前几天谈了正则匹配 js 字符串的问题:《js 正则学习小记之匹配字符串》 和 《js 正则学习小记之匹配字符串优化篇》。
里面讲到了优化正则起到提升性能的问题,但是能提升多少呢?
于是我去测试了,发现TMD几乎微乎其微,我用1千字符串进行100万次匹配测试,优不优化根本没区别。
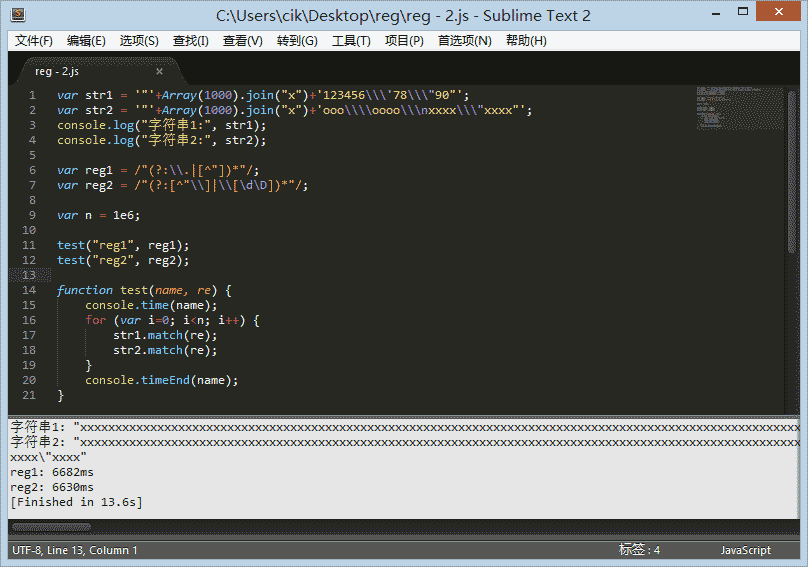
这不科学,我白看了这么多天正则,上天这是在玩弄我么。
突然我想到了 compile 方法,然后去测试了下,奇迹出现了,果然优化过的快了不少。

