import pandas as pd
data_dict = {"name":
["Rose", "Jack", "Tom", "Kyle", "Jery", "Adam", "Bill", "David", "Denny", "Evan"],
"class": [1, 2, 3, 1, 2, 3, 1, 2, 3, 1],
"score": [88, 92, 38, 98, 22, 65, 45, 53, 97, 100]}
df = pd.DataFrame(data=data_dict)
df
df = df.groupby('class', sort=False)\
.apply(lambda x:x.sort_values("score", ascending=False))\
.reset_index(drop=True)
df
df["rank"] = None
# 标识班级
flag = df.loc[0].values[1]
rank = 0
for i in range(len(df)):
temp = df.loc[i].values[1]
if (temp == flag).all():
# 同一班级
rank += 1
else:
# 不同班级,重新计算排名
flag = temp
rank = 1
df.loc[i, "rank"] = rank
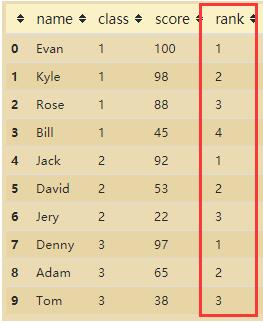
df


 咨 询 客 服
咨 询 客 服