目录
- 1.数据导入
- 1.1使用标准Python类库导入数据
- 1.2使用Numpy导入数据
- 1.3使用Pandas导入数据
- 2.数据理解
- 2.1数据基本属性
- 2.1.1查看前10行数据
- 2.1.2查看数据维度,数据属性和类型:
- 2.1.3查看数据描述性统计
- 2.2数据相关性和分布分析
- 3.数据可视化
- 总结
统计学是什么?概率与数学。用概率与数学来分析人,分析的永远不是人。用永远不是人的结论指导人实在是一种偏误。在这个意义上讲,解读强于技术。
——刘德寰
1.数据导入
在训练机器学习的模型时,需要大量的数据,最常用的方法是利用历史数据来训练模型。这些历史数据通常是以csv文件储存,或者能够方便地转化为csv文件。在开始机器学习时,我们首先要导入csv数据文件。
csv文件是用逗号(,)分隔的文本文件。在csv文件中注释是以(#)开头。
在接下来的文章中,将使用Pima Indians数据集,它是从UCI机器学习仓库(https://archive.ics.uci.edu/ml/index.php)中获取的。也可到网盘中下载(https://pan.baidu.com/s/1nv2xuVpXWHC1HUdS1c5QaQ)提取码:d4im。
Pima Indians是一个分类问题的数据集,主要记录了印第安人最近五年内是否患有糖尿病的医疗数据。
1.1使用标准Python类库导入数据
Python提供了一个标准的类库CSV,用来处理CSV文件。
from csv import reader
#python标准库导入数据
filename = 'pima_data.csv'
with open(filename, 'rt') as raw_data:
readers = reader(raw_data, delimiter=",")
x = list(readers)
data = np.array(x).astype('float')
print(data.shape)
代码比较简单,此处不做过多赘述。
运行结果:
(768, 9)
1.2使用Numpy导入数据
使用numpy的loadtxt()方法导入数据。使用这个函数处理的数据没有文件头,并且所有的数据结构都一样,也就是说,数据类型都一样。
import numpy as np
#使用Numpy导入数据
from numpy import loadtxt
filename = 'pima_data.csv'
with open(filename, 'rt') as raw_data:
data = loadtxt(raw_data, delimiter=',')
print(data.shape)
loadtxt中的第一个参数为数据实例,第二个参数为分隔符。
输出结果同上
(768, 9)
1.3使用Pandas导入数据
通过Pandas来导入CSV文件要使用pandas.read_csv()函数。这个函数的返回值使Data Frame。在机器学习的项目中,经常利用pandas来做数据处理和准备工作。因此,推荐使用Pandas来导入数据。
#推荐使用!!!!
#使用Pandas导入数据
from pandas import read_csv
filename = 'pima_data.csv'
names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class']
#设置文件头
data = read_csv(filename, names=names)
print(data.shape)
print(data.head(10))
使用Pandas导入数据可以设置文件头,便于后续数据理解。read_csv()方法有两个参数,一个是文件名,一个是文件头数组。
输出结果同上
(768, 9)
2.数据理解
