
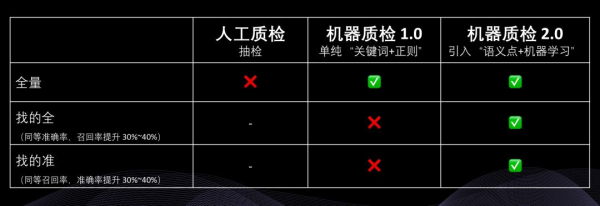
市面上有很多面向销售和客服人员的语音质检系统、文本质检系统,绝大部分产品实际使用的是基于“关键词+正则表达式”的机器质检系统。
这种方法的主要优点是部署和上手使用都比较快,主要缺点是存在非常严重的漏检情况。就像一个漏孔很大的筛子一样,难以满足企业对质检的需求越来越精细、对质检效率要求越来越高的发展趋势。
因此,在“关键词+正则表达式”之外,我们开始越来越多地为客户提供基于“语义点+机器学习”方案,并且在实际使用中为很多质检项带来 2~10 倍的效果提升。也就是说,能够多发现 2~10 倍的问题。对于企业而言,这就意味着他们可以更快、更全面地提升服务质量或者实现合规升级。
下一代机器质检:从关键词到语义点
语音和文本质检的主要任务是找出不合格、不合规的地方,即减分项,通常也被称为“负向质检”(另有一种任务是找出做得好的地方,即加分项,通常也被称为“正向质检”)。企业使用传统基于“关键词+正则表达式”的产品做质检,所遇到的最主要问题是“找不全”,通常会漏掉很多不合格、不合规之处,导致质检效率大打折扣。看一个实际对比的例子。某互联网公司的基础质检项“服务态度问题”,在我们的实际应用中:使用传统“关键词”方案,一天的数据中能找出 13 条,100% 是正确的;使用新的“语义点”方案,能找出 134 条,其中 72% 是对的。所以从最终正确的条数来看,新的“语义点”方案多找出了 8 倍的问题。
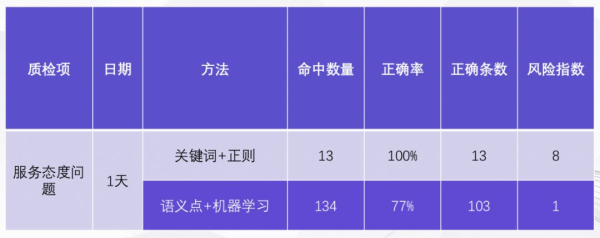
再看一个实际的例子。“恐吓威胁”是贷后资产管理领域的基础质检项,即催收员不允许在电话里“恐吓威胁”债务人。在我们的实际应用中:使用传统“关键词”方案,四天的数据中能找出 316 条,其中 55% 是正确的;使用“语义点”方案,能找出 2203 条,其中 72% 是对的。从最终正确的条数来看,174条对比1596条,新的“语义点”方案能多找出 9 倍的风险。
原因其实很简单。如果使用基于“关键词+正则表达式”的方案,方法是用关键词的组合来涵盖每个质检项的不同表达方式——但是你可以写10个关键词,100个关键词,却永远不可能穷尽,因为语言的表达方式是非常多样的、千变万化的,必须通过整个句子的上下文语义才能做出更准确的判断。
上下文语义质检的技术原理
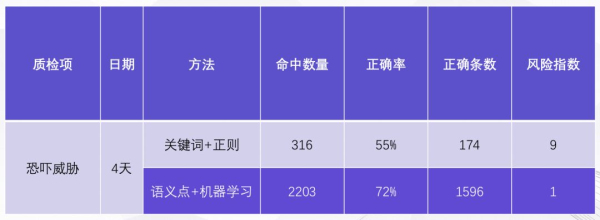
语义点+机器学习的方案,目标是训练一个机器学习算法模型,使之能够判断关键词未覆盖的句子是否命中了质检项。我们以另一个贷后资产管理领域常见的质检项“暴露客户隐私”为例。从标注到训练模型,再到最后上线使用,新的“语义点”方案大致可以分为三个步骤。第一步,使用我们的“标注工厂”产品,通过人工的方式,将是“暴露客户客户”的句子标记为“正例”,将不是“暴露客户隐私”的句子标记为反例。
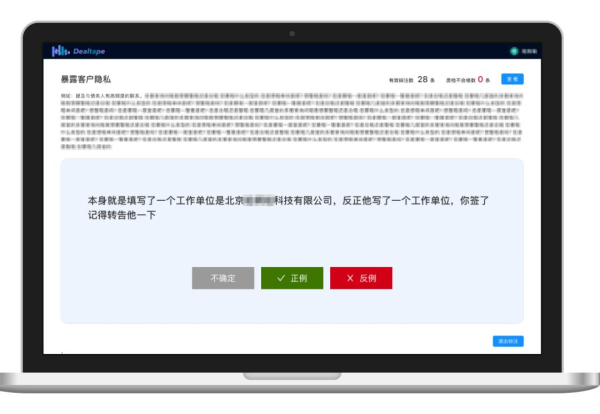
第二步,将一定规模的经过标注的正例和反例都“喂”给训练器,让训练器学习到一个算法模型,这个算法就能用来判断新句子是不是涉嫌暴露客户隐私。
