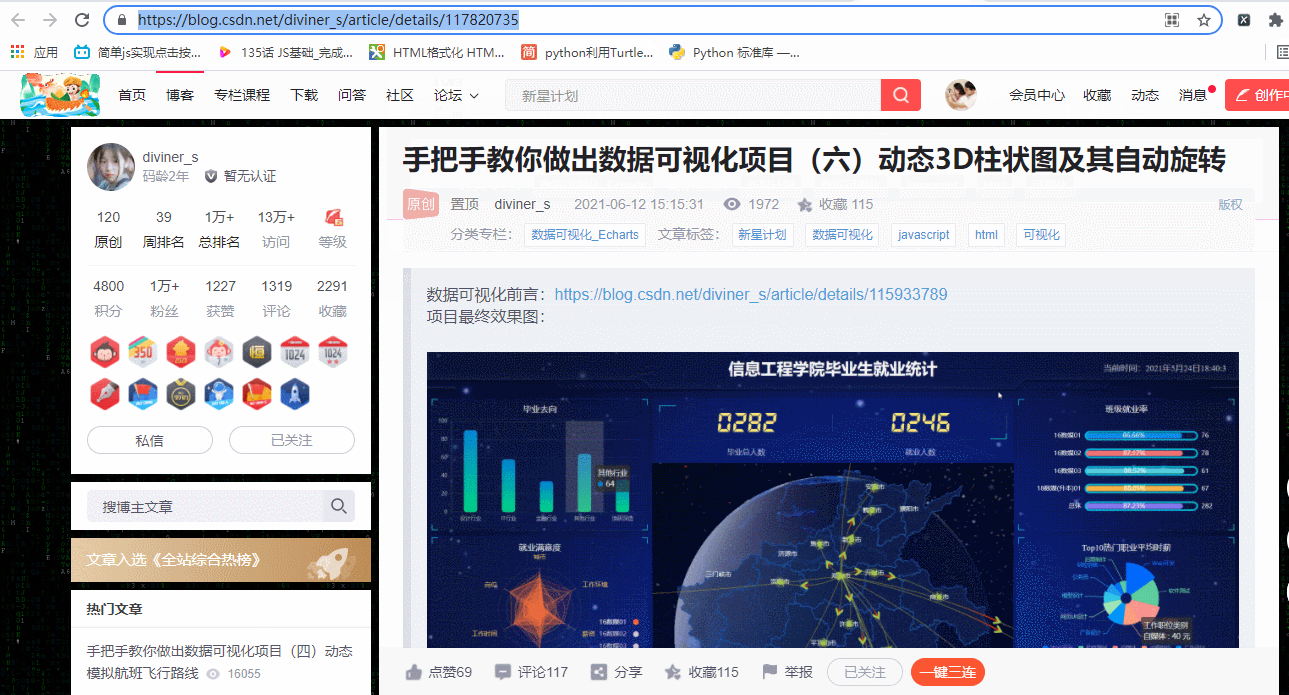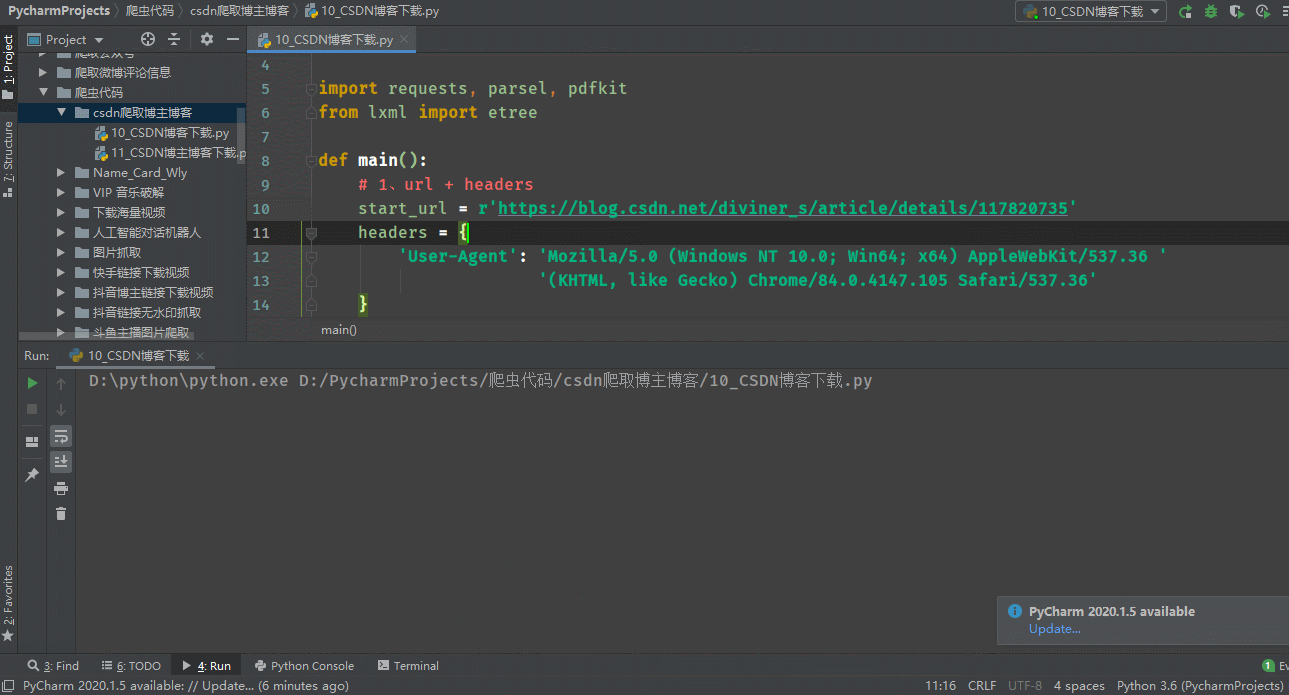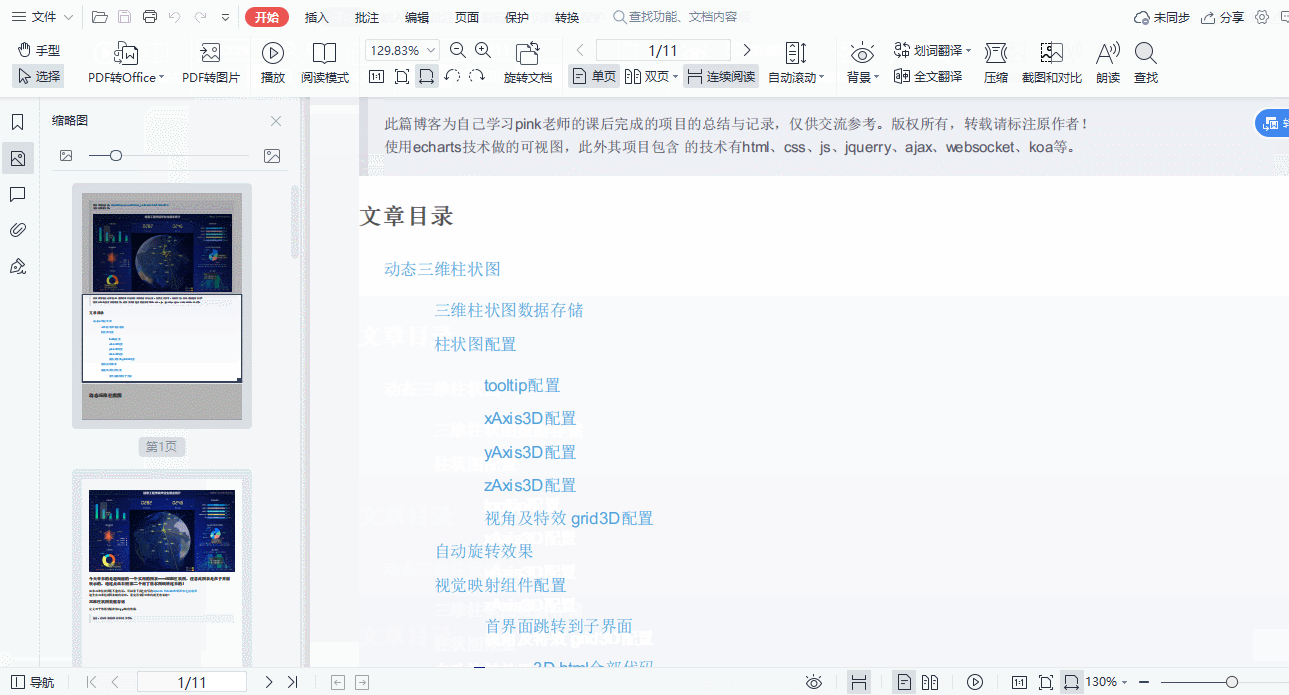
我们学习编程,在学习的时候,会有想把有用的知识点保存下来,我们可以把知识点的内容爬下来转变成pdf格式,方便我们拿手机可以闲时翻看,是很方便的
先来一个单个的博文下载转pdf格式的操作
python中将html转化为pdf的常用工具是Wkhtmltopdf工具包,在python环境下,pdfkit是这个工具包的封装类。如何使用pdfkit以及如何配置呢?分如下几个步骤。
下载wkhtmltopdf安装包,并且安装到电脑上。
下载地址:https://wkhtmltopdf.org/downloads.html
我下的是这个版本,安装的时候要记住路径,之后调用要用到路径

开发工具
- python
- pycharm
- pdfkit (pip install pdfkit)
- lxml
今天目标:博主的全部博文下载,并且转pdf格式保存
基本思路:
1、url + headers