但这是为什么呢?
于是我翻阅资料,在 MDN 上找到了 RegExp Methods
这里说 compile 方法已被弃用!这不科学。。。
在 stackoverflow 上发现这篇文章 Javascript: what's the point of RegExp.compile()?
文章大意是说其实 直接 new RegExp 即可,compile 几乎用不到。
于是乎我修改了代码再来一次。
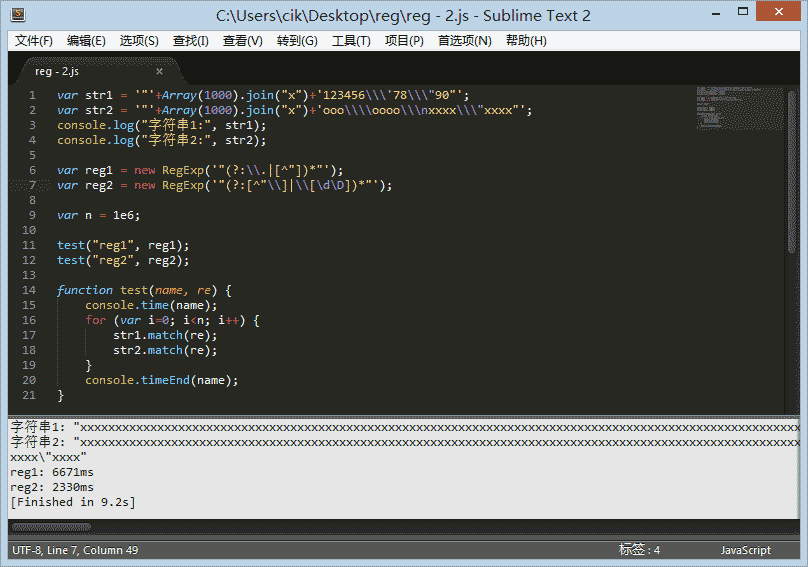
果然,直接 new RegExp 效果和 compile 是一样的。
不过这只是 nodejs 下的结果,我们去看看各个浏览器下的结果如何吧。
!doctype html>
html lang="en">
head>
meta charset="UTF-8">
title>test/title>
/head>
body>
script>
var str1 = '"' + Array(100).join("x") + '123456\\\'78\"90"';
var str2 = '"' + Array(100).join("x") + 'ooo\\oooo\nxxxx\"xxxx"';
// 这里写100,小一点,防止等半天,FF那怂货就半天
console.log("字符串1:", str1);
console.log("字符串2:", str2);
var reg1 = /"(?:\\.|[^"])*"/;
var reg2 = /"(?:[^"\\]|\[\d\D])*"/;
var reg11 = new RegExp('"(?:\.|[^"])*"');
var reg22 = new RegExp('"(?:[^"\\]|\[\d\D])*"');
var n = 1e6; //100万次测试
test("reg1", reg1);
test("reg2", reg2);
test("reg11", reg11);
test("reg22", reg22);
function test(name, re) {
console.time(name);
for (var i = 0; i n; i++) {
str1.match(re);
str2.match(re);
}
console.timeEnd(name);
}
/script>
/body>
/html>
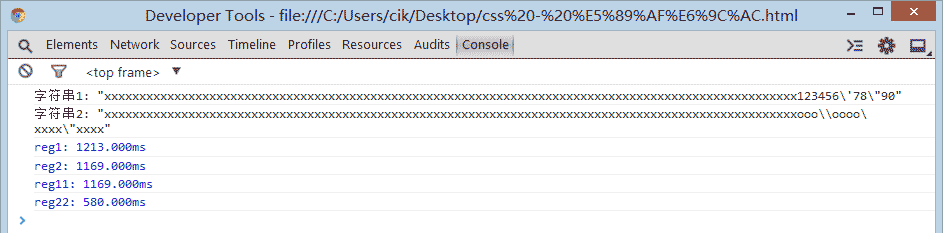
chrome
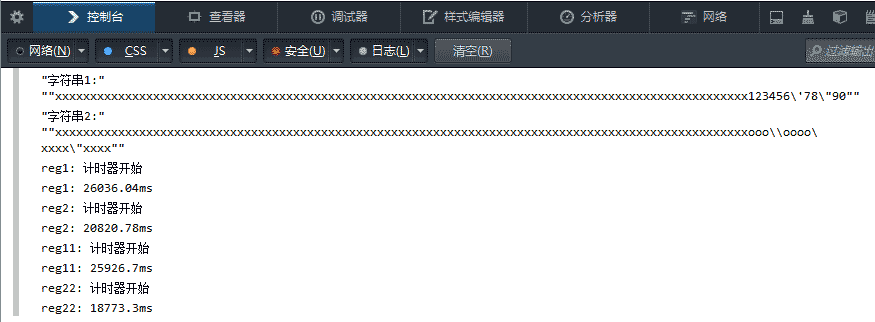
firefox
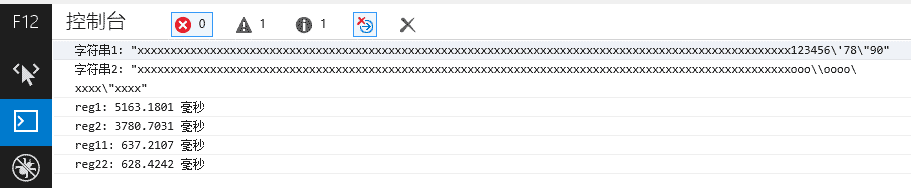
IE11

IE8 (我调用了一个插件模拟控制台实现IE6-8调试输出的)
很明显,第一名是 chrome (以 reg22 那个优化过的为准),这个号称武装到牙齿的货,果然够new逼。
不过 firefox 这货,竟然连 IE8 都比不过,是不是太怂了点。
优化过的 正则 比没优化的快,那是肯定的。
但是 正则字面量 和 new RegExp 比,那就不是一个档次了。
为什么有如此大的差距呢?
其实我也没搞清楚。
以前看到很多文章都说 字面量 会比 new 对象 形式效率高,但是在正则这里,好像不是这么回事。
不过也不能直接否认这个观点,因为我一直都用字面量的,简洁美观,用着方便才是王道。
我觉得在数据量大,或者重复操作次数多的时候用 new RegExp 是很必要的。
因为你也看到了性能提升这么多。
当然前提条件是你的正则必须优化,正则没优化的情况,两种差不多。
所以优化你的正则,然后用 new RegExp 可以大幅度提升程序的性能。
PS: IE11 是个特例,这货从来不安套路出牌。
好了今天的分享完毕,你们都蠢蠢欲动了吧,快去把正则各种new起来吧。
您可能感兴趣的文章:- 如何用Node.js编写内存效率高的应用程序
- JavaScript查看代码运行效率console.time()与console.timeEnd()用法
- JavaScript提高加载和执行效率的方法
- JavaScript中for循环的几种写法与效率总结
- JavaScript数组去重的几种方法效率测试
- 如何高效率去掉js数组中的重复项
- 深入探究JavaScript中for循环的效率问题及相关优化
- JavaScript判断是否为数组的3种方法及效率比较
- 原生JS中应该禁止出现的写法


 咨 询 客 服
咨 询 客 服