为了得到更准确的结果,必须理解数据的特征、分布情况,以及需要解决的问题,一边建立相关的算法模型并进行优化。
2.1数据基本属性
对数据的简单审视,是加强对数据理解最有效的方法之一。通过对数据的观察,可以发现数据的内在关系。这些发现有助于对数据进行整理。
2.1.1查看前10行数据
使用的数据集依然是Pima Indians数据集:
from pandas import read_csv
filename = 'pima_data.csv'
names = ['preg','plas','pres','skin','test','mass', 'pedi','age','class']
data = read_csv(filename,names=names)
#查看前十行数据
print(data.head(10))
先使用pandas导入数据集,再使用print函数数据data的head属性以查看前10行数据。
输出结果:
preg plas pres skin test mass pedi age class
0 6 148 72 35 0 33.6 0.63 50 1
1 1 85 66 29 0 26.6 0.35 31 0
2 8 183 64 0 0 23.3 0.67 32 1
3 1 89 66 23 94 28.1 0.17 21 0
4 0 137 40 35 168 43.1 2.29 33 1
5 5 116 74 0 0 25.6 0.20 30 0
6 3 78 50 32 88 31.0 0.25 26 1
7 10 115 0 0 0 35.3 0.13 29 0
8 2 197 70 45 543 30.5 0.16 53 1
9 8 125 96 0 0 0.0 0.23 54 1
2.1.2查看数据维度,数据属性和类型:
'''
数据维度
'''
#查看数据维度
#通过DATa Frame的shape属性来查看数据集中有多少行多少列
print(data.shape)
'''
数据属性和类型
'''
#查看数据属性和类型
#通过DATa Frame的Type属性来查看每一个字段的数据类型
print(data.dtypes)
运行结果:
(768, 9)
preg int64
plas int64
pres int64
skin int64
test int64
mass float64
pedi float64
age int64
class int64
dtype: object
2.1.3查看数据描述性统计
通过DataFrame的describe()方法来查看描述性统计的内容。包括:数据数量、平均值、标准方差、最小值、下四分位数、中位数、上四分位数、最大值。(省略前方读取数据部分)
from pandas import set_option
'''
描述性统计
'''
#通过DATa frame的describe()方法来查看描述性统计
#数据记录数、平均住、标准方差、最小值、下四分位数、中位数、上四分位数、最大值
set_option('display.width',100)
#设置数据的精确度
set_option('precision',2)
print("数据描述性分析:")
print(data.describe())
运行结果:
数据描述性分析:
preg plas pres skin test mass pedi age class
count 768.00 768.00 768.00 768.00 768.00 768.00 768.00 768.00 768.00
mean 3.85 120.89 69.11 20.54 79.80 31.99 0.47 33.24 0.35
std 3.37 31.97 19.36 15.95 115.24 7.88 0.33 11.76 0.48
min 0.00 0.00 0.00 0.00 0.00 0.00 0.08 21.00 0.00
