title: 正则表达式re.sub替换不完整的问题现象及其根本原因
toc: true
comment: true
date: 2018-08-27 21:48:22
tags: ["Python", "正则表达式"]
category: ["Python"]
---
问题描述
问题的起因来自于一段正则替换。为了从一段HTML代码里面提取出正文,去掉所有的HTML标签和属性,可以写一个Python函数:
import re
def remove_tag(html):
text = re.sub('.*?>', '', html, re.S)
return text
这段代码的使用了正则表达式的替换功能re.sub。这个函数的第一个参数表示需要被替换的内容的正则表达式,由于HTML标签都是使用尖括号包起来的,因此使用.*?>就可以匹配所有xxx yyy="zzz">和/xxx>。
第二个参数表示被匹配到的内容将要被替换成什么内容。由于我需要提取正文,那么只要把所有HTML标签都替换为空字符串即可。第三个参数就是需要被替换的文本,在这个例子中是HTML源代码段。
至于re.S,在4年前的一篇文章中我讲到了它的用法:https://www.jb51.net/article/146384.htm
现在使用一段HTML代码来测试一下:
import re
def remove_tag(html):
text = re.sub('.*?>', '', html, re.S)
return text
source_1 = '''
div class="content">今天的主角是a href="xxx">kingname/a>,我们掌声欢迎!/div>
'''
text = remove_tag(source_1)
print(text)
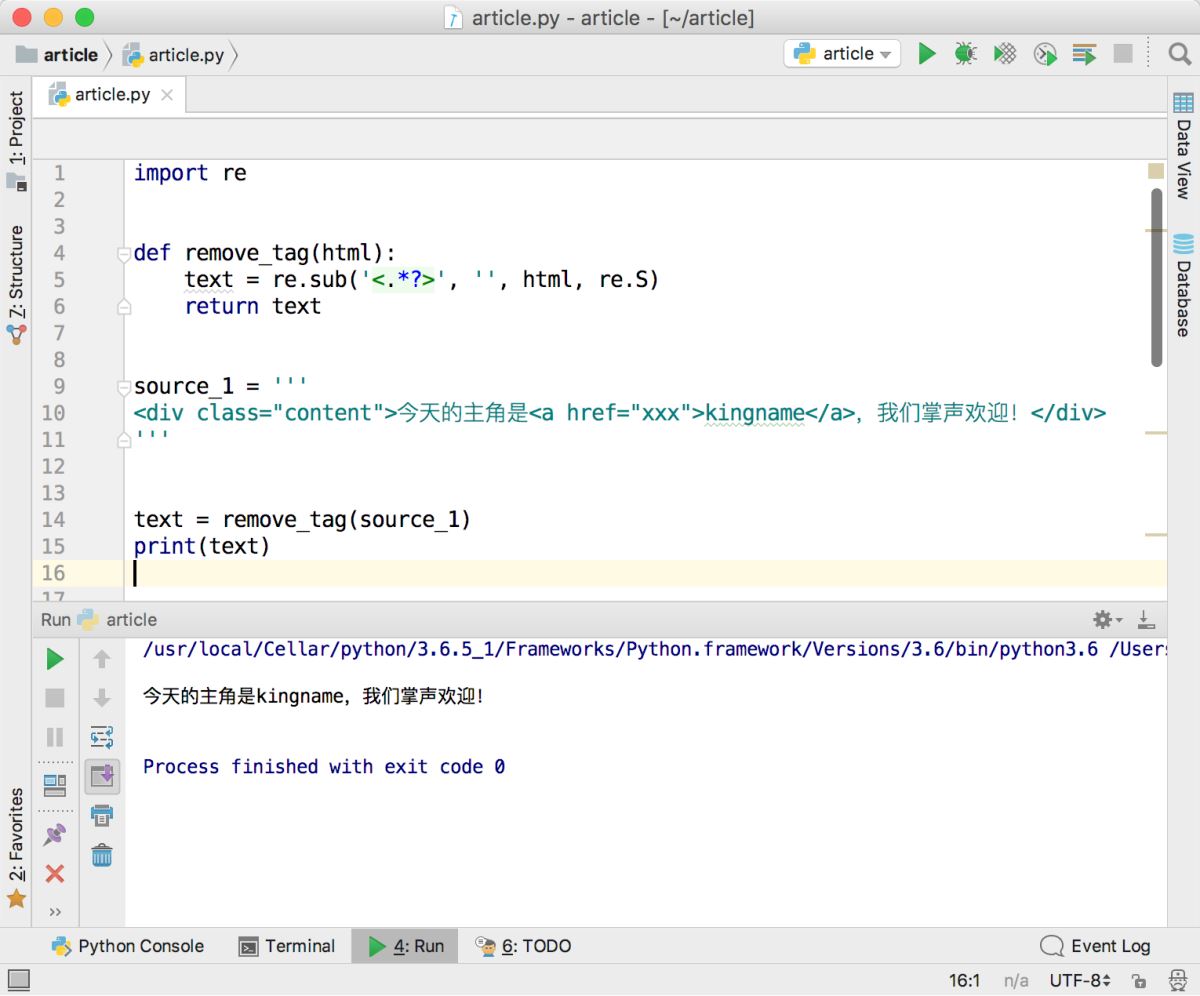
运行效果如下图所示,功能完全符合预期
再来测试一下代码中有换行符的情况:
import re
def remove_tag(html):
text = re.sub('.*?>', '', html, re.S)
return text
source_2 = '''
div class="content">
今天的主角是
a href="xxx">kingname/a>
,我们掌声欢迎!
