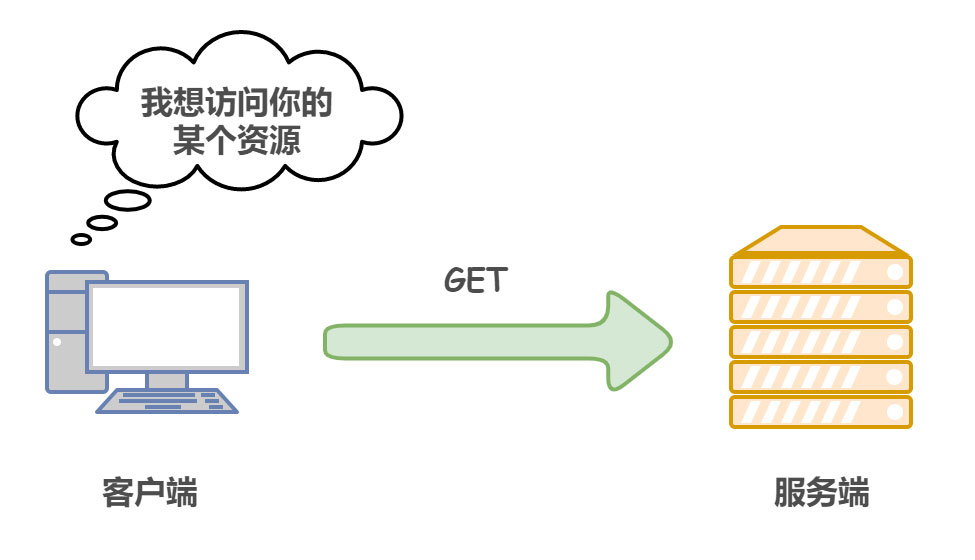
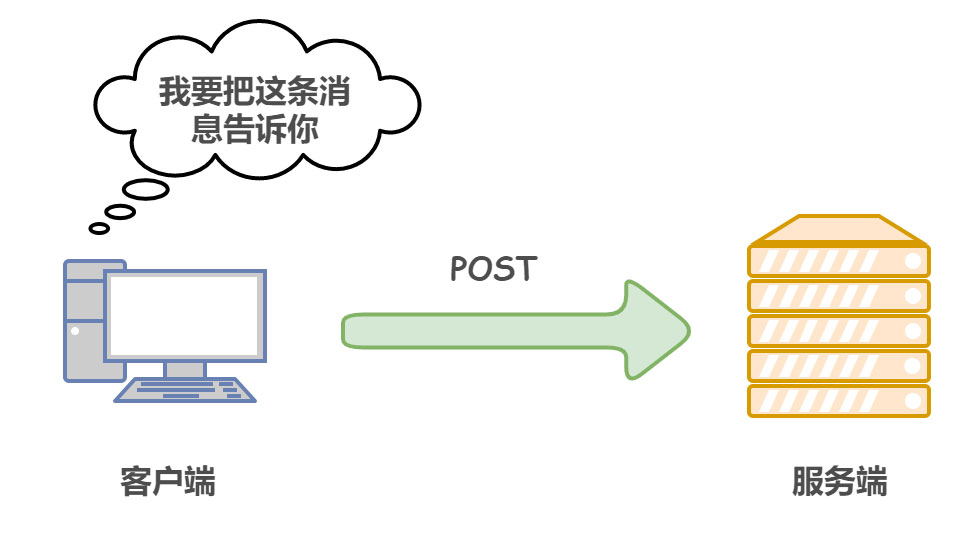
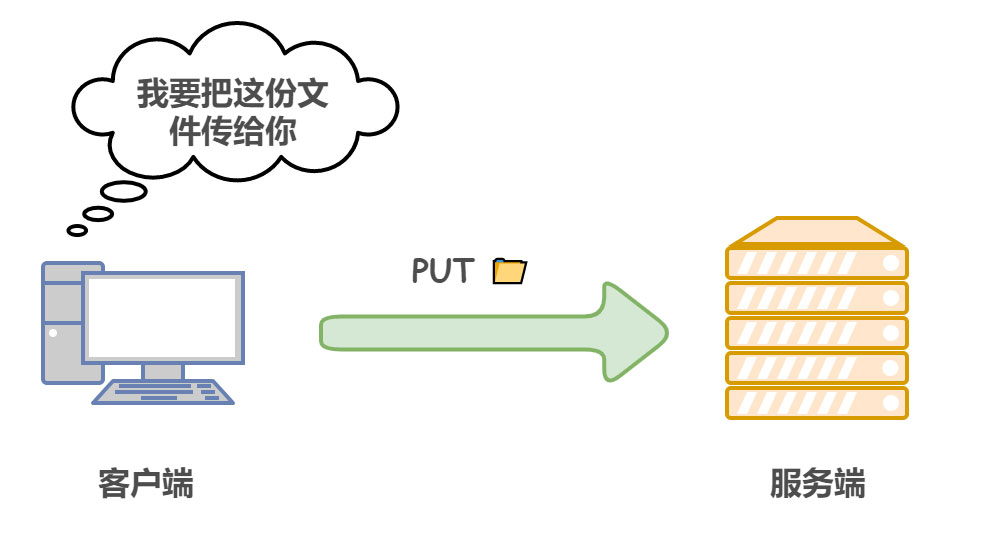
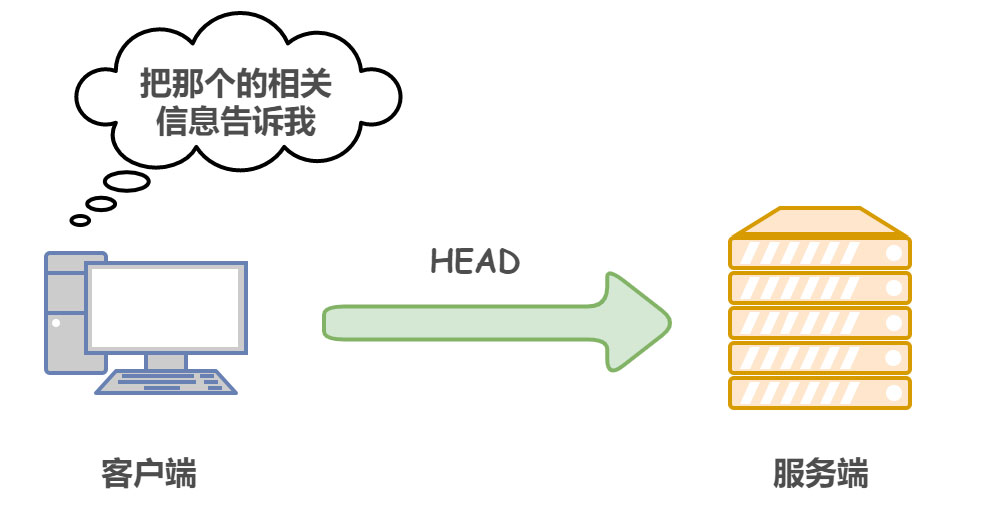
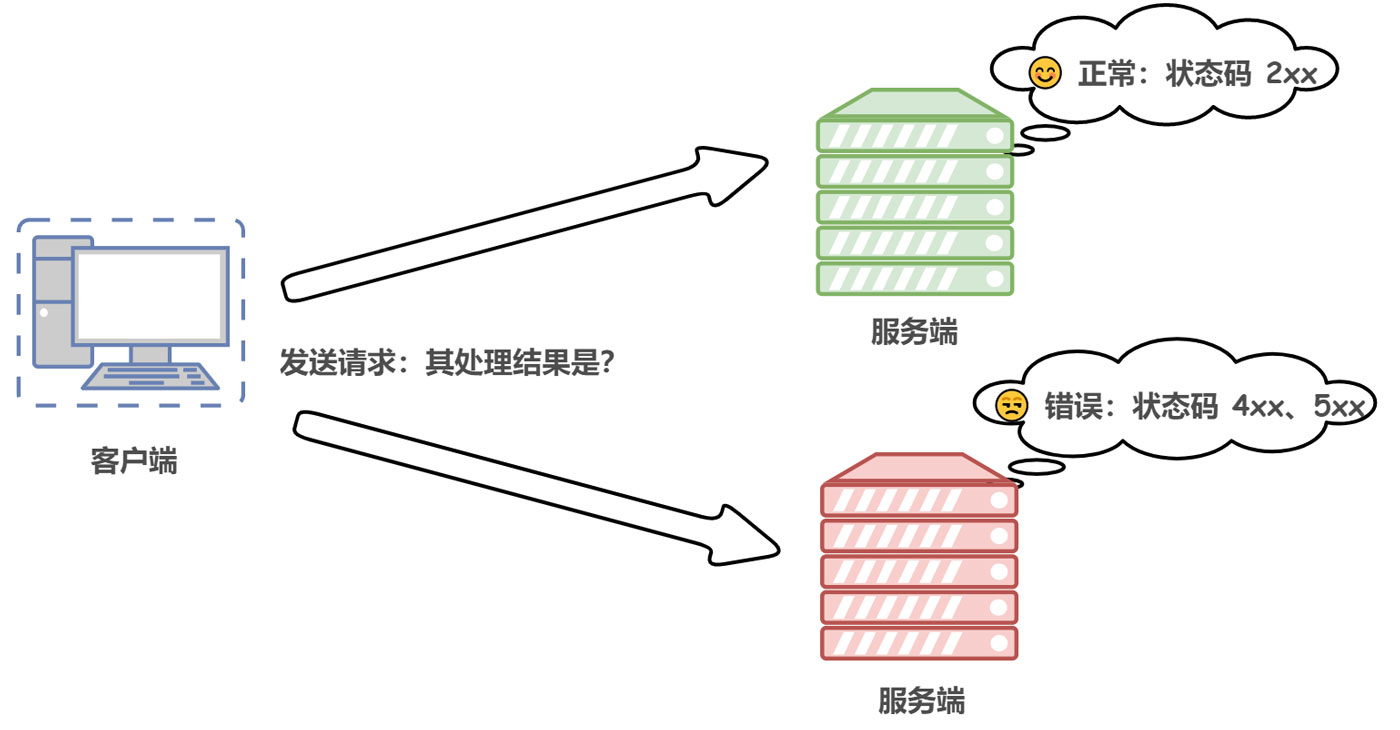
| 类别 | 原因短语 | |
|---|---|---|
| 1xx | Informational 信息性状态码 | 接收的请求正在处理 |
| 2xx | Success 成功状态码 | 请求正常处理完毕 |
| 3xx | Redirection 重定向状态码 | 需要进行附加操作以完成请求 |
| 4xx | Client Error 客户端错误状态码 | 服务器无法处理请求 |
| 5xx | Server Error 服务器错误状态码 | 服务器处理请求出错 |
