2019年3月25日,小i机器人联合香港科技大学共同成立了“机器学习和认知推理联合实验室”,这是小i机器人与香港学术机构共同开展的首个科研项目,也是小i机器人构建全球研发体系的重要一环。联合实验室的成立,标志着小i机器人的自主创新力和国际影响力得到了进一步提升。
“机器学习和认知推理联合实验室”成立以来,双方在高阶认知推理系统、机器学习和自然语言处理等相关理论及技术研究上,展开了深入合作并实现了多向突破,产出的多篇优质论文也多次登陆ACL、AAAI、AAMAS等国际顶级会议。
以下为香港科技大学-小i机器人联合实验室入选国际顶级会议的代表性论文。
研究方向:问答系统会话生成
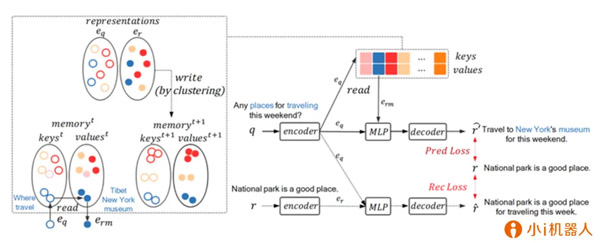
代表性论文:《学习如何抽象:一种记忆增强的会话回复生成》
入选会议:ACL2019
现有的会话回复生成模型存在生成的回复多样性差、信息量不足等一些问题。一些研究人员尝试利用检索系统去增强生成模型的效果,但是该方法受限于检索系统的质量。在本文中,我们提出了一种记忆增强的生成模型,由记忆模块和生成模块组成,它可以对训练语料进行抽象,并且把抽象出来的有用的信息存储在记忆模块中,以便辅助生成模型去生成回复。具体来说,我们的模型会先对用户输入(query)-回复(response)的句对做聚类,接着抽取出每个类的共性,然后让生成模型学习如何利用抽出的共性信息。与普通检索增强模型相比,我们的模型改进了回复生成的质量,相关性和信息完备性。
研究方向:对话系统
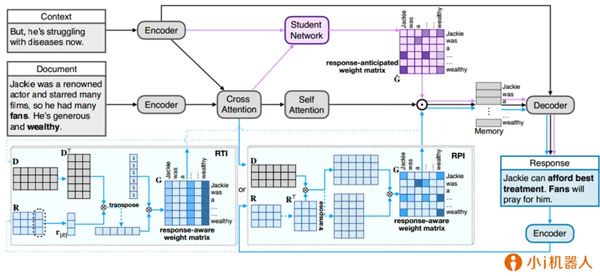
代表性论文:《基于回复预期记忆的随需知识集成机制在回复中的应用》
入选会议:ACL 2020
众所周知,神经对话模型的响应虽然正确,但缺乏足够的内容和信息。通过阅读进行对话(CbR)可以大大增强信息量,其中针对给定的外部文本进行对话,围绕CbR任务,我们提出了一种新颖的预期-回复文本存储,用来利用和记住在回复生成的过程中重要的文本信息。我们通过教-学框架构造了预期的记忆。向教师模块提供了外部文本,上下文和真实的回复,教师请求回复并学习回复-意识权重矩阵;学生模块根据外部文本,上下文和教师模块的输出,学习如何预估教师模型中的权重矩阵,并构建预期的响应文本记忆。我们通过自动和人工评估验证了我们的模型,实验结果表明我们的模型获得了CbR任务的最高性能。
研究方向:机器学习注意力机制
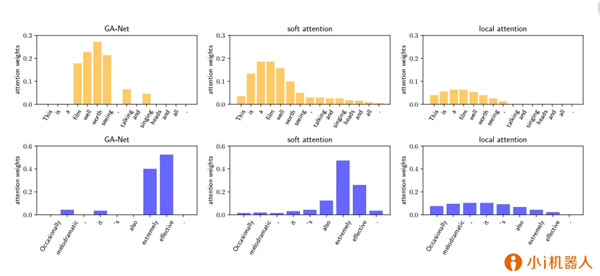
代表性论文:《并非所有的注意力都需要:序列数据的门控注意力网络》
入选会议:AAAI 2020
近年来,动态网络配置受到越来越多的关注,它是一种具有动态连接的卷积机制神经网络,与注意力机制不同,它可以一次选择性地激活一部分网络。在本文中,我们提出了一种用于序列数据的称为门控注意力网络(GA-Net)的新方法。GA-Net使用辅助网络动态选择要参加的元素子集,并计算注意力权重以聚合所选元素。避免了对不必要元素的大量计算,并使模型可以关注序列的重要部分。它结合了两个与输入有关的动态机制,注意力机制和动态网络配置,并具有动态稀疏的注意力结构。实验表明,提出的方法在IMDB、SST-1等文本分类任务上持续获得最佳结果,同时减少需求计算并获得更好的可解释性。
研究方向:多智能体的决策和博弈
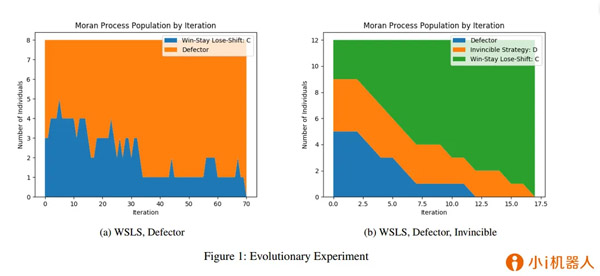
代表性论文:《平均收益重复囚徒困境的无敌策略》
入选会议:AAAI 2020
重复囚徒困境(IPD)是研究理性多智能体的长期行为的著名基准。针对这个问题学术界已经研究了许多众所周知的策略,从简单的针锋相对(TFT)到更复杂的策略,例如Press和Dyson最近研究的零行列式和勒索策略。在本文中,我们考虑了所谓的无敌策略,无敌策略有以下几个特点,首先,他们有一个非常清晰和直观的定义-永远不会输掉一场比赛。其次,它们的特征十分简单-可以被三个简单条件所表示。第三,它们与诸如Press和Dyson的勒索策略以及Akin的good策略等其他经过深思熟虑的策略密切相关。最后,从实验中我们发现,一些既不勒索也不合作的无敌策略也可以像TFT一样发挥作用。我们的策略为重复博弈,尤其是IPD的研究做出了贡献。
研究方向:多智能体的决策和博弈
代表性论文:《重复囚徒困境的无敌策略》
入选会议:AAMAS 2019
重复囚徒困境是研究多智能体博弈的经典经济学模型。各个领域的学者广泛地使用这一模型,来研究合作是如何在多智能体演化过程中产生的。早在1981年,Axelrod组织了基于这一模型的策略竞赛,“针锋相对”策略获得了冠军,对后来的研究产生的深远的影响。2012年以来,随着“零行列式策略”的提出,又涌现出许多具有特殊数学性质的策略。受到我们最初观察的启发,没有任何策略可以击败勒索策略,我们继续研究所有这类立于不败之地的策略。我们的主要技术成果是,此类策略可以被三种简单条件所表示,还将此类策略与其他策略相关联,并考虑了它们在结合时显示的作用。


 咨 询 客 服
咨 询 客 服