/div>
'''
text = remove_tag(source_2)
print(text)
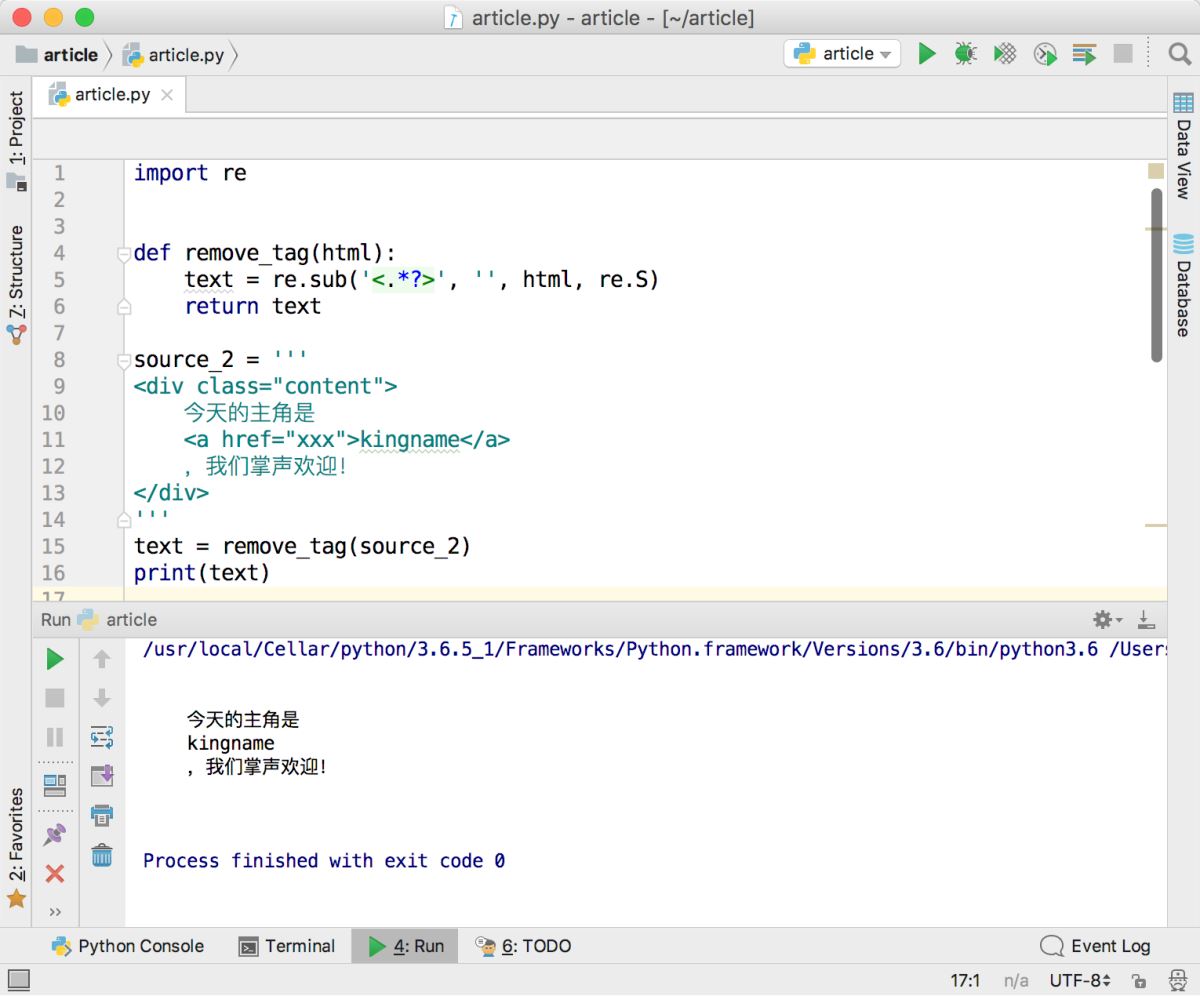
运行效果如下图所示,完全符合预期。
经过测试,在绝大多数情况下,能够从的HTML代码段中提取出正文。但也有例外。
例外情况
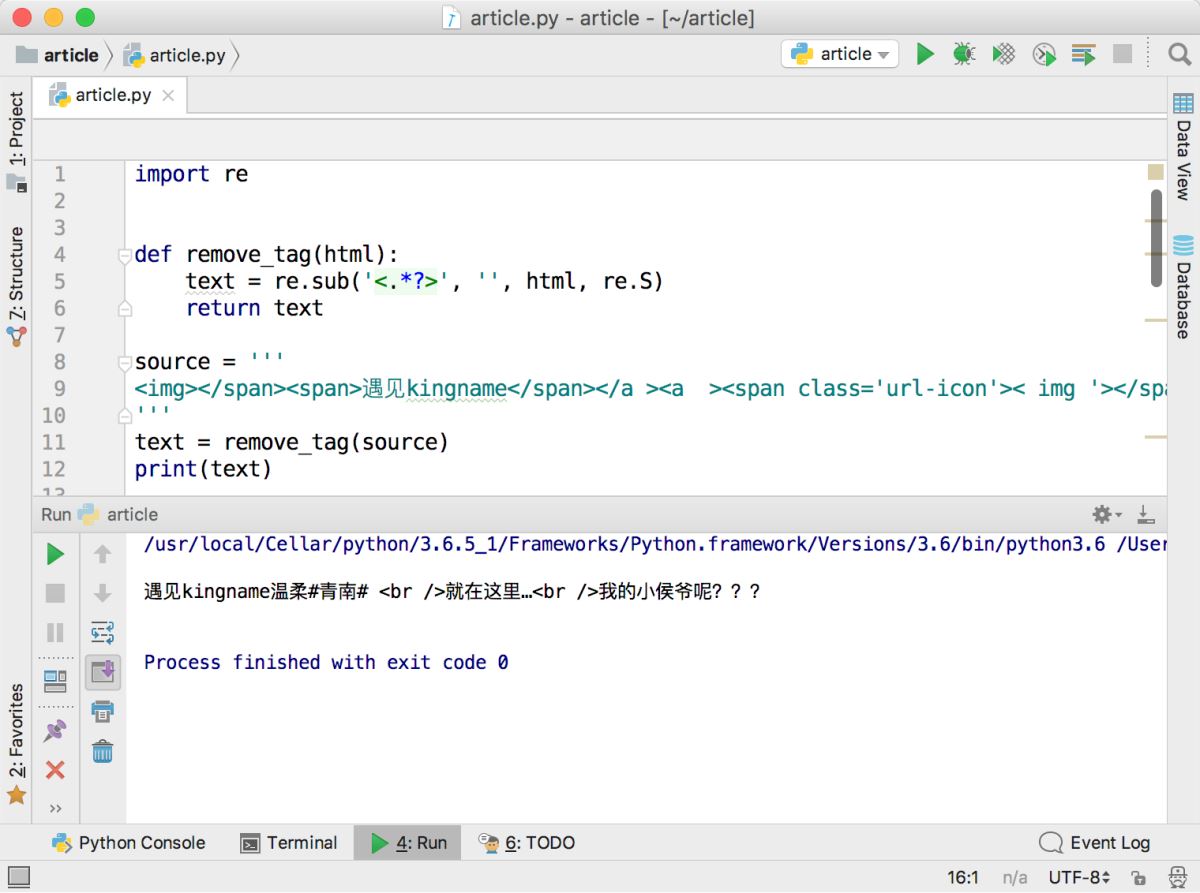
有一段HTML代码段比较长,内容如下:
img>
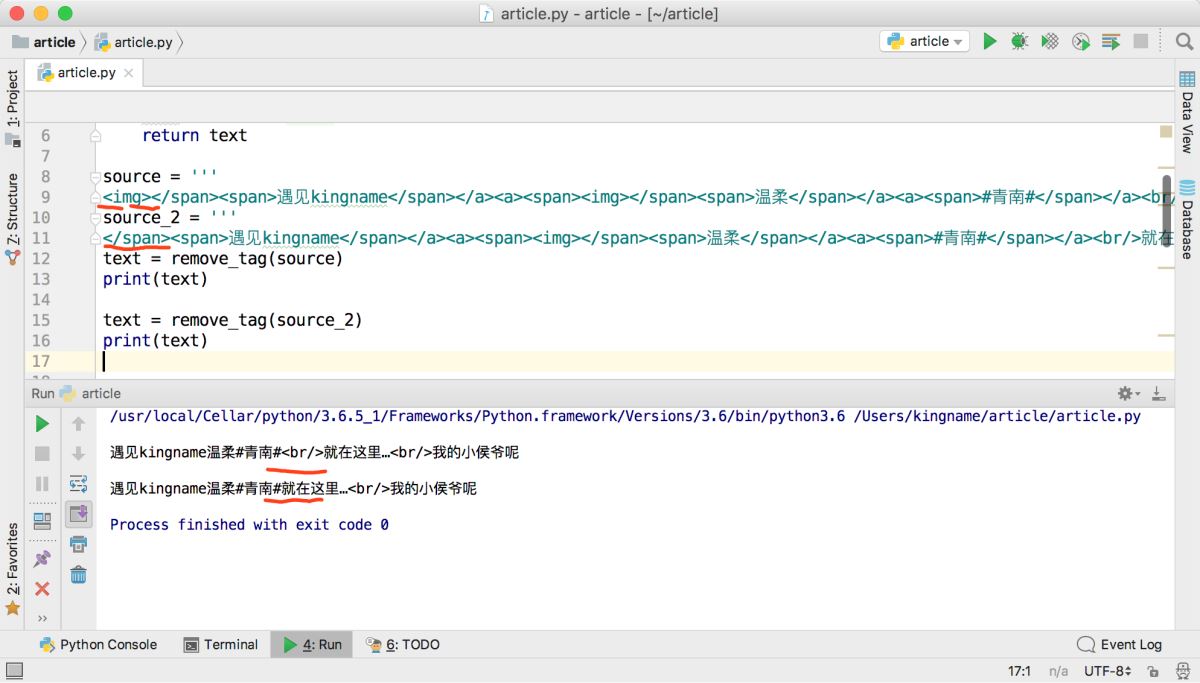
/span>span>遇见kingname/span>/a >a >span class='url-icon'> img '>/span>span >温柔/span>/a >a >span >#青南#/span>/a > br />就在这里…br />我的小侯爷呢???
运行效果如下图所示,最后两个HTML标签替换失败。
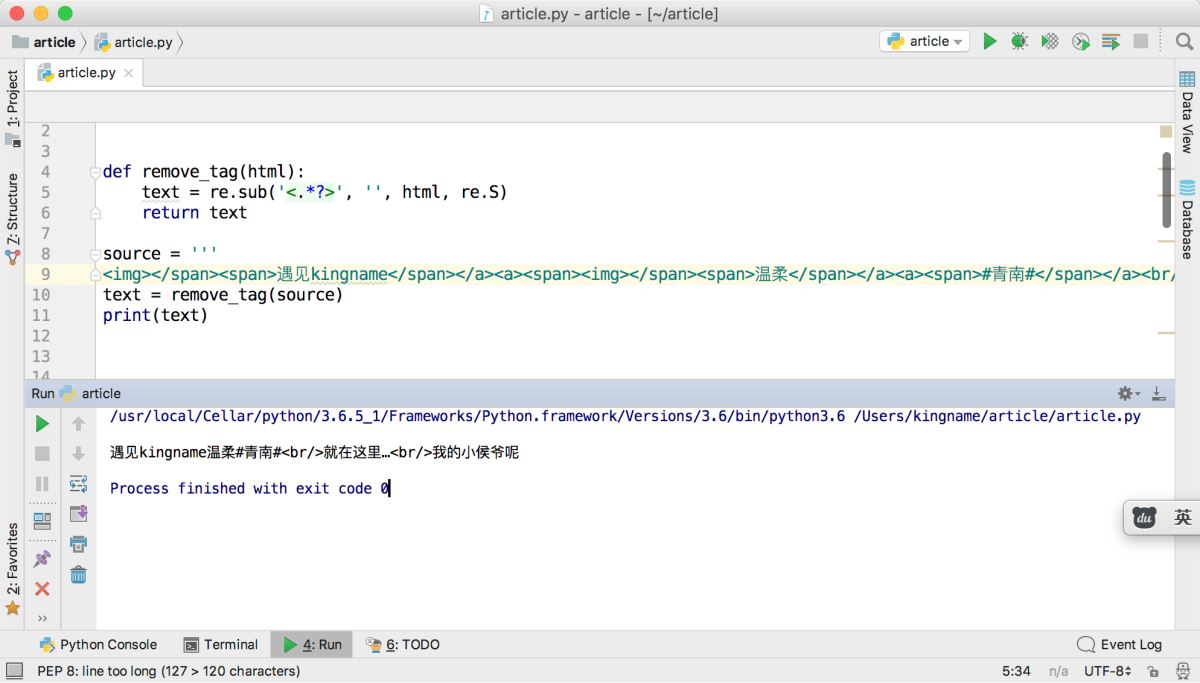
一开始我以为是HTML里面的空格或者引号引起的问题,于是我把HTML代码进行简化:
img>/span>span>遇见kingname/span>/a>a>span>img>/span>span>温柔/span>/a>a>span>#青南#/span>/a>br/>就在这里…br/>我的小侯爷呢
