在具体数据的选取上,我爬取的是各省份降水量实时数据
话不多说,开始实操
正文
1.爬取数据
- 使用python爬虫,爬取中国天气网各省份24时整点气象数据
- 由于降水量为动态数据,以js形式进行存储,故采用selenium方法经xpath爬取数据—ps:在进行数据爬取时,最初使用的方法是漂亮汤法(beautifulsoup)法,但当输出爬取的内容(class = split>时,却空空如也。在源代码界面Ctrl+Shift+F搜索后也无法找到降水量,后查询得知此为动态数据,无法用该方法进行爬取
- 使用循环和分类的方式爬取省份不同、网址相似的降水量数据,顺带记录数据对应的城市
f—string:
url_a= f'http://www.weather.com.cn/weather1dn/101{a}0101.shtml'
f-string 用大括号 {} 表示被替换字段,其中直接填入替换内容
将城市和降水量相对应后存入字典再打印
代码:
from lxml import etree
from selenium import webdriver
import re
city = [''for n in range(34)] #存放城市列表
rain = [''for n in range(34)] #存放有关降雨量信息的数值
rain_item = []
driver = webdriver.Chrome(executable_path='chromedriver') #使用chrome浏览器打开
for a in range(1,5): #直辖市数据
url_a= f'http://www.weather.com.cn/weather1dn/1010{a}0100.shtml' #网址
driver.get(url_a) #打开网址
rain_list = []
city_list = []
resp_text = driver.page_source
page_html = etree.HTML(resp_text)
city_list = page_html.xpath('/html/body/div[4]/div[2]/a')[0] #通过xpath爬取城市名称
rain_list = page_html.xpath('//*[@id="weatherChart"]/div[2]/p[5]')[0] #通过xpath爬取降雨量数据
city[a-1] = city_list.text #存入城市列表
rain[a-1] = re.findall(r"\d+\.?\d*",rain_list.text)[0] #存入数值
for a in range(5,10): #一位数字网址数据
url_a= f'http://www.weather.com.cn/weather1dn/1010{a}0101.shtml'
driver.get(url_a)
rain_list = []
city_list = []
resp_text = driver.page_source
page_html = etree.HTML(resp_text)
city_list = page_html.xpath('/html/body/div[4]/div[2]/a')[0] #通过xpath爬取城市名称
rain_list = page_html.xpath('//*[@id="weatherChart"]/div[2]/p[5]')[0] #通过xpath爬取降雨量数据
city[a-1] = city_list.text #存入城市列表
rain[a-1] = re.findall(r"\d+\.?\d*",rain_list.text)[0] #存入数值
for a in range(10,35): #二位数字网址数据
url_a= f'http://www.weather.com.cn/weather1dn/101{a}0101.shtml'
driver.get(url_a)
rain_list = []
city_list = []
resp_text = driver.page_source
page_html = etree.HTML(resp_text)
city_list = page_html.xpath('/html/body/div[4]/div[2]/a')[0] #通过xpath爬取城市名称
rain_list = page_html.xpath('//*[@id="weatherChart"]/div[2]/p[5]')[0] #通过xpath爬取降雨量数据
city[a-1] = city_list.text #存入城市列表
rain[a-1] = re.findall(r"\d+\.?\d*",rain_list.text)[0] #存入数值
d = dict(zip(city,rain)) #将城市和降水量的列表合成为字典
for k,v in d.items(): #str转float类型
rain_item.append(float(v))
print(d)
在对爬取的内容进行处理时,可能会因为数据的类型而报错,如爬下来的数据为str类型,而排序需要数字类型,故需要进行float类型转化
使用该爬取方法,是模拟用户打开网页,并且会在电脑上进行显示。在爬取实验进行中途,中国天气网进行了网址更新,原网址出现了部分城市数据无法显示的问题,但当刷新界面后,数据可正常显示,此时可采用模拟鼠标点击刷新的方法避免错误。由于后续找到了新网址,故将这一方法省去。