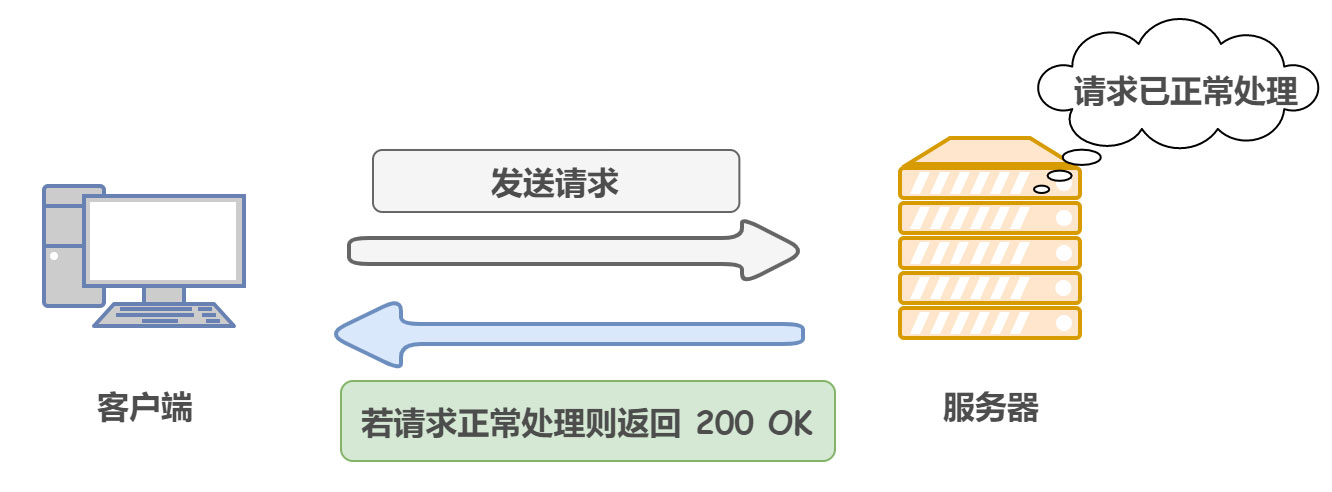
2xx:请求正常处理完毕
200 OK:客户端请求成功
204 No Content:无内容。服务器成功处理,但未返回内容。一般用在只是客户端向服务器发送信息,而服务器不用向客户端返回什么信息的情况。不会刷新页面。
206 Partial Content:服务器已经完成了部分 GET 请求(客户端进行了范围请求)。响应报文中包含 Content-Range 指定范围的实体内容

3xx:需要进行附加操作以完成请求(重定向)
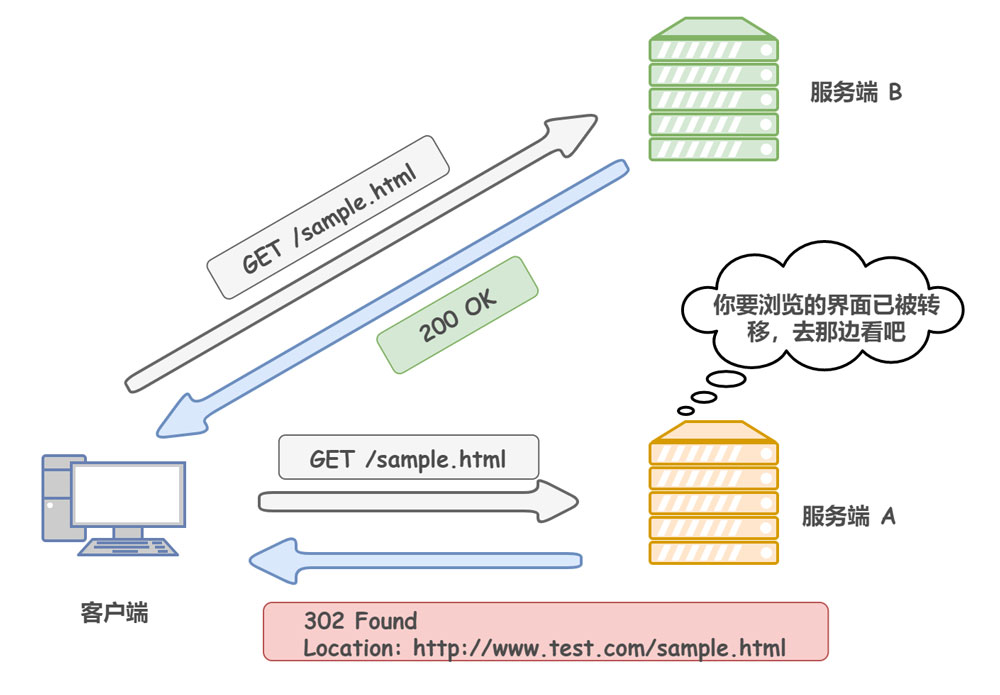
301 Moved Permanently:永久重定向,表示请求的资源已经永久的搬到了其他位置。302 Found:临时重定向,表示请求的资源临时搬到了其他位置303 See Other:临时重定向,应使用GET定向获取请求资源。303功能与302一样,区别只是303明确客户端应该使用GET访问304 Not Modified:表示客户端发送附带条件的请求(GET方法请求报文中的IF…)时,条件不满足。