问题依然存在,如下图所示。
而且更令人惊讶的是,如果把第一个标签img>删了,那么替换结果里面就少了一个标签,如下图所示。
实际上,不仅仅是删除第一个标签,前面任意一个标签删了都可以减少结果里面的一个标签。如果删除前面两个或以上标签,那么结果就正常了。
答疑解惑
这个看起来很奇怪的问题,根本原因在re.sub的第4个参数。从函数原型可以看到:
def sub(pattern, repl, string, count=0, flags=0)
第四个参数是count表示替换个数,re.S如果要用,应该作为第五个参数。所以如果把remove_tag函数做一些修改,那么结果就正确了:
def remove_tag(html):
text = re.sub('.*?>', '', html, flags=re.S)
return text
那么问题来了,把re.S放在count的位置,为什么代码没有报错?难道re.S是数字?实际上,如果打印一下就会发现,re.S确实可以作为数字:
>>> import re
>>> print(int(re.S))
16
现在回头数一数出问题的HTML代码,发现最后多出来的两个br>标签,刚刚好是第17和18个标签,而由于count填写的re.S可以当做16来处理,那么Python就会把前16个标签替换为空字符串,从而留下最后两个。
至此问题的原因搞清楚了。
这个问题没有被及早发现,有以下几个原因:
被替换的HTML代码是代码段,大多数情况下HTML标签不足16个,所以问题被隐藏。re.S是一个对象,但也是数字,count接收的参数刚好也是数字。在很多编程语言里面,常量都会使用数字,然后用一个有意义的大写字母来表示。re.S 处理的情况是div \n> 而不是div>\n/div>但测试的代码段标签都是第二种情况,所以在代码段里面实际上加不加re.S效果是一样的。
补充:下面在给大家介绍下正则表达式 re.sub()替换功能
re.sub()替换功能
re.sub是个正则表达式方面的函数,用来实现通过正则表达式,实现比普通字符串的replace更加强大的替换功能。简单的替换功能可以使用replace()实现。
def main():
text = '123, word!'
text1 = text.replace('123', 'Hello')
print(text1)
if __name__ == '__main__':
main()
# Hello, wold!
如果通过re.sub(0函数则可以匹配任意的数字,并将其替换:
import re
def main():
content = 'abc124hello46goodbye67shit'
list1 = re.findall(r'\d+', content)
print(list1)
mylist = list(map(int, list1))
print(mylist)
print(sum(mylist))
print(re.sub(r'\d+[hg]', 'foo1', content))
print()
print(re.sub(r'\d+', '456654', content))
if __name__ == '__main__':
main()
# ['124', '46', '67']
# [124, 46, 67]
# 237
# abcfoo1ellofoo1oodbye67shit
# abc456654hello456654goodbye456654shit
总结
以上所述是小编给大家介绍的正则表达式re.sub替换不完整的问题及完整解决方案,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对脚本之家网站的支持!
您可能感兴趣的文章:- python 正则表达式 re.sub & re.subn
- Python使用正则表达式获取网页中所需要的信息
- Python正则表达式中的re.S的作用详解


 咨 询 客 服
咨 询 客 服