25% 1.00 99.00 62.00 0.00 0.00 27.30 0.24 24.00 0.00
50% 3.00 117.00 72.00 23.00 30.50 32.00 0.37 29.00 0.00
75% 6.00 140.25 80.00 32.00 127.25 36.60 0.63 41.00 1.00
max 17.00 199.00 122.00 99.00 846.00 67.10 2.42 81.00 1.00
2.2数据相关性和分布分析
2.2.1数据相关矩阵
数据属性的相关性是指数据的两个属性是否相互影响,以及这种影响是何种方式。常用皮尔逊相关系数来表示两个属性之间的关联性,它介于(-1,1)。当数据的关联性比较高时,有些算法(如Liner、逻辑回归算法等)的性能会降低。所以需要查看一下算法的关联性。使用Data Frame的corr()方法来计算数据属性之间的相关矩阵。
print("数据属性的相关性:")
print(data.corr(method='pearson'))
结果如下:
数据属性的相关性:
preg plas pres skin test mass pedi age class
preg 1.00 0.13 0.14 -0.08 -0.07 0.02 -0.03 0.54 0.22
plas 0.13 1.00 0.15 0.06 0.33 0.22 0.14 0.26 0.47
pres 0.14 0.15 1.00 0.21 0.09 0.28 0.04 0.24 0.07
skin -0.08 0.06 0.21 1.00 0.44 0.39 0.18 -0.11 0.07
test -0.07 0.33 0.09 0.44 1.00 0.20 0.19 -0.04 0.13
mass 0.02 0.22 0.28 0.39 0.20 1.00 0.14 0.04 0.29
pedi -0.03 0.14 0.04 0.18 0.19 0.14 1.00 0.03 0.17
age 0.54 0.26 0.24 -0.11 -0.04 0.04 0.03 1.00 0.24
class 0.22 0.47 0.07 0.07 0.13 0.29 0.17 0.24 1.00
2.2.2数据分布分析
通过分析数据的高斯分布情况来确认数据的偏离情况。使用Data Frame的skew()方法来计算所有数据属性的高斯分布偏离情况。
print("数据的高斯分布偏离情况:")
print(data.skew())
结果如下:
数据的高斯分布偏离情况:
preg 0.90
plas 0.17
pres -1.84
skin 0.11
test 2.27
mass -0.43
pedi 1.92
age 1.13
class 0.64
dtype: float64
3.数据可视化
对数据进行理解最快、最有效的方式是通过数据的可视化。我们将使用Matplotlib来可视化数据以更好地理解数据。
3.1单一图表
3.1.1直方图
直方图使用较多,此处不做过多介绍。
from pandas import read_csv
import matplotlib.pyplot as plt
filename = 'pima_data.csv'
names = ['preg','plas','pres','skin','test','mass', 'pedi','age','class']
data = read_csv(filename,names=names)
'''
直方图
'''
data.hist()
plt.show()
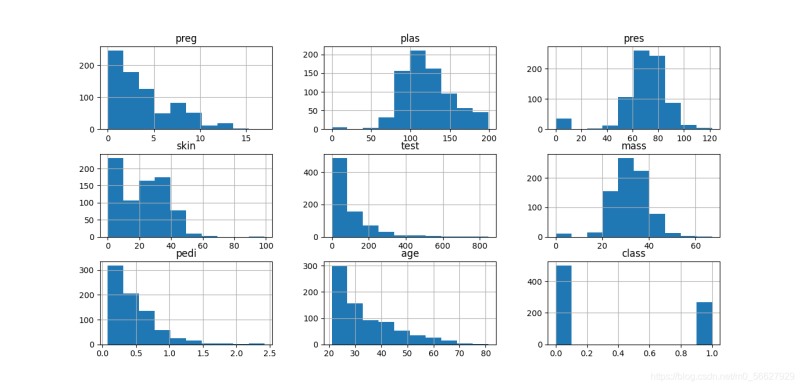
3.1.2密度图
密度图是一种表现与数据值对应的边界或域对象的图形表示方法,一般用于呈现连续变量。密度图类似于对直方图进行抽象,用平滑的线来描述数据的分布。
