前言
深度学习中有很多玩具数据,mnist就是其中一个,一个人能否入门深度学习往往就是以能否玩转mnist数据来判断的,在前面很多基础介绍后我们就可以来实现一个简单的手写数字识别的网络了
数据的处理
我们使用pytorch自带的包进行数据的预处理
import torch
import torchvision
import torchvision.transforms as transforms
import numpy as np
import matplotlib.pyplot as plt
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5), (0.5))
])
trainset = torchvision.datasets.MNIST(root='./data', train=True, download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=32, shuffle=True,num_workers=2)
注释:transforms.Normalize用于数据的标准化,具体实现
mean:均值 总和后除个数
std:方差 每个元素减去均值再平方再除个数
norm_data = (tensor - mean) / std
这里就直接将图片标准化到了-1到1的范围,标准化的原因就是因为如果某个数在数据中很大很大,就导致其权重较大,从而影响到其他数据,而本身我们的数据都是平等的,所以标准化后将数据分布到-1到1的范围,使得所有数据都不会有太大的权重导致网络出现巨大的波动
trainloader现在是一个可迭代的对象,那么我们可以使用for循环进行遍历了,由于是使用yield返回的数据,为了节约内存
观察一下数据
def imshow(img):
img = img / 2 + 0.5 # unnormalize
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))
plt.show()
# torchvision.utils.make_grid 将图片进行拼接
imshow(torchvision.utils.make_grid(iter(trainloader).next()[0]))

构建网络
from torch import nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(in_channels=1, out_channels=28, kernel_size=5) # 14
self.pool = nn.MaxPool2d(kernel_size=2, stride=2) # 无参数学习因此无需设置两个
self.conv2 = nn.Conv2d(in_channels=28, out_channels=28*2, kernel_size=5) # 7