返回304时,不包含任何响应主体。虽然304被划分在3XX,但和重定向一毛钱关系都没有307 Temporary Redirect:临时重定向,和302有着相同含义。POST不会变成GET4xx:客户端错误
400 Bad Request:客户端请求有语法错误,服务器无法理解。401 Unauthorized:请求未经授权,这个状态代码必须和 WWW-Authenticate 报头域一起使用。403 Forbidden:服务器收到请求,但是拒绝提供服务404 Not Found:请求资源不存在。比如,输入了错误的 URL415 Unsupported media type:不支持的媒体类型5xx:服务器端错误,服务器未能实现合法的请求。
500 Internal Server Error:服务器发生不可预期的错误。503 Server Unavailable:服务器当前处于超负载或正在停机维护,暂时不能处理客户端的请求,一段时间后可能恢复正常HTTP 响应头
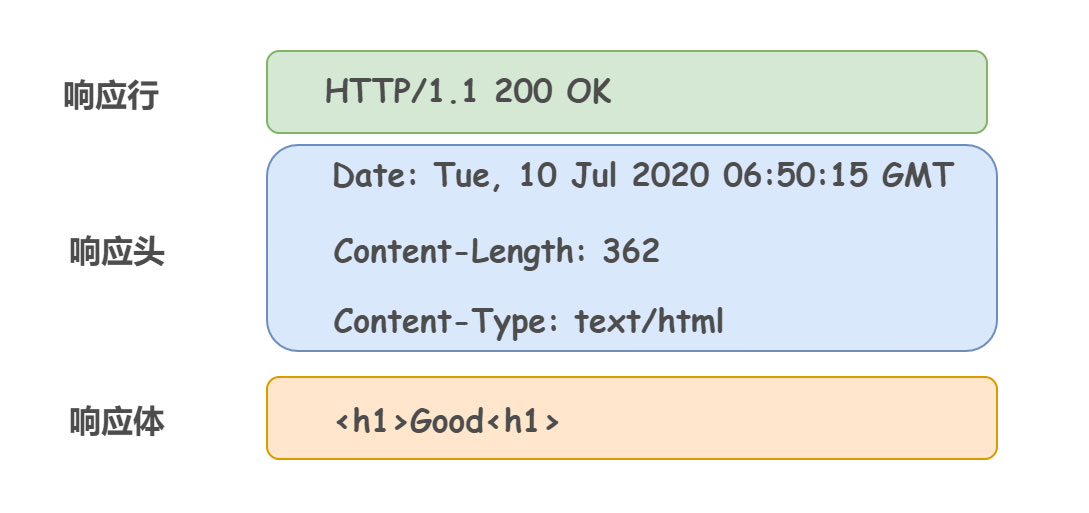
响应头也是用键值对 k:v,用于补充响应的附加信息、服务器信息,以及对客户端的附加要求等。
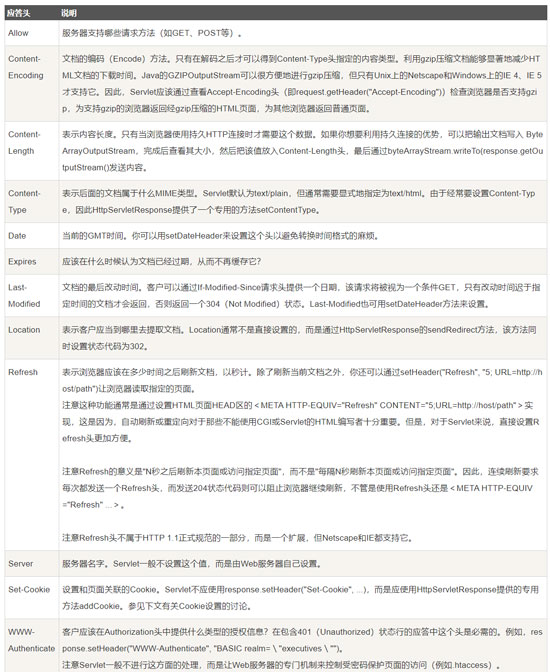
这里着重说明一下 Location 这个字段,可以将响应接收方引导至与某个 URI 位置不同的资源。通常来说,该字段会配合 3xx:Redirection 的响应,提供重定向的 URI。
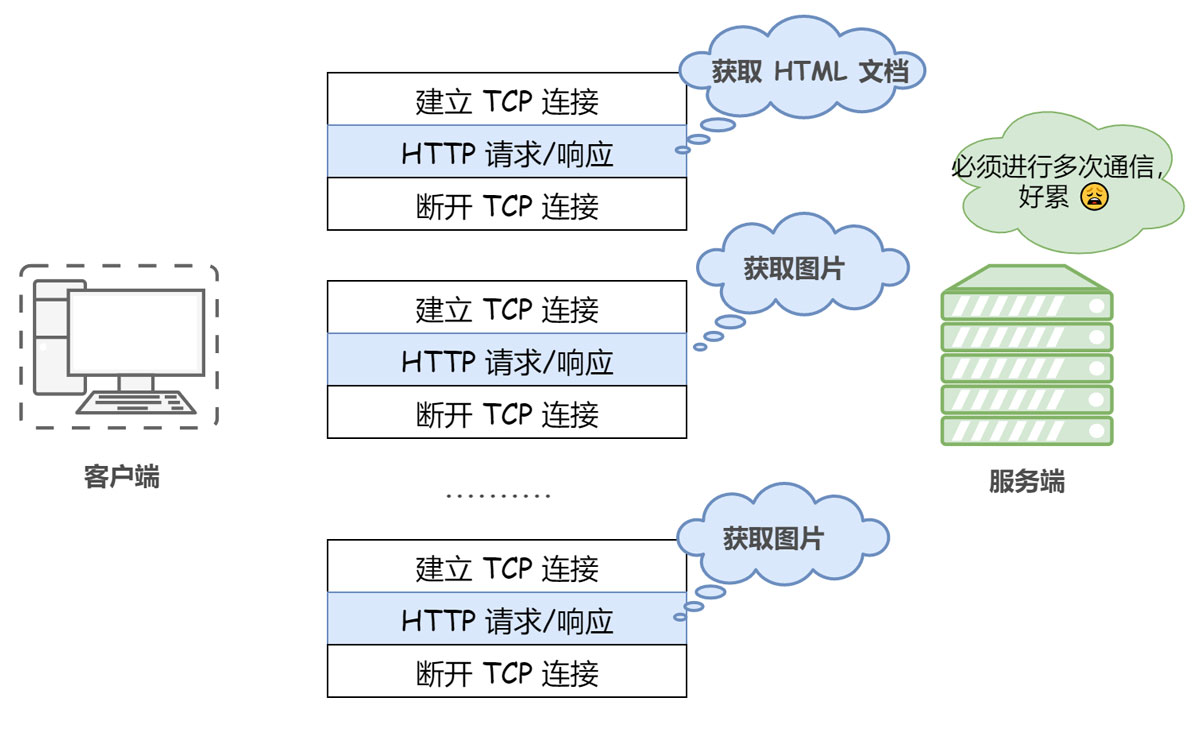
① 短连接(非持久连接)
在 HTTP 协议的初始版本(HTTP/1.0)中,客户端和服务器每进行一次 HTTP 会话,就建立一次连接,任务结束就中断连接。当客户端浏览器访问的某个 HTML 或其他类型的 Web 页中包含有其他的 Web 资源(如JavaScript 文件、图像文件、CSS文件等),每遇到这样一个 Web 资源,浏览器就会重新建立一个 HTTP 会话。这种方式称为短连接(也称非持久连接)。