2、分析网页: CSDN网页是静态网页, 请求获取网页源代码
3、lxml解析获取boke_urls, author_name
4、循环遍历,得到 boke_url
5、xpath解析获取文件名
6、css选择器获取标签文本的主体
7、构造拼接html文件
8、保存html文件
9、文件的转换
分析网页: CSDN网页是静态网页, 请求获取网页源代码
start_url =“https://i1bit.blog.csdn.net/” 为例
确定网址为同步加载
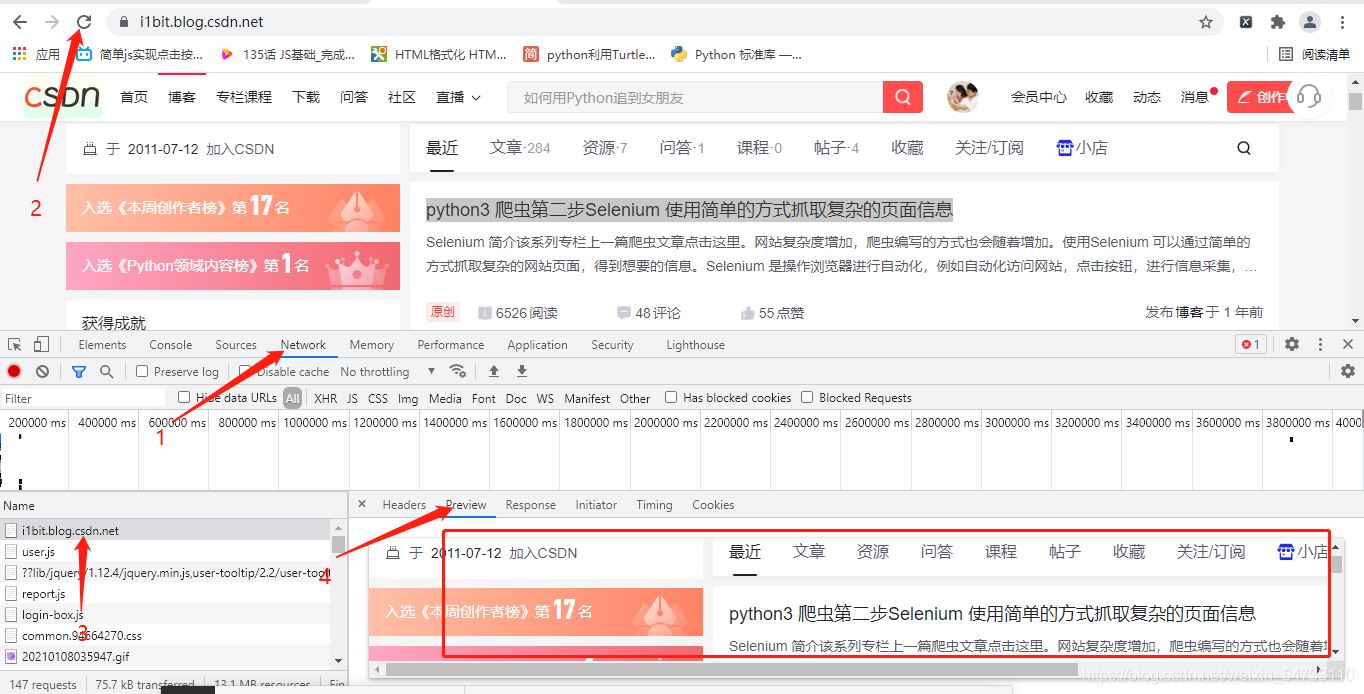
css选择器获取标签文本的主体为代码要点部分
css语法部分
# css选择器获取标签文本的主体
html_css = parsel.Selector(response_2)
html_content = html_css.css('article').get()
# 构造拼接html文件
html = \
'''
!DOCTYPE html>
html lang="en">
head>
meta charset="UTF-8">
title>Title/title>
/head>
body>
