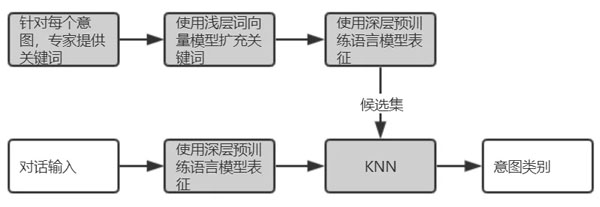
任务型对话系统主要包括自然语言理解、对话管理和对话生成。其中,自然语言理解指的是分析识别为文本的用户输入,得到用户的意图和输入中的关键信息,包括领域、意图识别、实体识别和槽的提取等。
随着自然语言处理技术的发展,一些新的方法运用到了自然语言理解中,并取得了不错的效果。本文将针对意图识别这部分,浅谈在参与某项目中的一些经验和思考。
01.从规则到模型
以往意图识别主要采用规则系统,规则系统的模板需要人工配置。
例如,我们需要支持开空调的意图,那么可以做如下的配置:
意图:开空调
模板:(请|帮我)(打开|启动)(这个|那个)?(空调|冷风机)(啊|吧)?
用户输入:帮我打开空调,即可通过模板匹配到开空调意图
规则系统的优点是可配置,如果需要增加支持的模板,只需在配置系统内加入,这在线上产生重要遗漏时显得尤为重要,能够及时修复。缺点是复杂的语言表述需要更复杂的模板,再考虑到语言的随意性,配置灵活的模板又会使规则系统接受很多本来没有意图的用户输入,降低规则系统的准确率。
基于机器学习的方法,可以一定程度上弥补这些问题,大幅提高召回率。规则系统结合机器学习,在实际操作中是较为灵活的方案。
02.无监督方法
传统方法依赖特征工程,神经网络需要大量标注,如何以较少的标注数据获得较好的模型效果成为了研究和实验重点。
近年,自监督学习的语言模型研究[1]获得重大进展,各种使用大规模文本语料库预训练的模型层出不穷,这些预训练模型提供了强大的语义表征能力,使得一些无监督方法重新焕发了活力,这里介绍一种使用语言模型+KNN[2]进行意图识别的方法
该方法可以在没有人工标注的情况,快速建立预测,同时获得还不错的效果,在某场景中验证准确率达到93%。
03.有监督样本构造
当面临复杂语义场景或低容错时,监督学习值得尝试。而对话场景的数据常常是匮乏、昂贵和敏感的,除了人工构造和标注以外,我们需要尽可能的寻找方法获取标注数据。
有规则模板:对规则系统中的模板按照语法拆分,依据关键词重要程度,采用笛卡尔积方式构建样本,这些样本某种程度上可以用来作为baseline测试集。
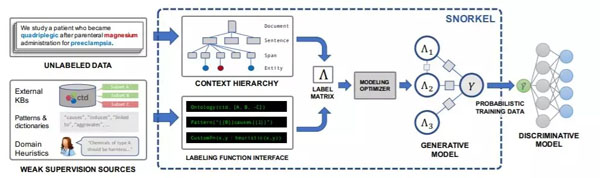
有大量无标注对话语料:采用弱监督方法,使用如Snorkel[3]的工具,基于知识库、模板、字典、句法和专家规则等构建推理逻辑,为无标注数据打上概率标签。
图片来源:Snorkel:Rapid Training Data Creation with Weak Supervision
负样本构造:在某些场景中,包含了大量与业务意图无关的对话,而训练语料通常只有正样本,或者模型对某些词过于敏感,模型对无意图和意图不明的对话会产生错误的判断,除常规闲聊语料的运用,需要构建无意图的负样本参与模型的训练和验证
在实际操作中,可以基于正样本的字或词构建一定区间长度的随机序列作为负样本,也可以对字词做一定筛选后构建。同时,对于multi-class为了不增加新的无意图类别,可以将负样本的标签概率化为1/n,在预测时设置最大类别概率阈值过滤。
正样本意图向量:[0,0,1,0,0]
弱监督意图向量:[0.1,0.2,0.5,0.1,0.1]
负样本意图向量:[0.2,0.2,0.2,0.2,0.2]
实验证明,通过加入随机负样本训练,对无序输入文本的识别能提升50%:
04.预训练模型微调
使用预训练模型加任务微调,现在几乎成为各类NLP任务的标配,仅仅需要较少标注数据就能达到以往较多标注数据的训练效果,在意图分类中尝试,同样有较大提升。
领域自适应
开源预训练模型大多基于百科、新闻等语料训练,属于通用领域。而对话系统中的文本更加偏向口语化,那么在开源预训练模型上,加入领域数据继续训练,进行领域自适应将变得十分必要。在无业务数据的情况下,可以使用开源对话数据来迁移,学习口语化的表征,使得模型更加匹配对话业务场景。
性能优化
使用预训练模型微调尽管能取得较好的效果,但是由于其深层的网络结构和庞大的参数量,如果部署上线,将面临资源和性能问题。对此一般做法是,在模型训练和推理中使用低精度,同时减少模型层数。近期google提出了一种轻量级ALBERT[4],通过两种参数精简方法来提升推理性能,而效果依然达到了SOTA,目前已经开源中文预训练模型,十分值得关注。
05.学习意图分布
在某些场景,意图会比较接近,常规的分类方法无法区分,一种思路[5]是将意图类别和用户输入文本嵌入到相同向量空间,基于相似度进行对比学习,目标函数:
- a是用户输入的文本
- b是对应的意图,b^-从其他意图中采样获取
- sim(·,·)是相似度函数,cosine或inner
- L是目标函数,最大化正确样本对相似度和最小化错误样本对相似度
