
| IP | hostname | 进程 |
| 192.168.30.141 | s141 | nn1(namenode),zkfc(DFSZKFailoverController),zk(QuorumPeerMain) |
| 192.168.30.142 | s142 | dn(datanode), jn(journalnode),zk(QuorumPeerMain) |
| 192.168.30.143 | s143 | dn(datanode), jn(journalnode),zk(QuorumPeerMain) |
| 192.168.30.144 | s144 | dn(datanode), jn(journalnode) |
| 192.168.30.145 | s145 | dn(datanode) |
| 192.168.30.146 | s146 | nn2(namenode),zkfc(DFSZKFailoverController) |
各个机器 jps进程:

由于本人使用的是vmware虚拟机,所以在配置好一台机器后,使用克隆,克隆出剩余机器,并修改hostname和IP,这样每台机器配置就都统一了每台机器配置添加hdfs用户及用户组,配置jdk环境,安装hadoop,本次搭建高可用集群在hdfs用户下,可以参照:centos7搭建hadoop2.10伪分布模式
下面是安装高可用集群的一些步骤和细节:
1.设置每台机器的hostname 和 hosts
修改hosts文件,hosts设置有后可以使用hostname访问机器,这样比较方便,修改如下:
127.0.0.1 locahost 192.168.30.141 s141 192.168.30.142 s142 192.168.30.143 s143 192.168.30.144 s144 192.168.30.145 s145 192.168.30.146 s146
2.设置ssh无密登录,由于s141和s146都为namenode,所以要将这两台机器无密登录到所有机器,最好hdfs用户和root用户都设置无密登录
我们将s141设置为nn1,s146设置为nn2,就需要s141、s146能够通过ssh无密登录到其他机器,这样就需要在s141和s146机器hdfs用户下生成密钥对,并将s141和s146公钥发送到其他机器放到~/.ssh/authorized_keys文件中,更确切的说要将公钥添加的所有机器上(包括自己)
在s141和s146机器上生成密钥对:
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
将id_rsa.pub文件内容追加到s141-s146机器的/home/hdfs/.ssh/authorized_keys中,现在其他机器暂时没有authorized_keys文件,我们就将id_rsa.pub更名为authorized_keys即可,如果其他机器已存在authorized_keys文件可以将id_rsa.pub内容追加到该文件后,远程复制可以使用scp命令:
s141机器公钥复制到其他机器
scp id_rsa.pub hdfs@s141:/home/hdfs/.ssh/id_rsa_141.pub scp id_rsa.pub hdfs@s142:/home/hdfs/.ssh/id_rsa_141.pub scp id_rsa.pub hdfs@s143:/home/hdfs/.ssh/id_rsa_141.pub scp id_rsa.pub hdfs@s144:/home/hdfs/.ssh/id_rsa_141.pub scp id_rsa.pub hdfs@s145:/home/hdfs/.ssh/id_rsa_141.pub scp id_rsa.pub hdfs@s146:/home/hdfs/.ssh/id_rsa_141.pub
s146机器公钥复制到其他机器
scp id_rsa.pub hdfs@s141:/home/hdfs/.ssh/id_rsa_146.pub scp id_rsa.pub hdfs@s142:/home/hdfs/.ssh/id_rsa_146.pub scp id_rsa.pub hdfs@s143:/home/hdfs/.ssh/id_rsa_146.pub scp id_rsa.pub hdfs@s144:/home/hdfs/.ssh/id_rsa_146.pub scp id_rsa.pub hdfs@s145:/home/hdfs/.ssh/id_rsa_146.pub scp id_rsa.pub hdfs@s146:/home/hdfs/.ssh/id_rsa_146.pub
在每台机器上可以使用cat将秘钥追加到authorized_keys文件
cat id_rsa_141.pub >> authorized_keys cat id_rsa_146.pub >> authorized_keys
此时authorized_keys文件权限需要改为644(注意,经常会因为这个权限问题导致ssh无密登录失败)
chmod 644 authorized_keys
3.配置hadoop配置文件(${hadoop_home}/etc/hadoop/)
配置细节:
注意:s141和s146具有完全一致的配置,尤其是ssh.
1) 配置nameservice
[hdfs-site.xml] <property> <name>dfs.nameservices</name> <value>mycluster</value> </property>
2) dfs.ha.namenodes.[nameservice ID]
[hdfs-site.xml] <!-- myucluster下的名称节点两个id --> <property> <name>dfs.ha.namenodes.mycluster</name> <value>nn1,nn2</value> </property>
3) dfs.namenode.rpc-address.[nameservice ID].[name node ID]
[hdfs-site.xml] 配置每个nn的rpc地址。 <property> <name>dfs.namenode.rpc-address.mycluster.nn1</name> <value>s141:8020</value> </property> <property> <name>dfs.namenode.rpc-address.mycluster.nn2</name> <value>s146:8020</value> </property>
4) dfs.namenode.http-address.[nameservice ID].[name node ID]
配置webui端口
[hdfs-site.xml] <property> <name>dfs.namenode.http-address.mycluster.nn1</name> <value>s141:50070</value> </property> <property> <name>dfs.namenode.http-address.mycluster.nn2</name> <value>s146:50070</value> </property>
5) dfs.namenode.shared.edits.dir
名称节点共享编辑目录.选择三台journalnode节点,这里选择s142、s143、s144三台机器
[hdfs-site.xml] <property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://s142:8485;s143:8485;s144:8485/mycluster</value> </property>
