Spark Streaming VS Structured Streaming
Spark Streaming是Spark最初的流处理框架,使用了微批的形式来进行流处理。
提供了基于RDDs的Dstream API,每个时间间隔内的数据为一个RDD,源源不断对RDD进行处理来实现流计算
Apache Spark 在 2016 年的时候启动了 Structured Streaming 项目,一个基于 Spark SQL 的全新流计算引擎 Structured Streaming,让用户像编写批处理程序一样简单地编写高性能的流处理程序。
Structured Streaming是Spark2.0版本提出的新的实时流框架(2.0和2.1是实验版本,从Spark2.2开始为稳定版本)
从Spark-2.X版本后,Spark Streaming就进入维护模式,看见Spark已经将大部分精力投入到了全新的Structured Streaming中,而一些新特性也只有Structured Streaming才有,这样Spark才有了与Flink一战的能力。
1、Spark Streaming 不足
Processing Time 而不是 Event Time
首先解释一下,Processing Time 是数据到达 Spark 被处理的时间,而 Event Time 是数据自带的属性,一般表示数据产生于数据源的时间。比如 IoT 中,传感器在 12:00:00 产生一条数据,然后在 12:00:05 数据传送到 Spark,那么 Event Time 就是 12:00:00,而 Processing Time 就是 12:00:05。我们知道 Spark Streaming 是基于 DStream 模型的 micro-batch 模式,简单来说就是将一个微小时间段,比如说 1s,的流数据当前批数据来处理。如果我们要统计某个时间段的一些数据统计,毫无疑问应该使用 Event Time,但是因为 Spark Streaming 的数据切割是基于 Processing Time,这样就导致使用 Event Time 特别的困难。
Complex, low-level api
这点比较好理解,DStream (Spark Streaming 的数据模型)提供的 API 类似 RDD 的 API 的,非常的 low level。当我们编写 Spark Streaming 程序的时候,本质上就是要去构造 RDD 的 DAG 执行图,然后通过 Spark Engine 运行。这样导致一个问题是,DAG 可能会因为开发者的水平参差不齐而导致执行效率上的天壤之别。这样导致开发者的体验非常不好,也是任何一个基础框架不想看到的(基础框架的口号一般都是:你们专注于自己的业务逻辑就好,其他的交给我)。这也是很多基础系统强调 Declarative 的一个原因。
reason about end-to-end application
这里的 end-to-end 指的是直接 input 到 out,比如 Kafka 接入 Spark Streaming 然后再导出到 HDFS 中。DStream 只能保证自己的一致性语义是 exactly-once 的,而 input 接入 Spark Streaming 和 Spark Straming 输出到外部存储的语义往往需要用户自己来保证。而这个语义保证写起来也是非常有挑战性,比如为了保证 output 的语义是 exactly-once 语义需要 output 的存储系统具有幂等的特性,或者支持事务性写入,这个对于开发者来说都不是一件容易的事情。
批流代码不统一