{}
/body>
/html>
'''.format(html_content)
点开博主的一篇博文打开开发者工具
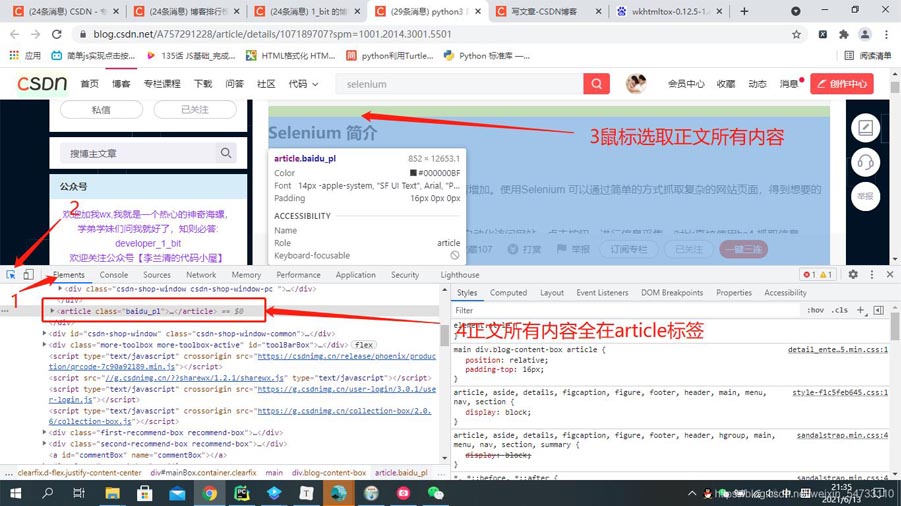
# css选择器获取标签文本的主体
html_css = parsel.Selector(response_2)
html_content = html_css.css('article').get()
# 构造拼接html文件
html = \
'''
!DOCTYPE html>
html lang="en">
head>
meta charset="UTF-8">
title>Title/title>
/head>
body>
{}
/body>
/html>
'''.format(html_content)
文件的转换
config = pdfkit.configuration(wkhtmltopdf=r'这里为下载wkhtmltopdf.exe的路径')
pdfkit.from_file(
第一个参数要转变的html文件,
第二个参数转变后的pdf文件,
configuration=config
)
