连续三次夺冠!
五四青年节当日,国际多通道语音分离和识别大赛(CHiME)组委会在线揭晓最新一届CHiME-6成绩:
科大讯飞联合中科大语音及语言信息处理国家工程实验室(USTC-NELSLIP)在给定说话人边界的多通道语音识别两个参赛任务上夺冠。
破自己的纪录!
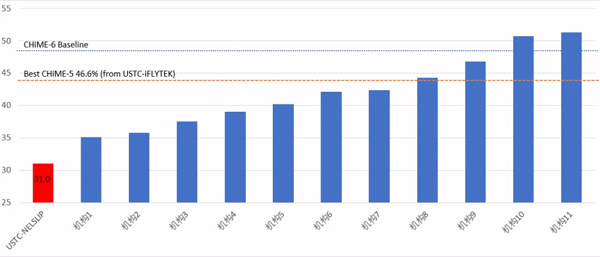
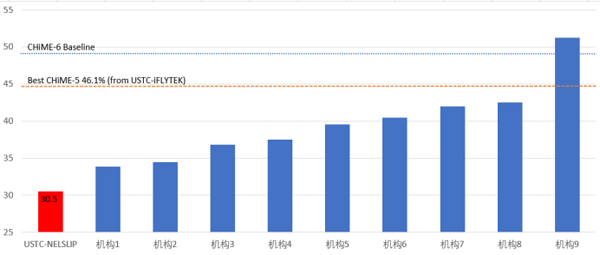
自2016年以来,科大讯飞第三次参加这项国际竞赛并连续夺冠,这次的语音识别错误率从CHiME-5的46.1%降至30.5%。
- 喜报丨科大讯飞包揽CHiME-5全部冠军
- 喜报|科大讯飞包揽CHiME-4三项冠军
CHiME-6被称为“史上最难的语音识别任务”。
和CHiME-5相同,CHiME-6比赛使用的语音素材包括多个生活场景——多人在厨房边做饭边聊天、在起居室边用餐边聊天、在客厅聊天,带来以下四大难点:
- 大量的语音交叠(Speech Overlap)
- 远场混响和噪声干扰对录音的影响
- 对话风格非常自由、近乎随意
- 训练数据有限
CHiME-6音频样本采集于厨房、起居室、客厅等场景的多人对话
本次比赛的Track1任务与CHiME-5相同,即在给定说话人边界的情况下重点考察参赛团队的多通道信号处理能力及复杂场景语音识别能力。新设立的Track2任务要求参赛机构在自动说话人分离的基础上再进行语音识别。
2018年的CHiME-5比赛,最优的参赛系统语音识别错误率仍高达46.1%,距离实用仍有较大差距。今年科大讯飞联合团队重点聚焦于Track1,希望进一步探索复杂场景语音识别实用化的可能性。
通过团队的技术攻关,将该任务上的语音识别错误率从原来的46.1%降至30.5%,大幅刷新该项赛事历史最好成绩,最终在Track1的两个子任务(Track1-RankingA,需使用官方语言模型;Track1-RankingB,不限制语言模型)上均斩获冠军。
科大讯飞夺得CHiME-6冠军(Track1:Ranking A)
科大讯飞夺得CHiME-6冠军(Track1:Ranking B)
同样的考题,跃升的成绩,靠什么?
在远场、混响、噪音、声音叠加、语言风格随意等诸多不确定性的复杂场景下,得益于多年来在真实场景中的技术积累,科大讯飞联合团队针对比赛任务进行了一系列技术创新:
在前端信号处理方面,联合团队提出了基于空间-说话人同步感知的迭代掩码估计算法(Spatial-and-Speaker-Aware Iterative Mask Estimation,SSA-IME),该算法结合传统信号处理和深度学习的优点,利用空时多维信息进行建模,迭代地从多个说话人场景中精确捕捉目标说话人的信息。该算法不仅有效降低环境干扰噪声,而且可以有效消除干扰说话人的语音,从而大幅降低语音识别的处理难度。
在后端声学模型上,联合团队提出了基于空间-说话人同步感知的声学模型(Spatial-and-Speaker-Aware Acoustic Model,SSA-AM),通过在声学模型输入端拼接多维度空间信息和不同说话人信息,使其能自适应区分目标说话人和干扰说话人。因此,声学模型不仅依赖前端算法的处理结果,也能够自适应完成对目标说话人语音特征的提取,大幅提升多人对话场景下语音识别声学模型的容错率和鲁棒性。
语音识别应用场景更有A.I.
科大讯飞致力于智能语音技术的源头创新及行业应用,并不断挑战语音识别实际应用中的技术难题。
2010年发布语音云,持续改善语音输入、语音交互场景的准确率。
2015年发布讯飞听见,逐步提升人人对话场景的准确率。
本次CHiME-6的研究成果无疑将进一步拓展语音识别的应用空间:
促进会议场景语音识别的实用化。相比于CHiME-6的比赛环境,在实际生活中的远距离生活场景中,说话风格随意性减少、语音叠加现象减少、训练数据大幅增加,错误率也会大幅下降。本次比赛的技术成果可应用于讯飞听见智能会议系统升级,进一步促进会议场景语音识别的实用化。
广泛应用于不同的消费产品和服务中。搭载八麦克风阵列的讯飞智能录音笔、能完整记录会议内容的讯飞智能办公本、能免切换识别中英文及23种方言的讯飞输入法,为广大用户解决不同场景下的语音识别需求。
为全球提供多语种智能语音解决方案。得益于英文识别领域的深厚功力,科大讯飞正在大力拓展多语种语音识别方面的技术研究,有望为全球更多企业及消费者提供优质的多语种智能语音解决方案。
让机器能听会说,能理解会思考,用人工智能建设美好世界——这是我们的使命。
此次CHiME-6再夺冠,在“让机器能听”上,我们又迈进了一大步。


 咨 询 客 服
咨 询 客 服