尽管批流本是两套系统,但是这两套系统统一起来确实很有必要,我们有时候确实需要将我们的流处理逻辑运行到批数据上面。关于这一点,最早在 2014 年 Google 提出 Dataflow 计算服务的时候就批判了 streaming/batch 这种叫法,而是提出了 unbounded/bounded data 的说法。DStream 尽管是对 RDD 的封装,但是我们要将 DStream 代码完全转换成 RDD 还是有一点工作量的,更何况现在 Spark 的批处理都用 DataSet/DataFrame API 了。
2.、Structured Streaming 优势
相对的,来看下Structured Streaming优势:
- 简洁的模型。Structured Streaming 的模型很简洁,易于理解。用户可以直接把一个流想象成是无限增长的表格。
- 一致的 API。由于和 Spark SQL 共用大部分 API,对 Spaprk SQL 熟悉的用户很容易上手,代码也十分简洁。同时批处理和流处理程序还可以共用代码,不需要开发两套不同的代码,显著提高了开发效率。
- 卓越的性能。Structured Streaming 在与 Spark SQL 共用 API 的同时,也直接使用了 Spark SQL 的 Catalyst 优化器和 Tungsten,数据处理性能十分出色。此外,Structured Streaming 还可以直接从未来 Spark SQL 的各种性能优化中受益。
- 多语言支持。Structured Streaming 直接支持目前 Spark SQL 支持的语言,包括 Scala,Java,Python,R 和 SQL。用户可以选择自己喜欢的语言进行开发。
- 同样能支持多种数据源的输入和输出,Kafka、flume、Socket、Json。
- 基于Event-Time,相比于Spark Streaming的Processing-Time更精确,更符合业务场景。
- Event time 事件时间: 就是数据真正发生的时间,比如用户浏览了一个页面可能会产生一条用户的该时间点的浏览日志。
- Process time 处理时间: 则是这条日志数据真正到达计算框架中被处理的时间点,简单的说,就是你的Spark程序是什么时候读到这条日志的。
- 事件时间是嵌入在数据本身中的时间。对于许多应用程序,用户可能希望在此事件时间操作。例如,如果要获取IoT设备每分钟生成的事件数,则可能需要使用生成数据的时间(即数据中的事件时间),而不是Spark接收他们的时间。事件时间在此模型中非常自然地表示 - 来自设备的每个事件都是表中的一行,事件时间是该行中的一个列值。
- 支持spark2的dataframe处理。
- 解决了Spark Streaming存在的代码升级,DAG图变化引起的任务失败,无法断点续传的问题。
- 基于SparkSQL构建的可扩展和容错的流式数据处理引擎,使得实时流式数据计算可以和离线计算采用相同的处理方式(DataFrameSQL)。
- 可以使用与静态数据批处理计算相同的方式来表达流计算。
底层原理完全不同
Spark Streaming采用微批的处理方法。每一个批处理间隔的为一个批,也就是一个RDD,我们对RDD进行操作就可以源源不断的接收、处理数据。

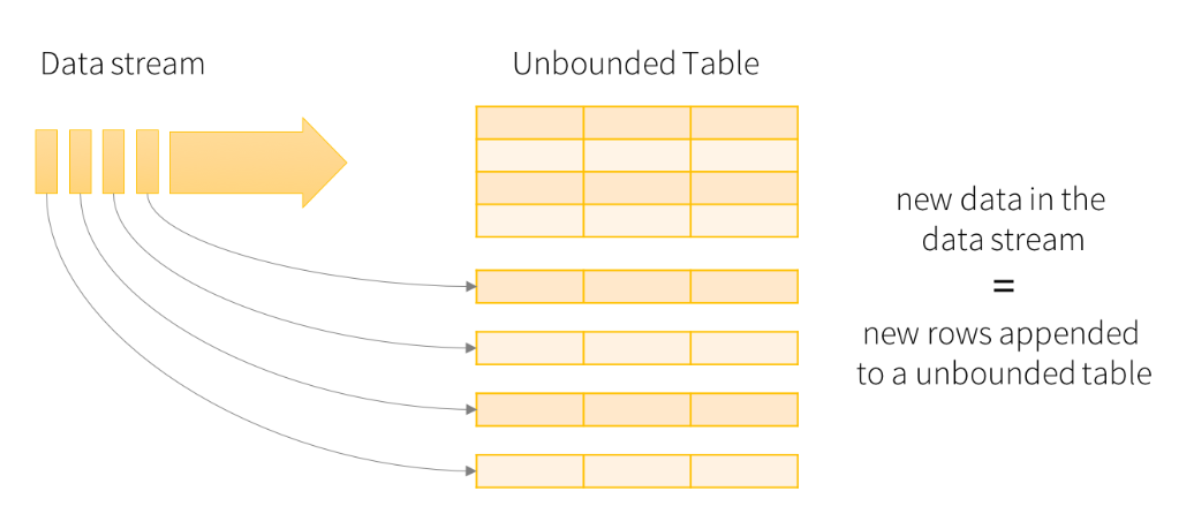
Structured Streaming将实时数据当做被连续追加的表。流上的每一条数据都类似于将一行新数据添加到表中。
Spark 3.0.0发布以后 全新的Structured Streaming UI诞生,可见未来的Structured Streaming将不断迎来进步。
总结
到此这篇关于使用Spark进行实时流计算的方法的文章就介绍到这了,更多相关Spark实时流计算内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
您可能感兴趣的文章:- SparkGraphx计算指定节点的N度关系节点源码


 咨 询 客 服
咨 询 客 服