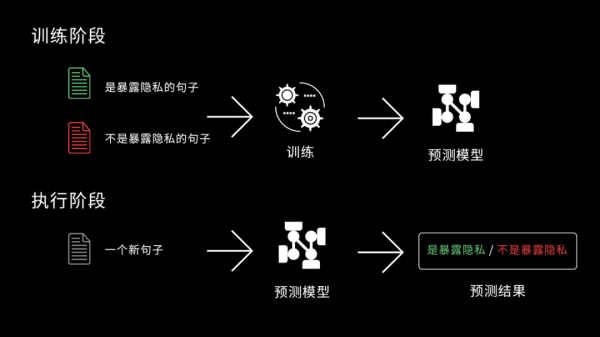
第三步,在质检产品中,系统就可以标记出所有命中“暴露客户隐私”语义点质检项的句子,复检员可以快速定位到该质检项所处的位置,迅速进行核实。此外,复检员每一次复检的操作,都相当于对算法模型进行了一次反馈,会帮助算法模型变得更准。
最终,我们发现通过“语义点”方案能比关键词的方案多找出数倍的不合格、不合规之处,达到召回率(找的全)、准确率(找的准)均在 80% 以上的效果。
上下文语义质检的底层逻辑从底层逻辑
上看,基于“关键词”的方案是字符级别的,并不关心句子的语义,而基于“语义点”的方案是句子级别的,非常关心句子上下文的逻辑和语义。两者并不在同一个维度。可以想见,未来关键词方案越来越难当大任,而语义点的方案会逐步成为主流。
不过,语义点方案也有一个显著的缺点“部署成本高”。为了训练一个语义点的质检项,需要人工标注大量句子,然后训练和调试算法模型。因此,大家并不会立即就把所有质检项切换到“语义点”方案,而是优先把那些最常见的质检项切换到“语义点”方案。
总结循环智能在教育、金融、互联网服务等不同行业数十家客户的服务经验,我们发现质检项与违规数的关系也存在“二八法则”——20%的质检项贡献了80%的违规数,所以将最常见质检项升级到“语义点”方案,即可为整个业务带来显著的效果提升。
同时,我们也应该了解到,随着自然语言处理领域新技术的突破,从字符级“关键词”方案,向句子级“语义点”方案转换的速度正在加快。过去两年,自然语言处理领域迎来了繁荣时期。Google 发表于 2018 年的 BERT 模型,为行业带来了全新的技术思路,具有里程碑意义。2019年6月,作为 BERT 模型的一种重要的改进方案,XLNet 模型在 20 个标准任务集上超过 BERT,并且在 18 个标准任务集上取得 state of the art 成果,包括机器问答、自然语言推断、情感分析和文档排序等。

XLNet 模型由循环智能联合创始人杨植麟博士(第一作者),与谷歌大脑、卡内基梅隆大学共同推出。该模型具备编码超长序列的能力——简单理解就是可以更好地理解长句子。2019年末,XLNet 被人工智能领域的顶级学术会议 NeurIPS 2019 接收为 Oral 报告论文(占比 0.5%)。同时,XLNet 也入选了权威的中国人工智能学会《2019人工智能发展报告》,被称为 BERT 之后重要的进展之一。
循环智能(Recurrent AI)正是基于原创的、世界前沿的 XLNet 模型,在智能质检产品中的加速向“语义点”方案转换,取得远超传统方案的效果。过去一年,我们的智能质检系统获得多家金融、教育、互联网服务领域赢得多家标杆客户的商业订单,包括众安保险、玖富、CBC、华道、你我贷、人人贷、新东方在线、猎聘等。> 下篇预告下一篇关于智能质检的文章,我们将向大家介绍,在不同的业务场景下,关键词方案如何与语义点方案高效搭配使用,大幅提升质检效率。


 咨 询 客 服
咨 询 客 服