# 上面这样写清楚一点,也可以直接
pdfkit.from_file(
第一个参数要转变的html文件,
第二个参数转变后的pdf文件,
configuration=pdfkit.configuration(wkhtmltopdf=r'这里为下载wkhtmltopdf.exe的路径')
)
源码展示:
import parsel, os, pdfkit
from lxml import etree
from requests_html import HTMLSession
session = HTMLSession()
def main():
# 1、url + headers
start_url = input(r'请输入csdn博主的地址:')
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 '
'(KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36'
}
# 2、分析网页: CSDN网页是静态网页, 请求获取网页源代码
response_1 = session.get(start_url, headers=headers).text
# 3、解析获取boke_urls, author_name
html_xpath_1 = etree.HTML(response_1)
author_name = html_xpath_1.xpath(r'//*[@id="floor-user-profile_485"]/div/div[1]/div[2]/div[2]/div[1]/div[1]/text()')[0]
boke_urls = html_xpath_1.xpath(r'//article[@class="blog-list-box"]/a/@href')
# 4、循环遍历,得到 boke_url
for boke_url in boke_urls:
# 5、请求
response_2 = session.get(boke_url, headers=headers).text
# 6、xpath解析获取文件名
html_xpath_2 = etree.HTML(response_2)
file_name = html_xpath_2.xpath(r'//h1[@id="articleContentId"]/text()')[0]