也就是说每次 HTTP 请求都要重新建立一次连接。由于 HTTP 是基于 TCP/IP 协议的,所以连接的每一次建立或者断开都需要 TCP 三次握手或者 TCP 四次挥手的开销。
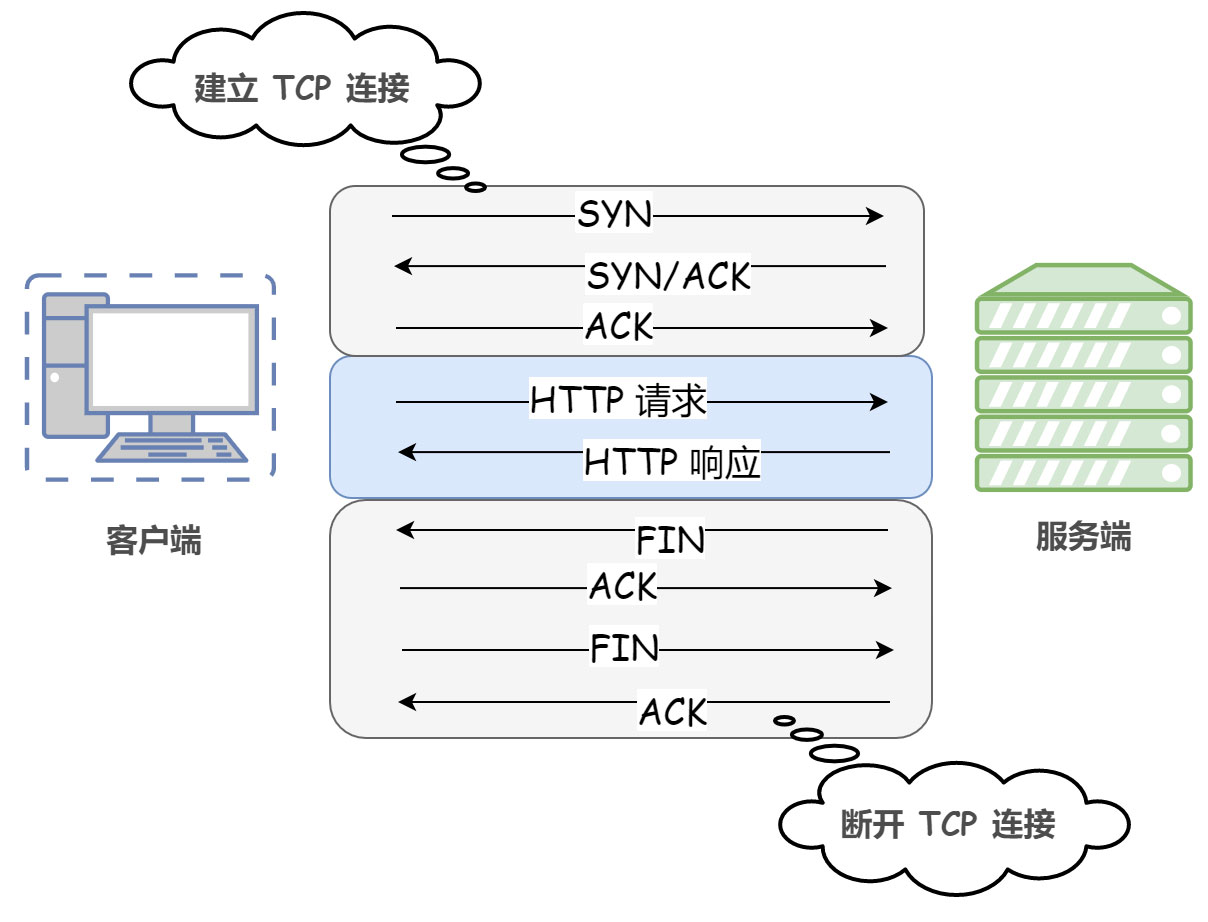
显然,这种方式存在巨大的弊端。比如访问一个包含多张图片的 HTML 页面,每请求一张图片资源就会造成无谓的 TCP 连接的建立和断开,大大增加了通信量的开销
② 长连接(持久连接)
从 HTTP/1.1 起,默认使用长连接也称持久连接 keep-alive。使用长连接的 HTTP 协议,会在响应头加入这行代码:Connection:keep-alive
在使用长连接的情况下,当一个网页打开完成后,客户端和服务器之间用于传输 HTTP 数据的 TCP 连接不会关闭,客户端再次访问这个服务器时,会继续使用这一条已经建立的连接。Keep-Alive 不会永久保持连接,它有一个保持时间,可以在不同的服务器软件(如 Apache)中设定这个时间。实现长连接需要客户端和服务端都支持长连接。