self.fc1 = nn.Linear(in_features=28*2*4*4, out_features=1024)
self.fc2 = nn.Linear(in_features=1024, out_features=10)
def forward(self, inputs):
x = self.pool(F.relu(self.conv1(inputs)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(inputs.size()[0],-1)
x = F.relu(self.fc1(x))
return self.fc2(x)
下面是卷积的动态演示
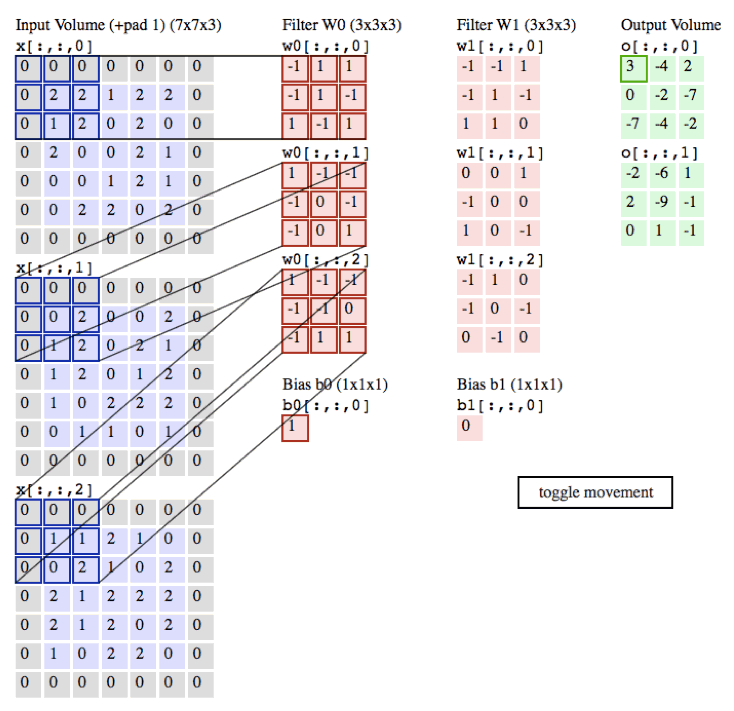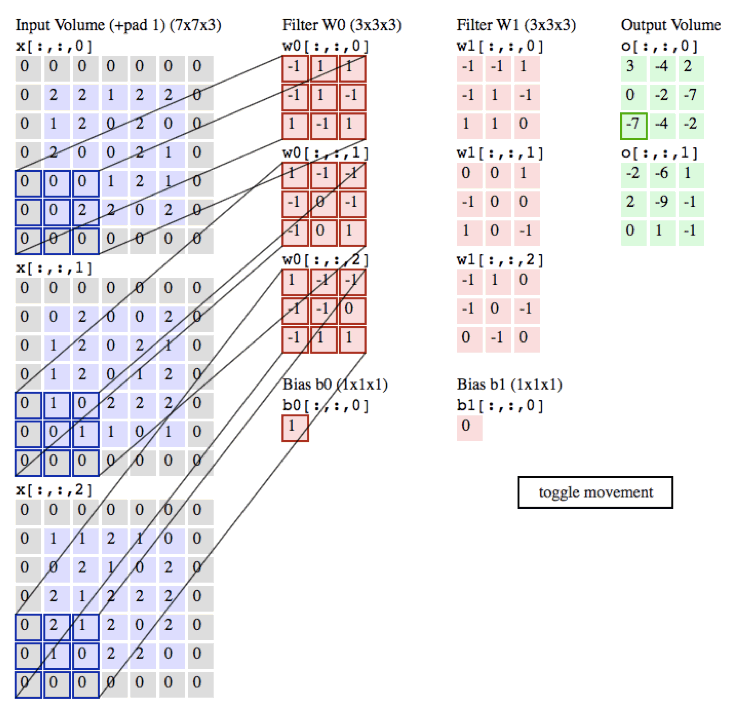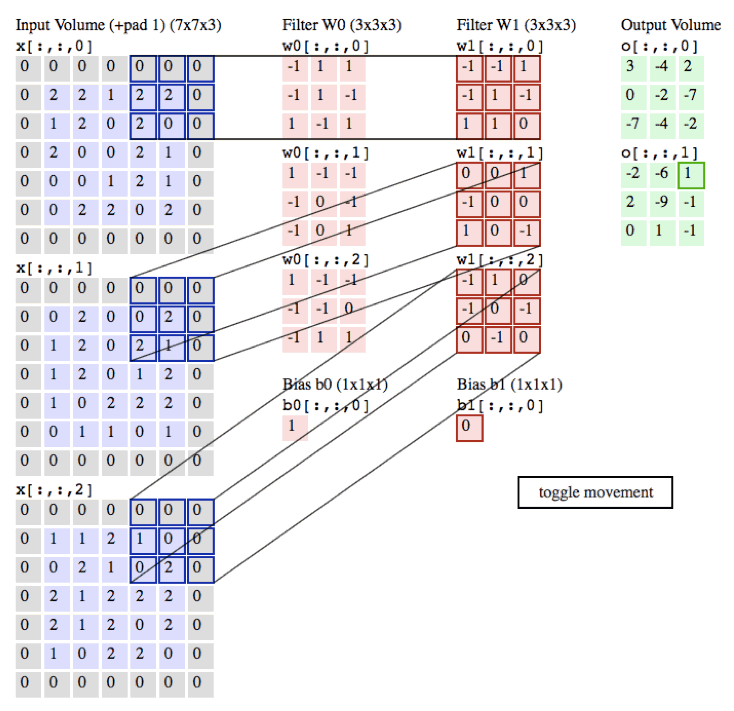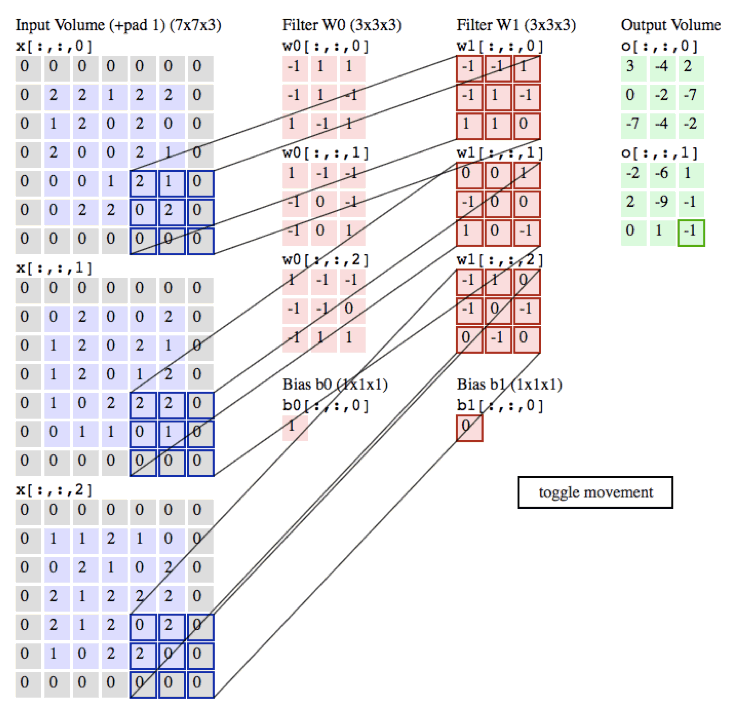
in_channels:为输入通道数 彩色图片有3个通道 黑白有1个通道
out_channels:输出通道数
kernel_size:卷积核的大小
stride:卷积的步长
padding:外边距大小
输出的size计算公式
- h = (h - kernel_size + 2*padding)/stride + 1
- w = (w - kernel_size + 2*padding)/stride + 1
MaxPool2d:是没有参数进行运算的

实例化网络优化器,并且使用GPU进行训练
net = Net()
opt = torch.optim.Adam(params=net.parameters(), lr=0.001)
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
net.to(device)
Net(
(conv1): Conv2d(1, 28, kernel_size=(5, 5), stride=(1, 1))
(pool): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(conv2): Conv2d(28, 56, kernel_size=(5, 5), stride=(1, 1))
(fc1): Linear(in_features=896, out_features=1024, bias=True)
(fc2): Linear(in_features=1024, out_features=10, bias=True)
)
训练主要代码
for epoch in range(50):
for images, labels in trainloader:
images = images.to(device)
labels = labels.to(device)
pre_label = net(images)