6) dfs.client.failover.proxy.provider.[nameservice ID]
配置一个HA失败转移的java类(改配置是固定的),client使用它判断哪个节点是激活态。
[hdfs-site.xml] <property> <name>dfs.client.failover.proxy.provider.mycluster</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property>
7) dfs.ha.fencing.methods
脚本列表或者java类,在容灾保护激活态的nn.
[hdfs-site.xml] <property> <name>dfs.ha.fencing.methods</name> <value>sshfence</value> </property> <property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/home/hdfs/.ssh/id_rsa</value> </property>
8) fs.defaultFS
配置hdfs文件系统名称服务。这里的mycluster为上面配置的dfs.nameservices
[core-site.xml] <property> <name>fs.defaultFS</name> <value>hdfs://mycluster</value> </property>
9) dfs.journalnode.edits.dir
配置JN存放edit的本地路径。
[hdfs-site.xml] <property> <name>dfs.journalnode.edits.dir</name> <value>/home/hdfs/hadoop/journal</value> </property>
完整配置文件:
core-site.xml
<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>fs.defaultFS</name> <value>hdfs://mycluster/</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/home/hdfs/hadoop</value> </property> </configuration>
hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>dfs.replication</name> <value>3</value> </property> <property> <name>dfs.hosts</name> <value>/opt/soft/hadoop/etc/dfs.include.txt</value> </property> <property> <name>dfs.hosts.exclude</name> <value>/opt/soft/hadoop/etc/dfs.hosts.exclude.txt</value> </property> <property> <name>dfs.nameservices</name> <value>mycluster</value> </property> <property> <name>dfs.ha.namenodes.mycluster</name> <value>nn1,nn2</value> </property> <property> <name>dfs.namenode.rpc-address.mycluster.nn1</name> <value>s141:8020</value> </property> <property> <name>dfs.namenode.rpc-address.mycluster.nn2</name> <value>s146:8020</value> </property> <property> <name>dfs.namenode.http-address.mycluster.nn1</name> <value>s141:50070</value> </property> <property> <name>dfs.namenode.http-address.mycluster.nn2</name> <value>s146:50070</value> </property> <property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://s142:8485;s143:8485;s144:8485/mycluster</value> </property> <property> <name>dfs.client.failover.proxy.provider.mycluster</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property> <property> <name>dfs.ha.fencing.methods</name> <value>sshfence</value> </property> <property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/home/hdfs/.ssh/id_rsa</value> </property> <property> <name>dfs.journalnode.edits.dir</name> <value>/home/hdfs/hadoop/journal</value> </property> </configuration>
mapred-site.xml
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
yarn-site.xml
<?xml version="1.0"?> <configuration> <!-- Site specific YARN configuration properties --> <property> <name>yarn.resourcemanager.hostname</name> <value>s141</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration>
4. 部署细节
1)在jn节点分别启动jn进程(s142,s143,s144)
hadoop-daemon.sh start journalnode
2)启动jn之后,在两个NN之间进行disk元数据同步
a)如果是全新集群,先format文件系统,只需要在一个nn上执行。
[s141|s146]
hadoop namenode -format
b)如果将非HA集群转换成HA集群,复制原NN的metadata到另一个NN上.
1.步骤一
在s141机器上,将hadoop数据复制到s146对应的目录下
scp -r /home/hdfs/hadoop/dfs hdfs@s146:/home/hdfs/hadoop/
2.步骤二
在新的nn(未格式化的nn,我这里是s146)上运行以下命令,实现待命状态引导。注意:需要s141namenode为启动状态(可以执行:hadoop-daemon.sh start namenode )。
hdfs namenode -bootstrapStandby
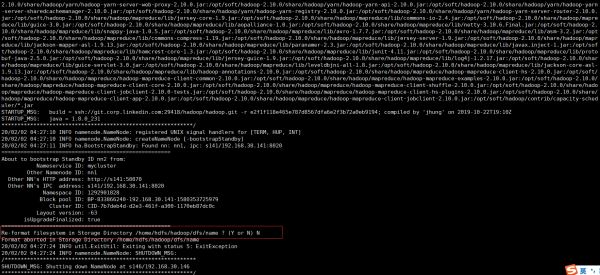
如果没有启动s141名称节点,就会失败,如图:

启动s141名称节点后,在s141上执行命令
hadoop-daemon.sh start namenode
然后在执行待命引导命令,注意:提示是否格式化,选择N,如图:
3. 步骤三
在其中一个NN上执行以下命令,完成edit日志到jn节点的传输。
hdfs namenode -initializeSharedEdits
如果执行过程中报:java.nio.channels.OverlappingFileLockException 错误:
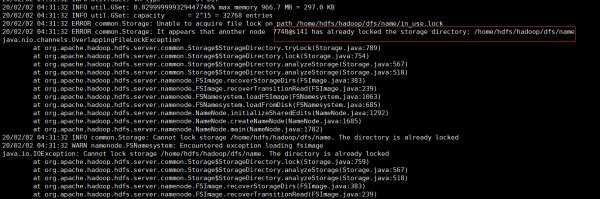
说明namenode在启动中,需要停掉namenode节点(hadoop-daemon.sh stop namenode)
执行完后查看s142,s143,s144是否有edit数据,这里查看生产了mycluster目录,里面有编辑日志数据,如下:

4.步骤四
启动所有节点.
在s141上启动名称节点和所有数据节点:
hadoop-daemon.sh start namenode hadoop-daemons.sh start datanode
在s146上启动名称节点
hadoop-daemon.sh start namenode
此时在浏览器中访问http://192.168.30.141:50070/和http://192.168.30.146:50070/你会发现两个namenode都为standby
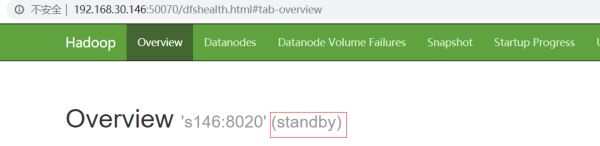
这时需要手动使用命令将其中一个切换为激活态,这里将s141(nn1)设置为active
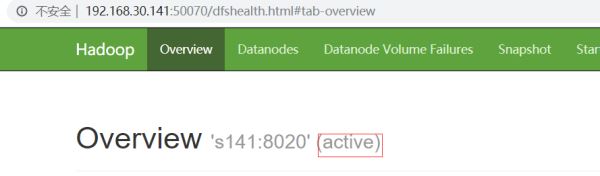
hdfs haadmin -transitionToActive nn1
此时s141就为active
hdfs haadmin常用命令:
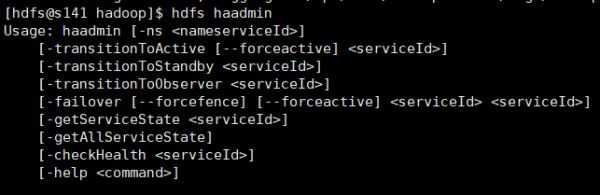
至此手动容灾高可用配置完成,但是这种方式不智能,不能够自动感知容灾,所以下面介绍自动容灾配置
5.自动容灾配置
需要引入zookeeperquarum 和 zk 容灾控制器(ZKFC)两个组件
搭建zookeeper集群,选择s141,s142,s143三台机器,下载 zookeeper:http://mirror.bit.edu.cn/apache/zookeeper/zookeeper-3.5.6
1) 解压zookeeper:
tar -xzvf apache-zookeeper-3.5.6-bin.tar.gz -C /opt/soft/zookeeper-3.5.6
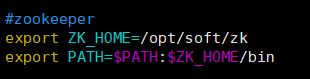
2) 配置环境变量,在/etc/profile中添加zk环境变量,并重新编译/etc/profile文件
3) 配置zk配置文件,三台机器配置文件统一
# The number of milliseconds of each tick tickTime=2000 # The number of ticks that the initial # synchronization phase can take initLimit=10 # The number of ticks that can pass between # sending a request and getting an acknowledgement syncLimit=5 # the directory where the snapshot is stored. # do not use /tmp for storage, /tmp here is