今天江西SEO曾庆平写篇科普文,讲讲搜索引擎的技术机理和市场竞争的一些特点。当然,作为从事或有兴趣从事流量运营的朋友,是可以用另一个角度去理解本文。
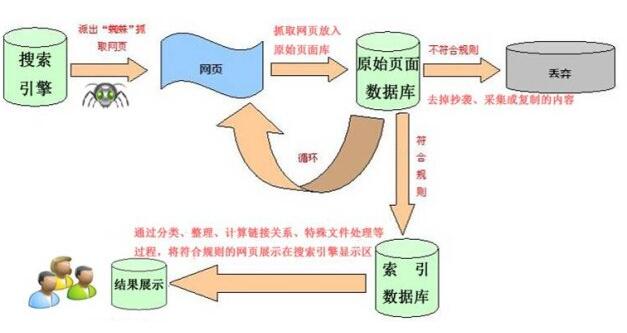
搜索引擎的核心技术架构,大体包括以下三块,第一,是蜘蛛/爬虫技术;第二,是索引技术;第三是查询展现的技术; 当然,我不是搜索引擎的架构师,我只能用比较粗浅的方式来做一个结构的切分。
1、蜘蛛/爬虫技术
蜘蛛,也叫爬虫,是将互联网的信息,抓取并存储的一种技术实现。
搜索引擎的信息收录,很多不明所以的人会有很多误解,以为是付费收录,或者有什么其他特殊的提交技巧,其实并不是,搜索引擎通过互联网一些公开知名的网站,抓取内容,并分析其中的链接,然后有选择的抓取链接里的内容,然后再分析其中的链接,以此类推,通过有限的入口,基于彼此链接,形成强大的信息抓取能力。
有些搜索引擎本身也有链接提交入口,但基本上,不是主要的收录入口,不过作为创业者,建议了解一下相关信息,百度,google都有站长平台和管理后台,这里很多内容是需要非常非常认真的对待的。
反过来说,在这样的原理下,一个网站,只有被其他网站所链接,才有机会被搜索引擎抓取。如果这个网站没有外部链接,或者外部链接在搜索引擎中被认为是垃圾或无效链接,那么搜索引擎可能就不抓取他的页面。
分析和判断搜索引擎是否抓取了你的页面,或者什么时候抓取你的页面,只能通过服务器上的访问日志来查询,如果是cdn就比较麻烦。 而基于网站嵌入代码的方式,不论是cnzz,百度统计,还是google analytics,都无法获得蜘蛛抓取的信息,因为这些信息不会触发这些代码的执行。
一个比较推荐的日志分析软件是awstats。
在十多年前,分析百度蜘蛛抓取轨迹和更新策略,是很多草根站长每日必做的功课,比如现在身价几十亿的知名80后上市公司董事长,当年在某站长论坛就是以此准确的分析判断而封神,很年轻的时候就已经是站长圈的一代偶像。
但关于蜘蛛的话题,并不只基于链接抓取这么简单,延伸来说
第一,网站拥有者可以选择是否允许蜘蛛抓取,有一个robots.txt的文件是来控制这个的。
一个经典案例是 https://www.taobao.com/robots.txt
你会看到,淘宝至今仍有关键目录不对百度蜘蛛开放,但对google开放。
另一个经典案例是 http://www.baidu.com/robots.txt
你看出什么了?你可能什么都没看出来,我提醒一句,百度实质上全面禁止了360的蜘蛛抓取。
但这个协议只是约定俗成,实际上并没有强制约束力,所以,你们猜猜,360遵守了百度的蜘蛛抓取禁止么?
第二,最早抓取是基于网站彼此的链接为入口,但实际上,并不能肯定的说,有可能存在其他抓取入口,比如说,
客户端插件或浏览器, 免费网站统计系统的嵌入式代码。
会不会成为蜘蛛抓取的入口,我只能说,有这个可能。
所以我跟很多创业者说,中国做网站,放百度统计,海外做网站,放google analytics,是否会增加搜索引擎对你网站的收录?我只能说猜测,有这个可能。
第三,无法被抓取的信息
有些网站的内容链接,用一些 特殊效果完成,比如浮动的菜单等等,这种连接,有可能搜索引擎的蜘蛛程序不识别,当然,我只是说有可能,现在搜索引擎比以前聪明,十多年前很多特效链接是不识别的,现在会好一些。
需要登录,需要注册才能访问的页面,蜘蛛是无法进入的,也就是无法收录。
有些网站会给搜索特殊页面,就是蜘蛛来能看到内容(蜘蛛访问会有特殊的客户端标记,服务端识别和处理并不复杂),人来了要登录才能看,但这样做其实是违反了收录协议(需要人和蜘蛛看到的同样的内容,这是绝大部分搜索引擎的收录协议),有可能遭到搜索引擎处罚。
所以一个社区要想通过搜索引擎带来免费用户,必须让访客能看到内容,哪怕是部分内容。
带很多复杂参数的内容链接url,有可能被蜘蛛当作重复页面,拒绝收录。
很多动态页面是一个脚本程序带参数体现的,但蜘蛛发现同一个脚本有大量参数的网页,有时候会给该网页的价值评估带来困扰,蜘蛛可能会认为这个网页是重复页面,而拒绝收录。还是那句话,随着技术的发展,蜘蛛对动态脚本的参数识别度有了很大进步,现在基本上可以不用考虑这个问题。
但这个催生了一个技术,叫做伪静态化,通过对web服务端做配置,让用户访问的页面,url格式看上去是一个静态页,其实后面是一个正则匹配,实际执行的是一个动态脚本。
很多社区论坛为了追求免费搜索来路,做了伪静态化处理,在十多年前,几乎是草根站长必备技能之一。
爬虫技术暂时说到这里,但是这里强调一下,有外链,不代表搜索蜘蛛会来爬取,搜索蜘蛛爬取了,不代表搜索引擎会收录;搜索引擎收录了,不代表用户可以搜索的到;
site语法是检查一个网站收录数的最基本搜索语法,我开始以为是abc的常识,直到在新加坡做一些创业培训后交流才发现,大部分刚进入这个行业的人,或者有兴趣进入这个行业的人,对此并不了解。
一个范例,百度搜索一下 site:qingpingseo.com
2、索引系统
蜘蛛抓取的是网页的内容,那么要想让用户快速的通过关键词搜索到这个网页,就必须对网页做关键词的索引,从而提升查询效率,简单说就是,把网页的每个关键词提取出来,并针对这些关键词在网页中的出现频率,位置,特殊标记等诸多因素,给予不同的权值标定,然后,存储到索引库中。
上一页12 下一页 阅读全文


 咨 询 客 服
咨 询 客 服