目录
- 前言
- 开始
- 分析(x0)
- 分析(x1)
- 分析(x2)
- 分析(x3)
- 分析(x4)
- 通过分析获取到音乐
- JavaScript绕过之参数冗余
- CSRF攻击与防御
- 总结
- 代码
前言
大家好,我叫善念。
这是我的第二篇博客,也是第一篇技术博客,希望大家多多支持,让我更加有动力去更新一些python爬虫类的案例教程。

开始
确立目标网址:点击进入

进入到跳转页面:
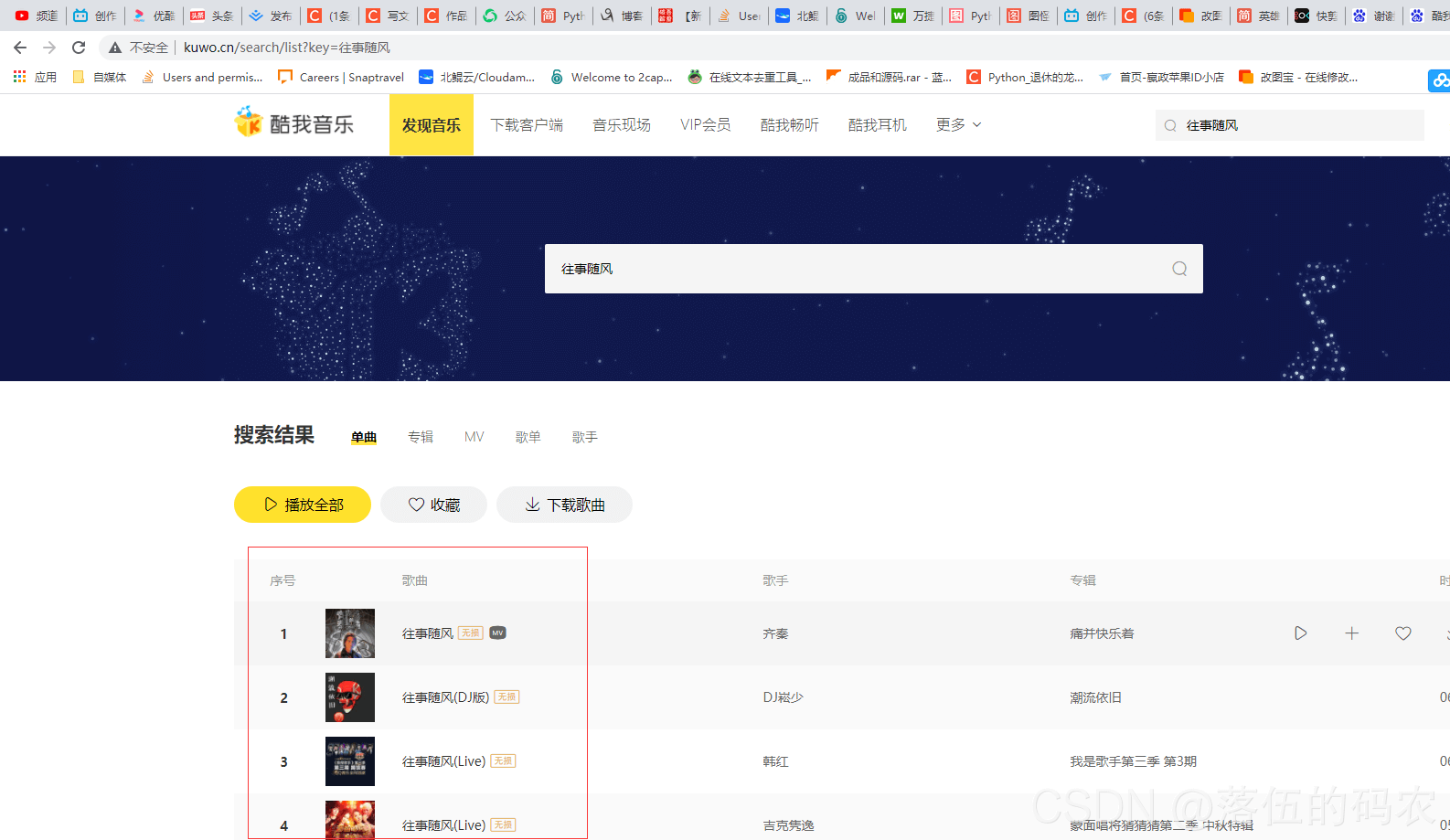
可以看到出现了咱们需要的一些音乐
分析(x0)
这些音乐的源文件地址是否在咱们的网页元素中,然后再查看网页源代码中是否有咱们需要的内容。(注:网页元素与网页源代码不一定是一样的,网页元素是经过浏览器渲染后的源代码,而源代码纯粹就是服务器给咱们传送过来的原始数据)
网页元素中只有封面图片的资源,没用音频源文件地址:

网页源代码中同样没有咱们需要的内容:

分析(x1)
其实没有才正常(这种大型网站的数据不会让你这么轻易抓取)....不过是带大家走一遍流程,对别的网站也要这样分析
那么咱们开始播放音乐抓包,看是否能抓到数据:

果然是经过触发播放按钮后,服务器传给咱们客户端的。(ajax)
而咱们抓到的这个源文件地址

除了这两段外,其它的应该都是固定死的。
分析(x2)
那么我假设这两段是从我开始访问这首歌曲页面的时候生成的,比如后面那串数字为这首音乐在服务器数据库中的对应的一个ID值呢?
假设是合理的,不过由于咱们前面已经查看过源代码和网页元素中找不到这些值,我就不在这里浪费时间了。
分析(x3)
这里我和大家讲一下,咱们向服务器发送一个网址请求,服务器给咱们返回的可不止一个数据包,一般都是N个数据包。当我们看到源代码中没有时候,也许它正悄悄地通过Ajax传给我们了?
Ajax在网上有很多的解释,但是大家未必能理解。从服务器获得源代码数据,然后通过浏览器渲染执行JavaScript获得一些数据(音乐)。
这样说大家应该就懂了,那么咱们开始抓当前页面的包:
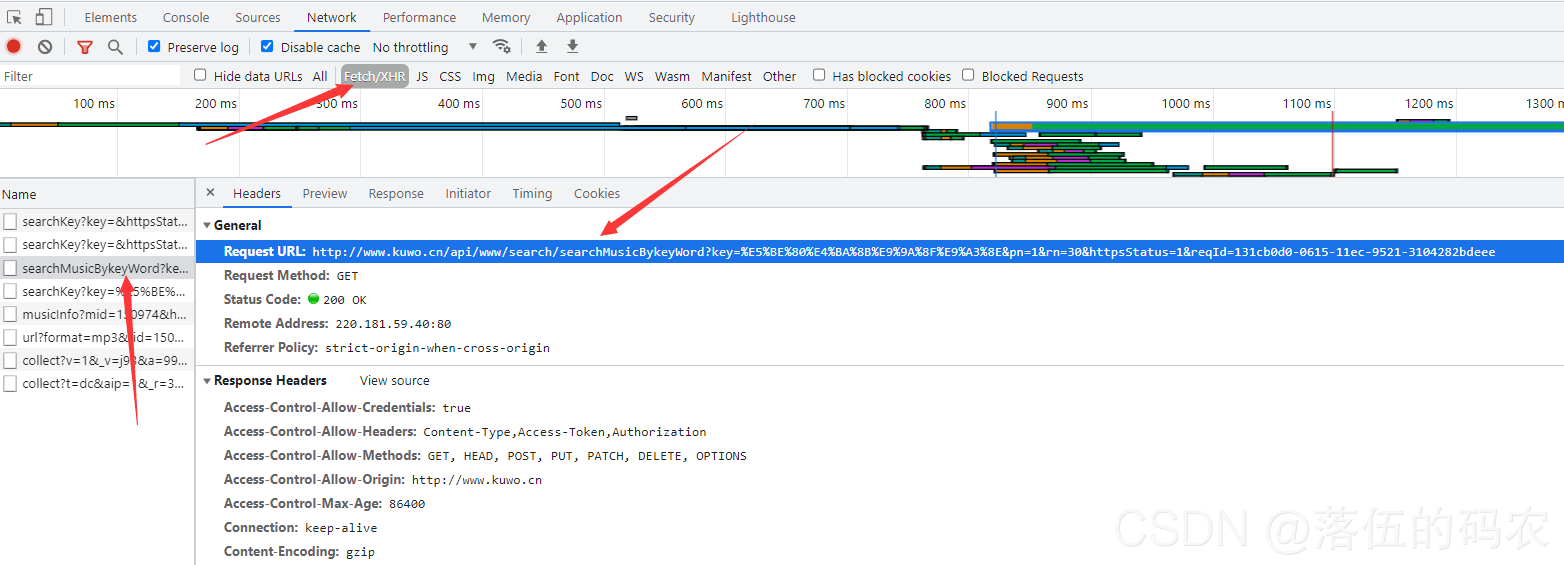
Ajax异步请求的数据,都会在XHR中。所以直接筛选就好了。这个包我已经抓到了,get请求然后看下返回的值。
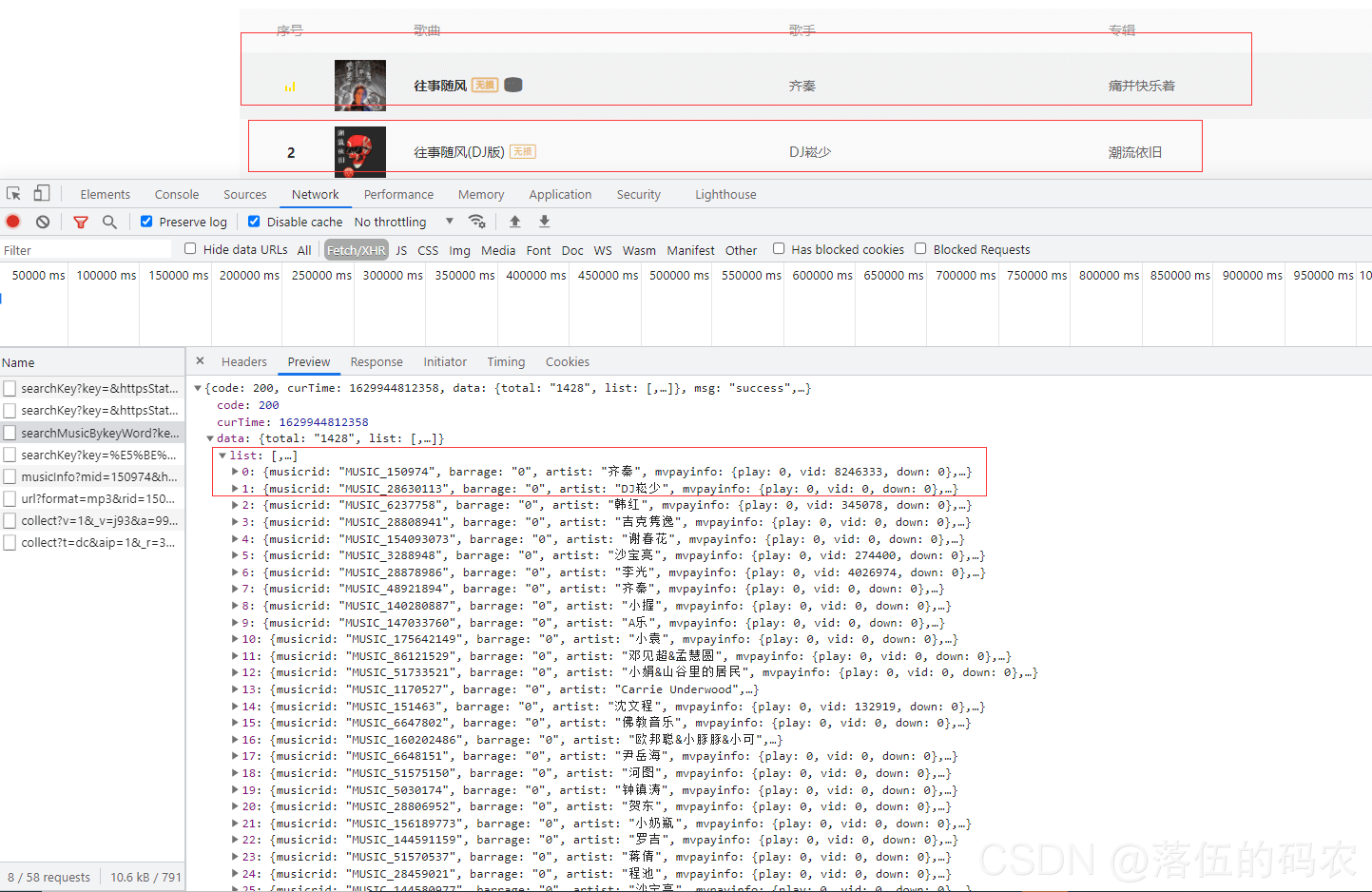
果然就是这个包数据都是对应的,然后打开看看里面是否有音乐源文件地址:
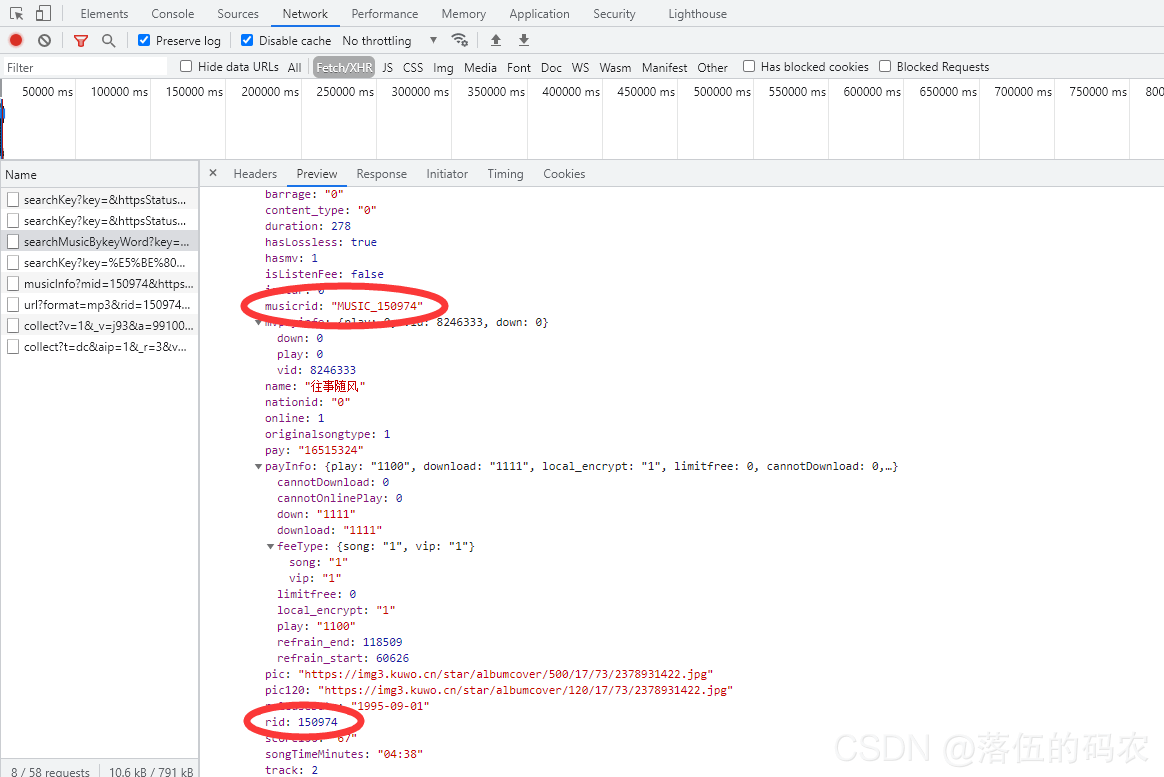
并没有,但是有一个rid出现了两次。
分析(x4)
那么它是否是咱们音乐的ID(索引)值?
接着看下面的包:

这个get请求很关键,它的参数中利用到了咱们的rid这个值
而他返回值里正好有咱们的音乐源文件地址:

通过分析获取到音乐
通过咱们的分析,已经可以理清思路了。
首先抓取这个包获取到rid
然后传递rid进行这个包的请求获取到音乐文件地址
JavaScript绕过之参数冗余
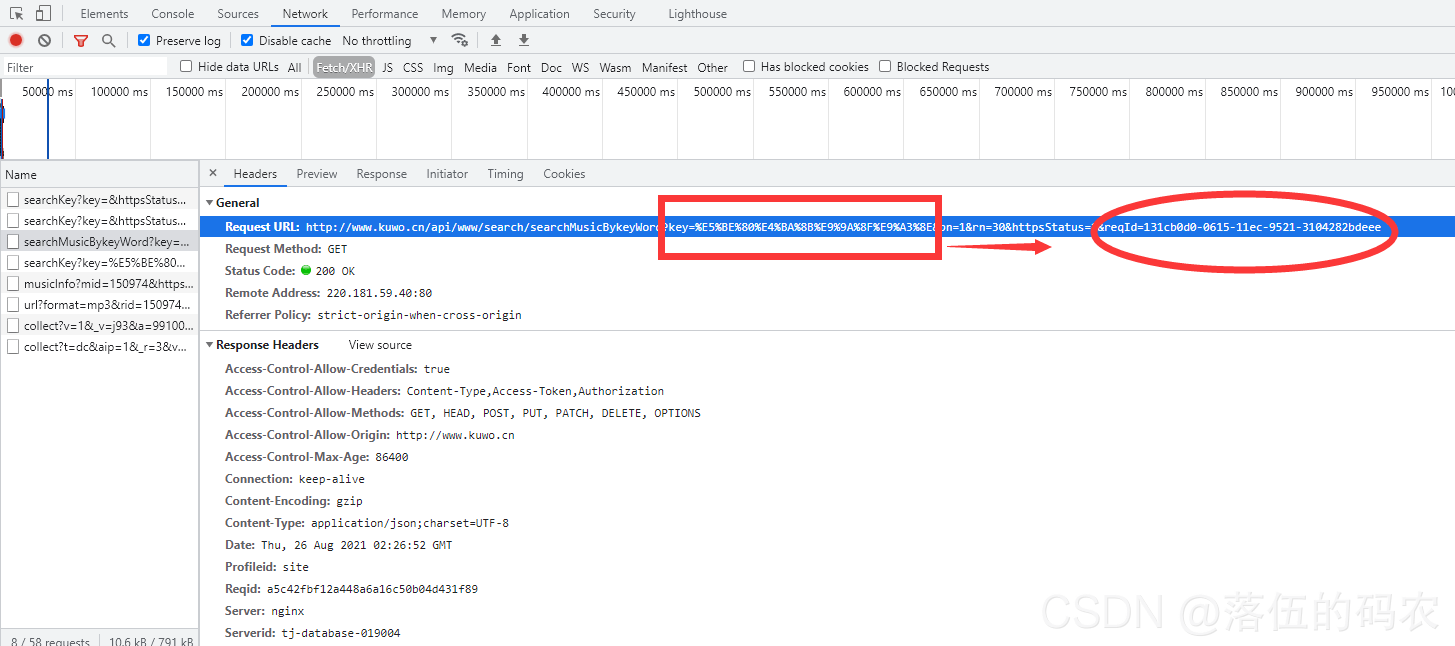
可以看到这个rid获取的地址中有key值是url编码很轻松就可以解码:
import requests
keywords = '%E5%BE%80%E4%BA%8B%E9%9A%8F%E9%A3%8E'
print(requests.utils.unquote(keywords))
# 往事随风
而pn=1意思就是第一页嘛,30就是这一页总共30条音乐数据咯,1代表状态码请求成功,而最后reqId这个值如何获取呢?

有能力的自己去逆向JavaScript,而咱们这里直接把这里的参数都删除掉,同样可以访问到咱们的rid,为什么呢?
当你访问百度的时候

可以看到多余了很多你看不懂的参数,而这些参数实际上可以直接删除掉!

结果是一样的,这个就叫参数冗余。
CSRF攻击与防御
当咱们直接访问这个链接确出现这样的画面?
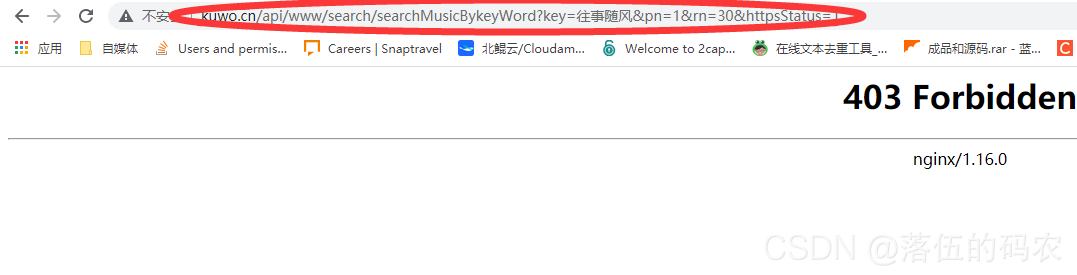
而咱们如果把请求头全部放到咱们的pycharm中利用Python模拟发送请求却可以成功(自行测试)