loss = F.cross_entropy(input=pre_label, target=labels).mean()
pre_label = torch.argmax(pre_label, dim=1)
acc = (pre_label==labels).sum()/torch.tensor(labels.size()[0], dtype=torch.float32)
net.zero_grad()
loss.backward()
opt.step()
print(acc.detach().cpu().numpy(), loss.detach().cpu().numpy())
F.cross_entropy交叉熵函数

源码中已经帮助我们实现了softmax因此不需要自己进行softmax操作了
torch.argmax计算最大数所在索引值
acc = (pre_label==labels).sum()/torch.tensor(labels.size()[0], dtype=torch.float32)
# pre_label==labels 相同维度进行比较相同返回True不同的返回False,True为1 False为0, 即可获取到相等的个数,再除总个数,就得到了Accuracy准确度了
预测
testset = torchvision.datasets.MNIST(root='./data', train=False, download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=128, shuffle=True,num_workers=2)
images, labels = iter(testloader).next()
images = images.to(device)
labels = labels.to(device)
with torch.no_grad():
pre_label = net(images)
pre_label = torch.argmax(pre_label, dim=1)
acc = (pre_label==labels).sum()/torch.tensor(labels.size()[0], dtype=torch.float32)
print(acc)
总结
本节我们了解了标准化数据·、卷积的原理、简答的构建了一个网络,并让它去识别手写体,也是对前面章节的总汇了
到此这篇关于超详细PyTorch实现手写数字识别器的示例代码的文章就介绍到这了,更多相关PyTorch 手写数字识别器内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
您可能感兴趣的文章:- pytorch 利用lstm做mnist手写数字识别分类的实例
- 详解PyTorch手写数字识别(MNIST数据集)
- PyTorch CNN实战之MNIST手写数字识别示例
- Pytorch实现图像识别之数字识别(附详细注释)


 咨 询 客 服
咨 询 客 服