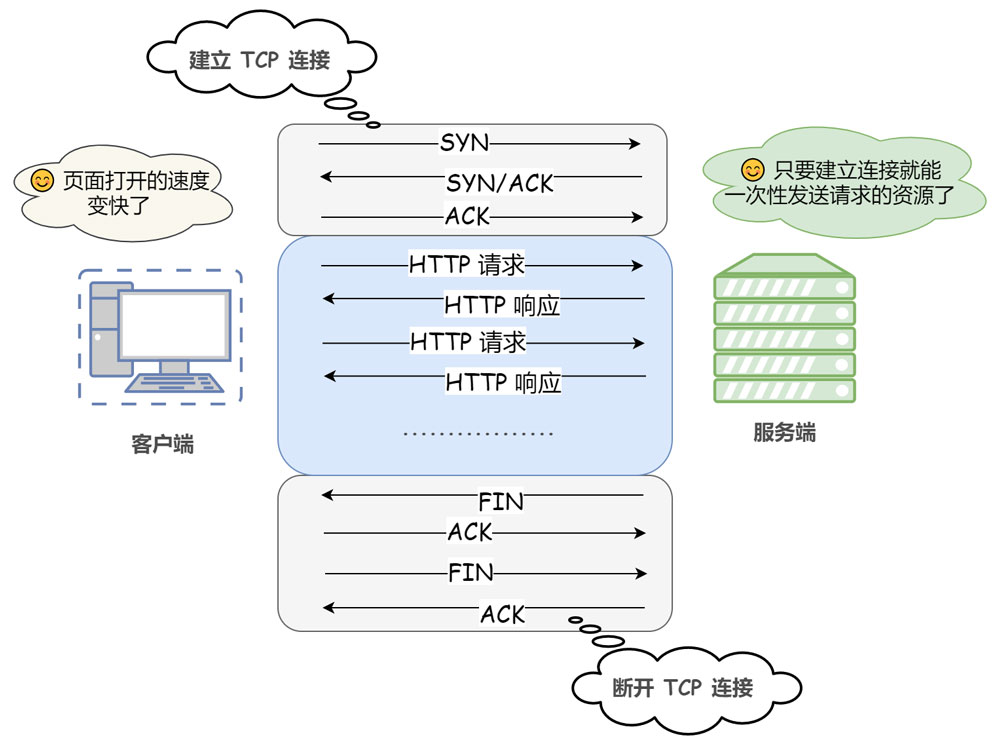
HTTP 协议的长连接和短连接,实质上是 TCP 协议的长连接和短连接。
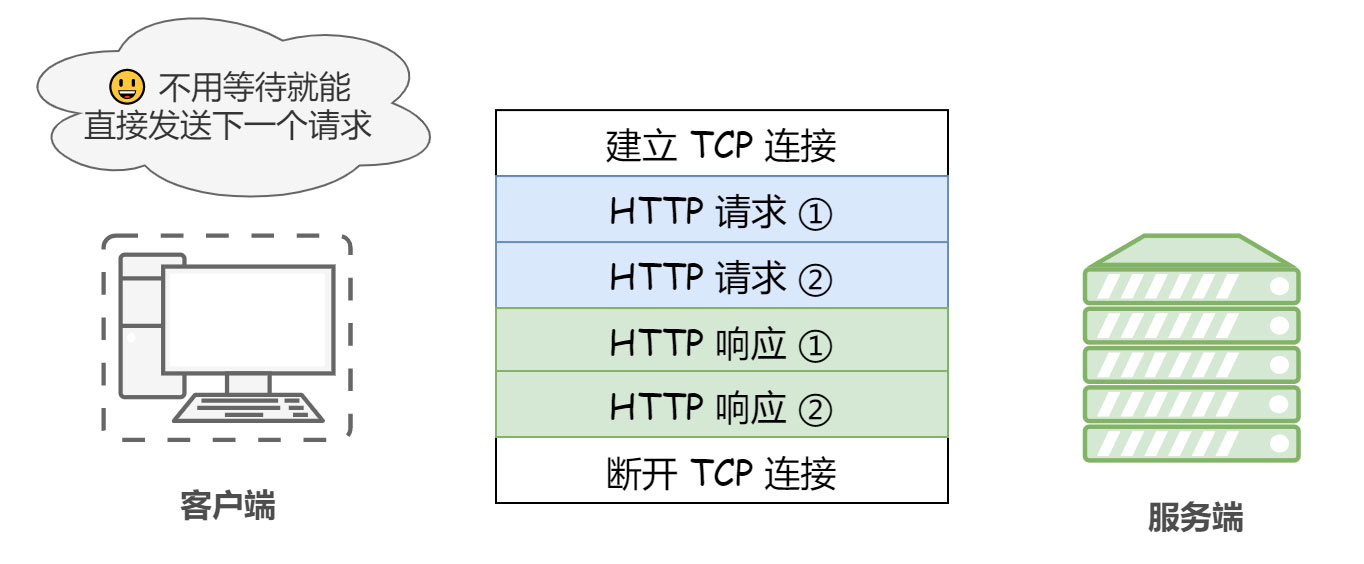
③ 流水线(管线化)
默认情况下,HTTP 请求是按顺序发出的,下一个请求只有在当前请求收到响应之后才会被发出。由于受到网络延迟和带宽的限制,在下一个请求被发送到服务器之前,可能需要等待很长时间。
持久连接使得多数请求以流水线(管线化 pipeline)方式发送成为可能,即在同一条持久连接上连续发出请求,而不用等待响应返回后再发送,这样就可以做到同时并行发送多个请求,而不需要一个接一个地等待响应了。
HTTP 协议是无状态协议。也就是说他不对之前发生过的请求和响应的状态进行管理,即无法根据之前的状态进行本次的请求处理。
这样就会带来一个明显的问题,如果 HTTP 无法记住用户登录的状态,那岂不是每次页面的跳转都会导致用户需要再次重新登录?