可以看到请求中有一个参数叫csrf,这个叫做防跨站点攻击。
这个就好理解了,当我们用浏览器直接访问的话,尽管可以带cookies,但是咱们是没法携带这个参数的。而当我们把请求头完整的复制在pycharm中Python运行的话,就可以携带这个参数,那么就可以访问。
目的就是保护此api防止任意情况下都可以随便访问。
而这个csrf参数不就是咱们cookies中的值么?那么是不是咱们首先需要获取cookies?因为cookies会过期阿,为了让你的程序永久有效,那么最好的办法就是自动获取cookies
总结
那么所有的原理都可以搞清楚了
首先访问首页获取cookies,然后绕过JavaScript删除多余的参数获取到rid,最后通过rid进行访问获取到音乐源地址(这里的参数也可以删除),最后保存数据!
全程干货,分析网站反扒手段,Python采集整站任意音乐!
代码
"""
author: 善念
date: 2021-04-12
"""
import requests
import jsonpath
from urllib.request import urlretrieve
import urllib.parse
def get_csrf():
# 保持cookies 维持客户端与服务器之间的会话
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9,en-US;q=0.8,en;q=0.7',
'Cache-Control': 'no-cache',
'Connection': 'keep-alive',
# 'Cookie': 'Hm_lvt_cdb524f42f0ce19b169a8071123a4797=1618229629; _ga=GA1.2.1951895595.1618229638; _gid=GA1.2.369506281.1618229638; Hm_lpvt_cdb524f42f0ce19b169a8071123a4797=1618230532; kw_token=ZOMA0RIOLV',
'Host': 'www.kuwo.cn',
'Pragma': 'no-cache',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36',
}
s.get('http://www.kuwo.cn/', headers=headers)
url = f'http://www.kuwo.cn/api/www/search/searchMusicBykeyWord?key={keyword}pn=1rn=30httpsStatus=1reqId=a3b6cb30-9b8a-11eb-bc04-b33703ed2ebb'
headers = {
'Accept': 'application/json, text/plain, */*',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9,en-US;q=0.8,en;q=0.7',
'Cache-Control': 'no-cache',
'Connection': 'keep-alive',
# 'Cookie': 'Hm_lvt_cdb524f42f0ce19b169a8071123a4797=1618229629; _ga=GA1.2.1951895595.1618229638; _gid=GA1.2.369506281.1618229638; Hm_lpvt_cdb524f42f0ce19b169a8071123a4797=1618229710; kw_token=UTBATXE1HY',
'csrf': s.cookies.get_dict()['kw_token'],
'Host': 'www.kuwo.cn',
'Pragma': 'no-cache',
'Referer': f'http://www.kuwo.cn/search/list?key={keyword}',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36',
}
r = s.get(url, headers=headers)
print(r.text)
rid = jsonpath.jsonpath(r.json(), '$..rid')[0]
print(rid)
return rid
def get_music_url(rid):
url = f'http://www.kuwo.cn/url?format=mp3rid={rid}response=urltype=convert_url3br=128kmp3from=webhttpsStatus=1'
headers = {
'Accept': 'application/json, text/plain, */*',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Cache-Control': 'no-cache',
'Connection': 'keep-alive',
# 'Cookie': 'Hm_lvt_cdb524f42f0ce19b169a8071123a4797=1618231398; _ga=GA1.2.52993118.1618231399; _gid=GA1.2.889494894.1618231399; Hm_lpvt_cdb524f42f0ce19b169a8071123a4797=1618231413; _gat=1; kw_token=VBM6N1XEG4P',
'Host': 'www.kuwo.cn',
'Pragma': 'no-cache',
'Referer': f'http://www.kuwo.cn/search/list?key={keyword}',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36',
}
music_url = s.get(url, headers=headers).json().get('url')
print(music_url)
return music_url
def get_music(music_url):
urlretrieve(music_url, f'{urllib.parse.unquote(keyword)}'+'.mp3')
def go():
rid = get_csrf()
music_url = get_music_url(rid)
get_music(music_url)
if __name__ == '__main__':
s = requests.session()
keyword = input('请输入您要下载的音乐名字:')
keyword = urllib.parse.quote(keyword)
go()
到此这篇关于Python音乐爬虫完美绕过反爬的文章就介绍到这了,更多相关Python爬取音乐内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
您可能感兴趣的文章:- Python基于爬虫实现全网搜索并下载音乐
- python实现可下载音乐的音乐播放器
- 如何基于Python批量下载音乐
- python爬取网易云音乐热歌榜实例代码
- python打开音乐文件的实例方法
- python给视频添加背景音乐并改变音量的具体方法
- python中加背景音乐如何操作
- 基于python实现音乐播放器代码实例
- Python如何爬取qq音乐歌词到本地
- python实现音乐播放和下载小程序功能
- 如何用Python一次性下载抖音上音乐


 咨 询 客 服
咨 询 客 服