# mu_pos: 0.8 (should be 0.0 … 1.0 for ‘cosine’) is how similar the algorithm should try to make embedding vectors for correct intent labels
# mu_neg: -0.4 (should be -1.0 … 1.0 for ‘cosine’) is maximum negative similarity for incorrect intent labels
# loss for maximizing similarity with correct action
loss = tf.maximum(0., mu_pos - sim_op[:, 0])
# minimize only maximum similarity over incorrect actions
max_sim_neg = tf.reduce_max(sim_op[:, 1:], -1)
loss += tf.maximum(0., mu_neg + max_sim_neg)
# average the loss over the batch and add regularization losses
loss=(tf.reduce_mean(loss)+tf.losses.get_regularization_loss())
这种思路有多种好处,能学习到意图的向量表示,可以在预测时直接基于相似度排序输出最大意图;当意图类别较多时,还能对意图进行归类比较;同时这些向量表示也能作为特征用于其他任务,如推荐等。
06.少样本学习冷启动
目前少样本学习在图像领域非常火,用户只需要上传一张图片,就可以迁移各种脸部表情和肢体动作,引领一波社交应用风潮。
在自然语言处理领域,这方面的尝试还并不是很成功,阿里巴巴的小蜜团队在打造的智能对话开发平台Dialog Studio中提出了少样本学习方法Induction Network[6],并将该方法用于创建新的对话任务时意图识别冷启动,不过代码并没有开源。我们对论文中的方法进行了复现并公布了代码(github地址),在少样本关系抽取数据集上进行验证,欢迎fork和交流。
通过积累线上数据,迭代训练,常常是提升效果最大的方式,数据决定上限,长远来讲,构建自动化的迭代机制势在必行。同时,将多轮对话作为输入,会有更多的探索空间。
和美信息自然语言处理团队三年磨一剑,围绕银行智能化场景展开了多种探索并取得不错的成绩。例如,某银行项目中催收意图识别服务于总行与分行,渗透率已超过70%,每天20万+人次的调用。新的一年,和美信息人工智能研究院自然语言处理组将继续努力,围绕自然语言训练平台、智能对话工厂进行展开,通过相关技术与业务人员紧密合作、快速迭代,将公司先进技术与银行智能化场景结合,实现快速落地应用,未来将有更多AI产品加速银行智能化转型进程,也欢迎各位志同道合的小伙伴加入一起探索未来!
目前和美信息自然语言处理在银行场景已落地:智能客服、智能搜索、合同文档自动解析、人岗精准匹配、文档查重、客户意见分析、智能推荐、用户画像、舆情监控与预警、报告摘要、报告生成、智能审阅等产品,服务各银行业务部门。
参考文献:
[1]DevlinJ, Chang M W, Lee K, et al. Bert: Pre-training of deep bidirectionaltransformers for language understanding[J]. arXiv preprint arXiv:1810.04805,2018.
[2]CoverT, Hart P. Nearest neighbor pattern classification[J]. IEEE transactions oninformation theory, 1967, 13(1): 21-27.
[3]Alexander R,et al. Snorkel: Rapid Training Data Creation with Weak Supervision[J].Supervision[J].[J].arXiv:1711.10160,2017.
[4]Zhenzhong Lan,et al. ALBERT: A Lite BERT for Self-supervised Learning of Language Representations[J].arXiv:1909.11942,2019.
[5]Ledell Wu, Adam Fisch. StarSpace: Embed All The Things![J]arXiv:1709.03856,2017.
[6]Ruiying Geng, Binhua Li,et al. Induction Networks for Few-Shot Text Classification[J]. arXiv:1902.10482,2019.


 咨 询 客 服
咨 询 客 服