'''
密度图
'''
data.plot(kind='density',subplots=True,layout=(3,3),sharex=False,sharey=False)
plt.show()
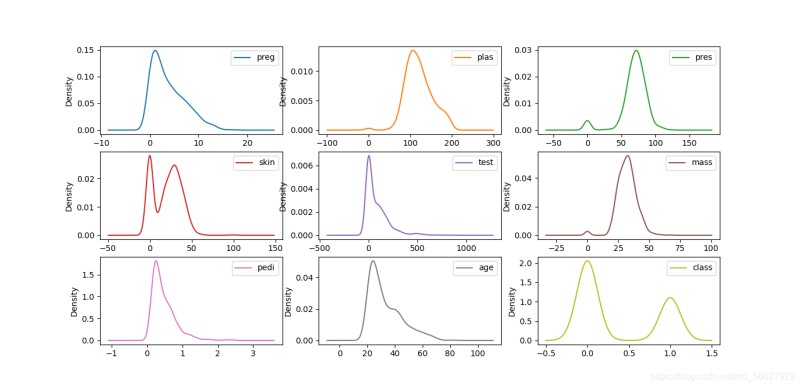
3.1.3箱线图
箱线图又称盒须图、盒式图或箱行图,是一种用于显示一组数据分散情况的统计图。
'''
箱线图
'''
data.plot(kind='box',subplots=True,layout=(3,3),sharex=False,sharey=False)
plt.show()
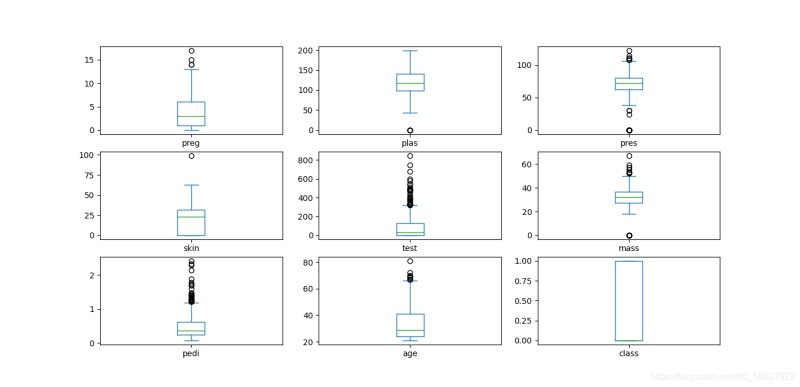
3.2多重图表
3.2.1相关矩阵图
from pandas import read_csv
import matplotlib.pyplot as plt
import numpy as np
filename = 'pima_data.csv'
names = ['preg','plas','pres','skin','test','mass','pedi','age','class']
data = read_csv(filename,names=names)
#相关矩阵图
correlations = data.corr()
fig = plt.figure()
ax = fig.add_subplot(111)
cax = ax.matshow(correlations, vmin=-1, vmax=1)
fig.colorbar(cax)
ticks = np.arange(0,9,1)
ax.set_xticks(ticks)
ax.set_yticks(ticks)
ax.set_xticklabels(names)
ax.set_yticklabels(names)
plt.show()
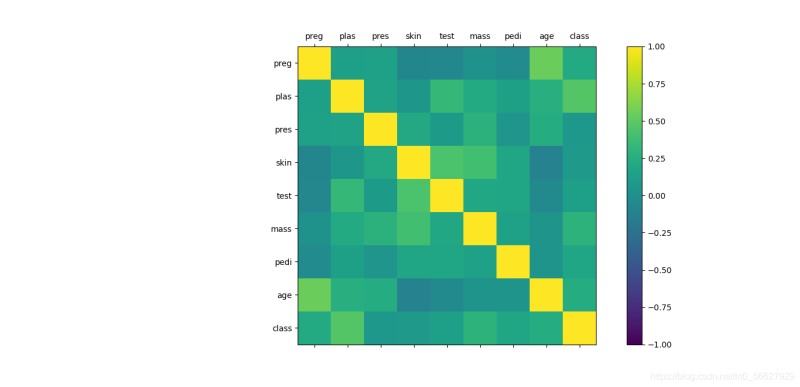
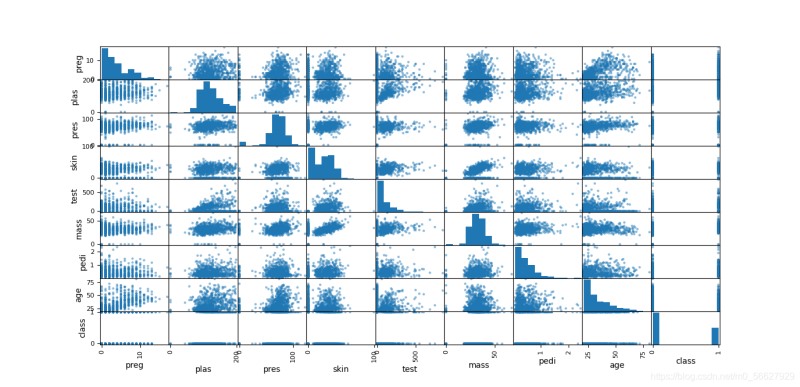
3.2.2散点矩阵图
from pandas import read_csv
import matplotlib.pyplot as plt
import numpy as np
from pandas.plotting import scatter_matrix
filename = 'pima_data.csv'
names = ['preg','plas','pres','skin','test','mass','pedi','age','class']
data = read_csv(filename,names=names)
scatter_matrix(data)
plt.show()
总结
本文主要讲了机器学习项目开始前的一些准备工作:导入数据,数据理解和数据可视化。导入数据有三种方法:Python库函数,Numpy和Pandas导入,推荐使用Panads导入CSV文件。数据理解包括查看数据的一些基本属性以及查看数据相关矩阵和高斯分布情况。数据可视化主要介绍了Matplotlib的一些常用方法。
到此这篇关于Python机器学习(二)数据理解的文章就介绍到这了,更多相关Python机器学习(二)内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
您可能感兴趣的文章:- 详解python数据结构之队列Queue
- 详解python数据结构之栈stack
- python数据类型相关知识扩展
- Python数据类型最全知识总结
- python数据处理——对pandas进行数据变频或插值实例
- python入门课程第四讲之内置数据类型有哪些


 咨 询 客 服
咨 询 客 服