# 7、css选择器获取标签文本的主体
html_css = parsel.Selector(response_2)
html_content = html_css.css('article').get()
# 8、构造拼接html文件
html = \
'''
!DOCTYPE html>
html lang="en">
head>
meta charset="UTF-8">
title>Title/title>
/head>
body>
{}
/body>
/html>
'''.format(html_content)
# 9、创建两个文件夹, 一个用来保存html 一个用来保存pdf文件
if not os.path.exists(r'{}-html'.format(author_name)):
os.mkdir(r'{}-html'.format(author_name))
if not os.path.exists(r'{}-pdf'.format(author_name)):
os.mkdir(r'{}-pdf'.format(author_name))
# 10、保存html文件
try:
with open(r'{}-html/{}.html'.format(author_name, file_name), 'w', encoding='utf-8') as f:
f.write(html)
except Exception as e:
print('文件名错误')
# 11、文件的转换
try:
config = pdfkit.configuration(wkhtmltopdf=r'C:\Program Files\wkhtmltopdf\bin\wkhtmltopdf.exe')
pdfkit.from_file(
'{}-html/{}.html'.format(author_name, file_name),
'{}-pdf/{}.pdf'.format(author_name, file_name),
configuration=config
)
a = print(r'--文件下载成功:{}.pdf'.format(file_name))
except Exception as e:
continue
if __name__ == '__main__':
main()
代码操作:
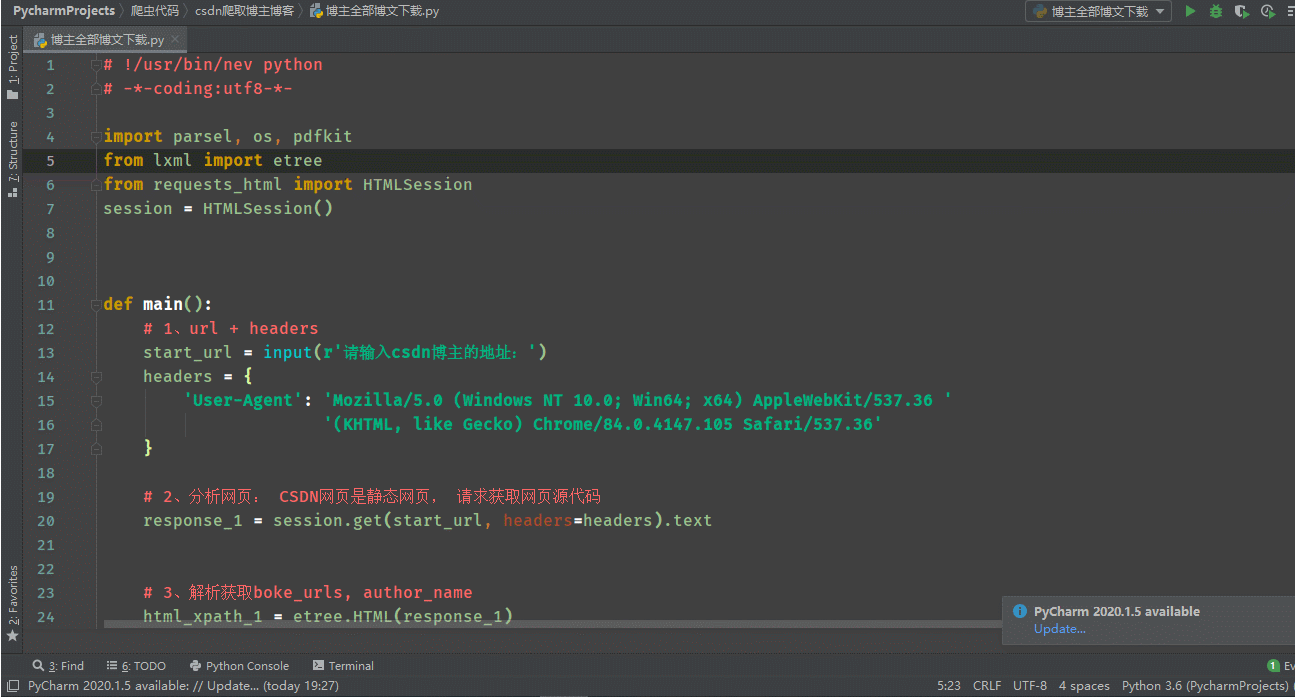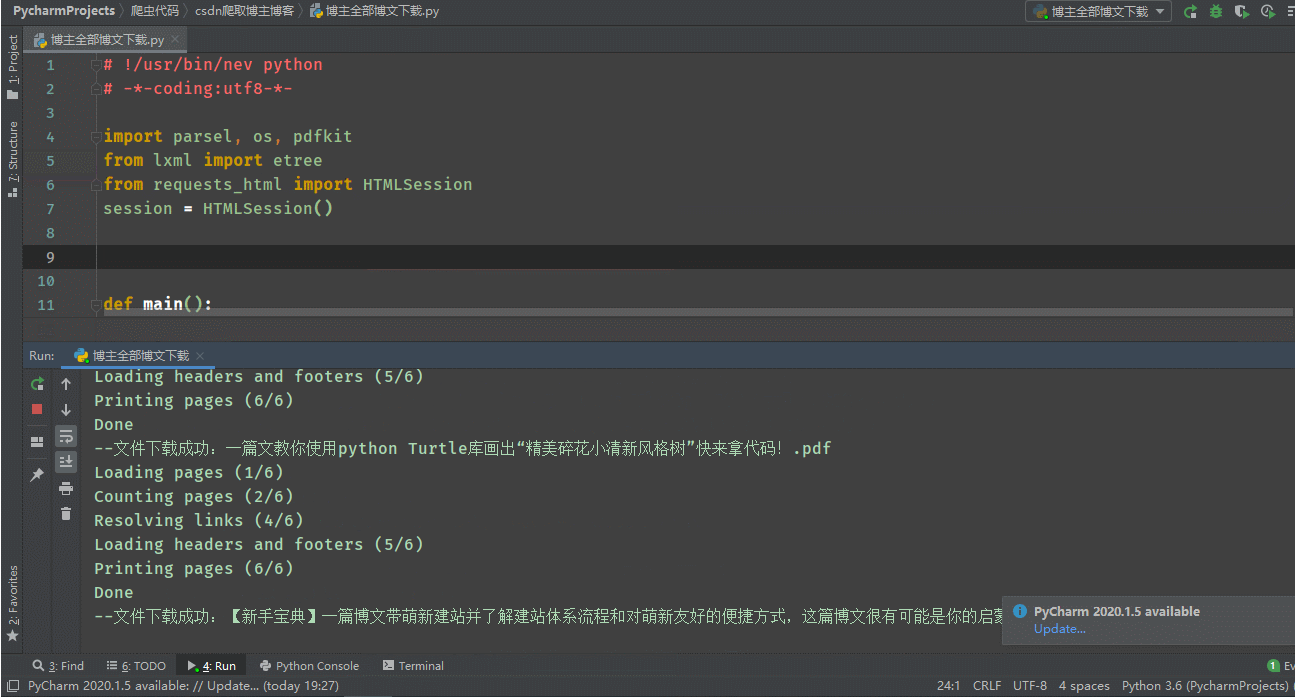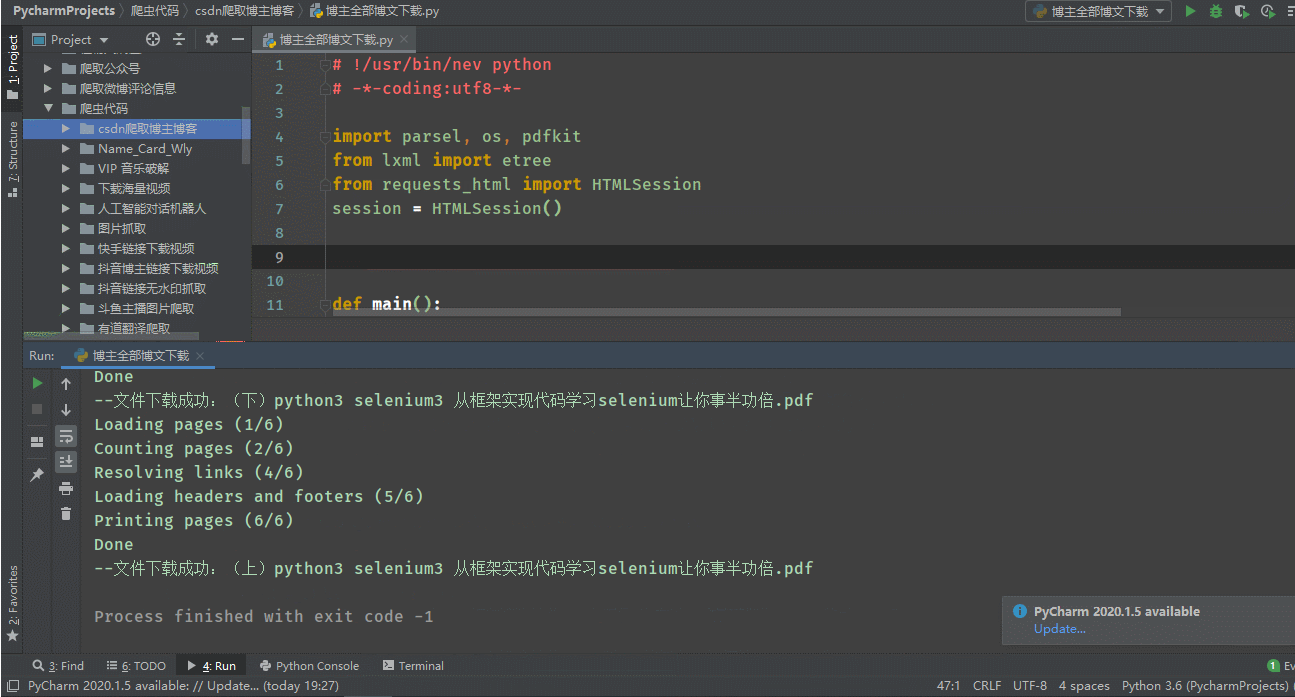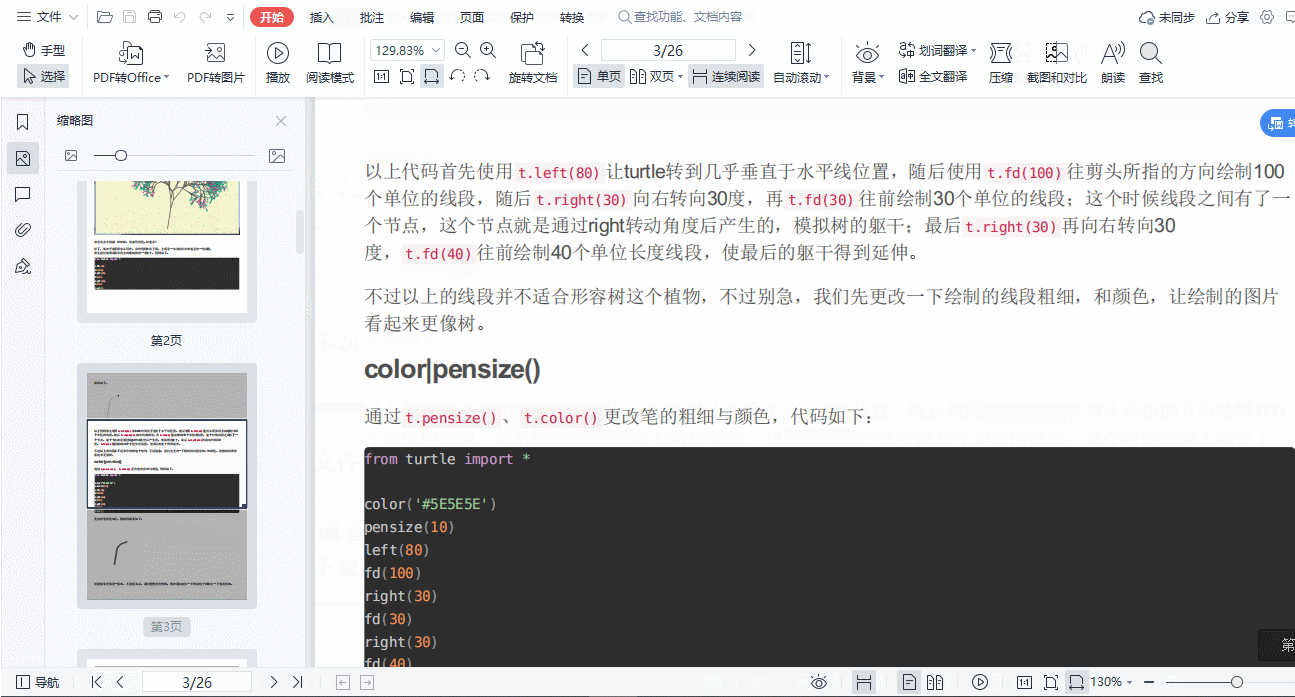
到此这篇关于python实现csdn全部博文下载并转PDF的文章就介绍到这了,更多相关python 博文下载并转PDF内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
您可能感兴趣的文章:- python解析PDF程序代码
- Python合并多张图片成PDF
- Python提取PDF指定内容并生成新文件
- 详解用Python把PDF转为Word方法总结
- python操作mysql、excel、pdf的示例
- python pdfkit 中文乱码问题的解决方案
- python 三种方法提取pdf中的图片
- Python实现给PDF添加水印的方法
- Python读取pdf表格写入excel的方法
- Python 多张图片合并成一个pdf的参考示例


 咨 询 客 服
咨 询 客 服