当然,不可否认,无状态的优点也很显著,由于不必保存状态,自然就减少了服务器的 CPU 及内存资源的消耗。另一方面,正式由于 HTTP 简单,所以才会被如此广泛应用。

这样,在保留无状态协议这个特征的同时,又要解决无状态导致的问题。方案有很多种,其中比较简单的方式就是使用 Cookie 技术。
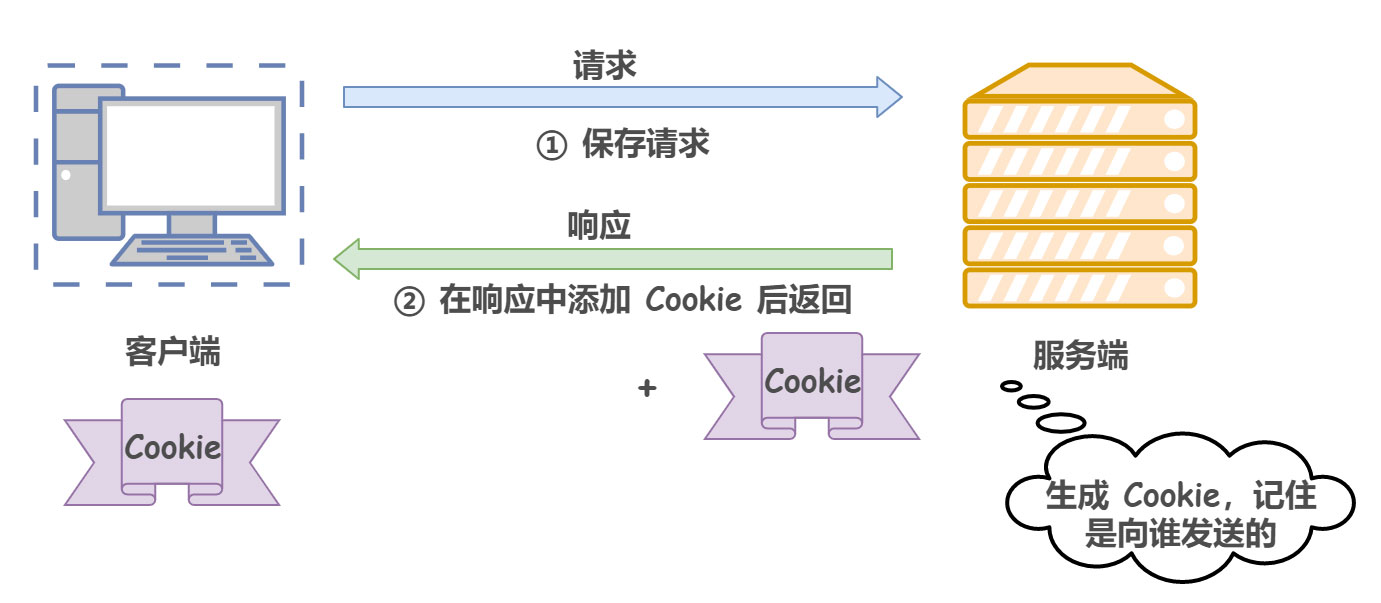
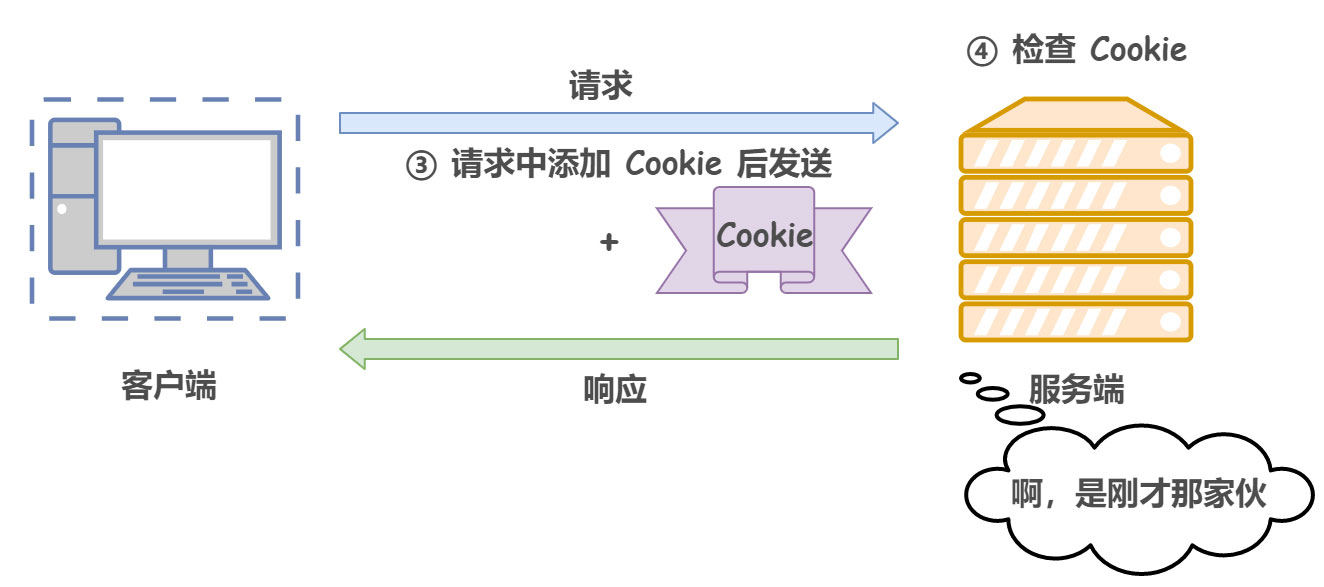
Cookie 通过在请求和响应报文中写入 Cookie 信息来控制客户端的状态。具体来说,Cookie 会根据从服务器端发送的响应报文中的一个叫作 Set-Cookie 的首部字段信息,通知客户端保存 Cookie。当下次客户端再往服务器发送请求时,客户端会自动在请求报文中加入 Cookie 值发送出去。服务器端收到客户端发来的 Cookie 后,会去检查究竟是哪一个客户端发来的连接请求,然后对比服务器上的记录,最后得到之前的状态信息。
形象来说,在客户端第一次请求后,服务器会下发一个装有客户信息的身份证,后续客户端请求服务器的时候,带上身份证,服务器就能认得了。
下图展示了发生 Cookie 交互的情景:
1)没有 Cookie 信息状态下的请求:
对应的 HTTP 请求报文(没有 Cookie 信息的状态)
GET /reader/ HTTP/1.1
Host: baidu.com
* 首部字段没有 Cookie 的相关信息
对应的 HTTP 响应报文(服务端生成 Cookie 信息)
HTTP/1.1 200 OK
Date: Thu, 12 Jul 2020 15:12:20 GMT
Server: Apache
Set-Cookie: sid=1342077140226; path=/; expires=Wed, 10-Oct-12 15:12:20 GMT>
Content-Type: text/plain; charset=UTF-8
2)第 2 次以后的请求(存有 Cookie 信息状态)
对应的 HTTP 请求报文(自动发送保存着的 Cookie 信息)
GET /image/ HTTP/1.1
Host: baidu.com
Cookie: sid=1342077140226
所谓断点续传指的是下载传输文件可以中断,之后重新下载时可以接着中断的地方开始下载,而不必从头开始下载。断点续传需要客户端和服务端都支持。
这是一个非常常见的功能,原理很简单,其实就是 HTTP 请求头中的字段 Range 和响应头中的字段 Content-Range 的简单使用。客户端一块一块的请求数据,最后将下载回来的数据块拼接成完整的数据。打个比方,浏览器请求服务器上的一个服务,所发出的请求如下:
假设服务器域名为www.baidu.com,文件名为 down.zip。
GET /down.zip HTTP/1.1
Accept: image/gif, image/x-xbitmap, image/jpeg, image/pjpeg, application/vnd.ms-
excel, application/msword, application/vnd.ms-powerpoint, */*