just # example sakes. dataDir=/home/hdfs/zookeeper # the port at which the clients will connect clientPort=2181 # the maximum number of client connections. # increase this if you need to handle more clients #maxClientCnxns=60 # # Be sure to read the maintenance section of the # administrator guide before turning on autopurge. # # http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance # # The number of snapshots to retain in dataDir #autopurge.snapRetainCount=3 # Purge task interval in hours # Set to "0" to disable auto purge feature #autopurge.purgeInterval=1 server.1=s141:2888:3888 server.2=s142:2888:3888 server.3=s143:2888:3888
4)分别
在s141的/home/hdfs/zookeeper(在zoo.cfg配置文件中配置的dataDir路径)目录下创建myid文件,值为1(对应zoo.cfg配置文件中的server.1)
在s142的/home/hdfs/zookeeper(在zoo.cfg配置文件中配置的dataDir路径)目录下创建myid文件,值为2(对应zoo.cfg配置文件中的server.2)
在s143的/home/hdfs/zookeeper(在zoo.cfg配置文件中配置的dataDir路径)目录下创建myid文件,值为3(对应zoo.cfg配置文件中的server.3)
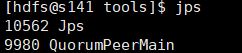
5) 分别在每台机器上启动zk
zkServer.sh start
启动成功会出现zk进程:
配置hdfs相关配置:
1)停止hdfs所有进程
stop-all.sh
2)配置hdfs-site.xml,启用自动容灾.
[hdfs-site.xml] <property> <name>dfs.ha.automatic-failover.enabled</name> <value>true</value> </property>
3) 配置core-site.xml,指定zk的连接地址.
<property> <name>ha.zookeeper.quorum</name> <value>s141:2181,s142:2181,s143:2181</value> </property>
4) 分发以上两个文件到所有节点。
5) 在其中的一台NN(s141),在ZK中初始化HA状态
hdfs zkfc -formatZK
出现如下结果说明成功:

也可去zk中查看:

6) 启动hdfs集群
start-dfs.sh
查看各个机器进程:
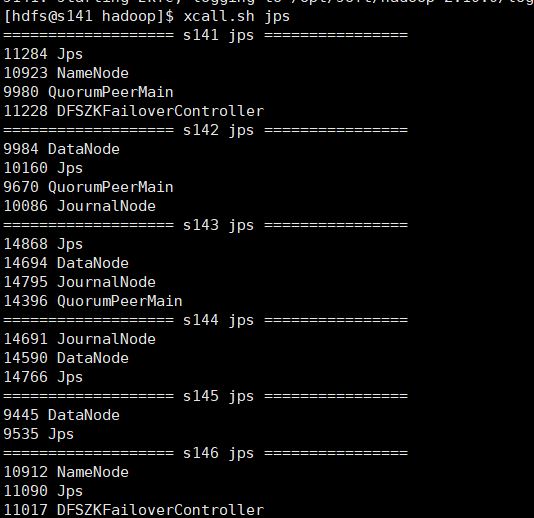
启动成功,再看一下webui
s146为激活态

s141为待命态

至此hadoop 自动容灾HA搭建完成
总结
以上所述是小编给大家介绍的centos7搭建hadoop2.10高可用(HA),希望对大家有所帮助!

 咨 询 客 服
咨 询 客 服