Accept-Language: zh-cn
Accept-Encoding: gzip, deflate
User-Agent: Mozilla/4.0 (compatible; MSIE 5.01; Windows NT 5.0)
Connection: Keep-Alive
服务器收到请求后,按要求寻找请求的文件,提取文件的信息,然后返回给浏览器,返回信息如下:
200
Content-Length=106786028
Accept-Ranges=bytes
Date=Mon, 30 Apr 2001 12:56:11 GMT
ETag=W/"02ca57e173c11:95b"
Content-Type=application/octet-stream
Server=Microsoft-IIS/5.0
Last-Modified=Mon, 30 Apr 2001 12:56:11 GMT
OK,那么既然要断点续传,客户端浏览器请求服务器的时候要多加一条信息 — 从哪里开始请求数据。 比如要求从 2000070 字节开始:
GET /down.zip HTTP/1.0
User-Agent: NetFox
RANGE: bytes=2000070-
Accept: text/html, image/gif, image/jpeg, *; q=.2, */*; q=.2
仔细看一下就会发现多了一行 RANGE: bytes=2000070-。这一行的意思就是告诉服务器 down.zip 这个文件从 2000070 字节开始传,前面的字节不用传了。
服务器收到这个请求以后,返回的信息如下:
206
Content-Length=106786028
Content-Range=bytes 2000070-106786027/106786028
Date=Mon, 30 Apr 2001 12:55:20 GMT
ETag=W/"02ca57e173c11:95b"
Content-Type=application/octet-stream
Server=Microsoft-IIS/5.0
Last-Modified=Mon, 30 Apr 2001 12:55:20 GMT
和前面服务器返回的信息比较一下,就会发现增加了一行: Content-Range=bytes 2000070-106786027/106786028。返回的代码也改为 206 了,而不再是 200 了。
到现在为止,我们已经了解到了 HTTP 具有相当优秀和方便的一面,然后,事务皆有两面性,他也是有不足之处的:
通信使用明文(不加密),内容可能被窃听
不验证通信对方的身份,因此有可能遭遇伪装
无法证明报文的完整性,所以有可能被篡改
这些问题不仅在 HTTP 上出现,其他未加密的协议中也存在类似问题,为了解决 HTTP 的痛点,HTTPS 应用而生,说白了 HTTP + 加密 + 认证 + 完整性保护就是 HTTPS 协议,关于 HTTPS 协议的内容也非常之多且重要,后续会单开一篇文章进行讲解。
以上就是详细HTTP协议的前世今生的详细内容,更多关于HTTP协议的资料请关注脚本之家其它相关文章!

 咨 询 客 服
咨 询 客 服