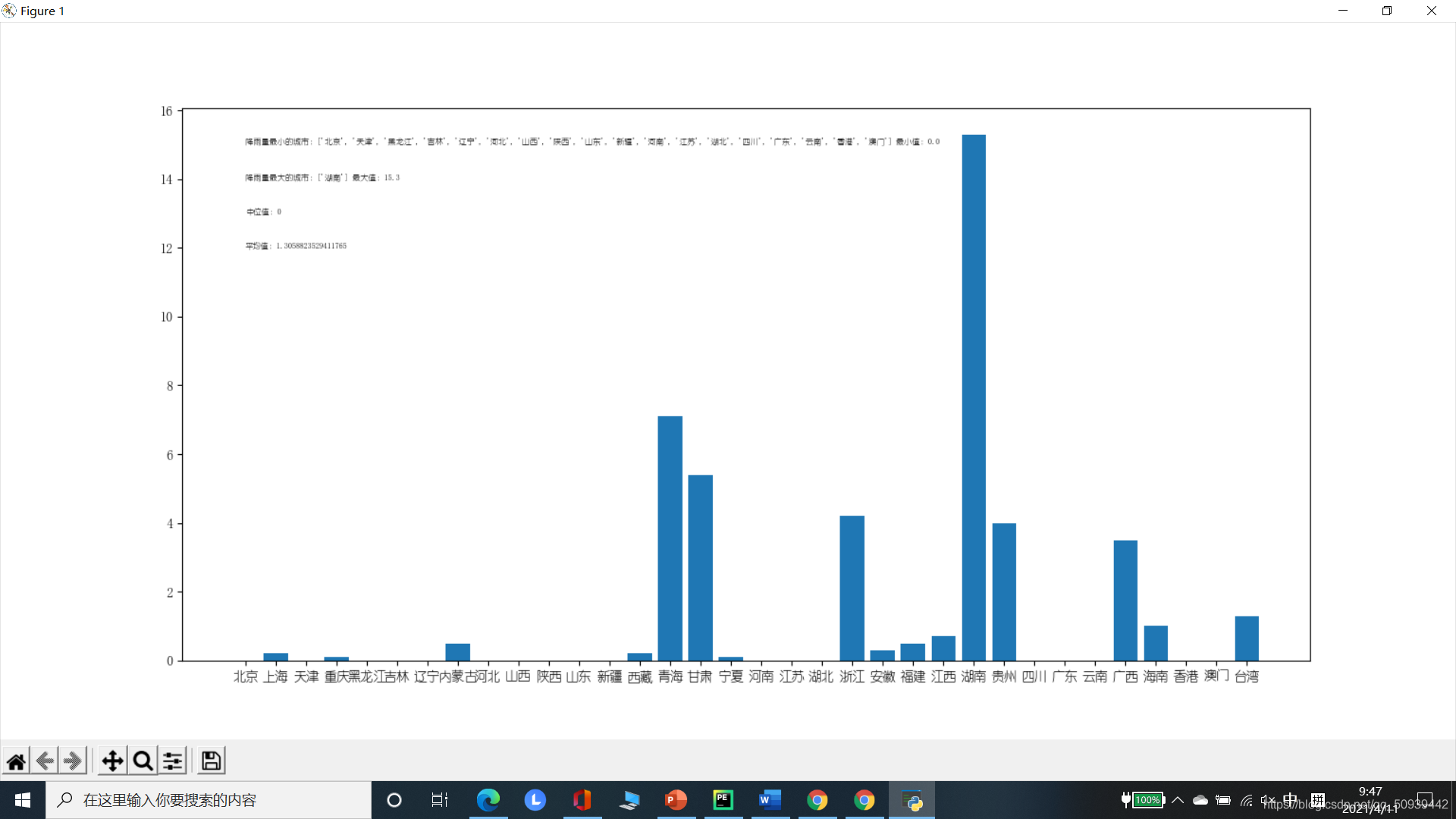
2.数据可视化
- 用Matplotlib库函数绘制曲线,并输出最大值及相应城市、最小值及相应城市、平均值和中位值
- 数据的确定:medium分奇偶计算中位值所处排序后数据的位置(中位值);用sum求和后除于数据个数(平均值);max和min函数找到最值再由数值经循环找到对应的城市列表
- 绘图:使用plt函数绘制图像,并注明横纵坐标、所需注释
- 文本处理:在进行注释时,plt函数所要求的格式为str类型,故需要进行类型转换,同时添加适当文字说明
代码:
#-*- codeing = utf-8 -*-
import matplotlib.pyplot as plt
from lxml import etree
from selenium import webdriver
import re
import matplotlib
matplotlib.rc("font",family='YouYuan')
city = [''for n in range(34)] #存放城市列表
rain = [''for n in range(34)] #存放有关降雨量信息的数值
driver = webdriver.Chrome(executable_path='chromedriver') #使用chrome浏览器打开
for a in range(1,5): #直辖市数据
url_a= f'http://www.weather.com.cn/weather1dn/1010{a}0100.shtml' #网址
driver.get(url_a) #打开网址
rain_list = []
city_list = []
resp_text = driver.page_source
page_html = etree.HTML(resp_text)
city_list = page_html.xpath('/html/body/div[4]/div[2]/a')[0] #通过xpath爬取城市名称
rain_list = page_html.xpath('//*[@id="weatherChart"]/div[2]/p[5]')[0] #通过xpath爬取降雨量数据
city[a-1] = city_list.text #存入城市列表
rain[a-1] = re.findall(r"\d+\.?\d*",rain_list.text)[0] #存入数值
for a in range(5,10): #非直辖一位数字网址数据
url_a= f'http://www.weather.com.cn/weather1dn/1010{a}0101.shtml'
driver.get(url_a)
rain_list = []
city_list = []
resp_text = driver.page_source
page_html = etree.HTML(resp_text)
city_list = page_html.xpath('/html/body/div[4]/div[2]/a')[0] #通过xpath爬取城市名称
rain_list = page_html.xpath('//*[@id="weatherChart"]/div[2]/p[5]')[0] #通过xpath爬取降雨量数据
city[a-1] = city_list.text #存入城市列表
rain[a-1] = re.findall(r"\d+\.?\d*",rain_list.text)[0] #存入数值
for a in range(10,35): #非直辖二位数字网址数据
url_a= f'http://www.weather.com.cn/weather1dn/101{a}0101.shtml'
driver.get(url_a)
rain_list = []
city_list = []
resp_text = driver.page_source
page_html = etree.HTML(resp_text)
city_list = page_html.xpath('/html/body/div[4]/div[2]/a')[0] #通过xpath爬取城市名称
rain_list = page_html.xpath('//*[@id="weatherChart"]/div[2]/p[5]')[0] #通过xpath爬取降雨量数据
city[a-1] = city_list.text #存入城市列表
rain[a-1] = re.findall(r"\d+\.?\d*",rain_list.text)[0] #存入数值
if len(rain)%2 == 0: #寻找中值
medium = int(len(rain)/2)
else:
medium = int(len(rain)/2)+1
medium_text = "中位值:" + rain[medium]
d = dict(zip(city,rain)) #将城市和降水量的列表合成为字典
rain_item = []
city_min = []
city_max = []
for k,v in d.items():
rain_item.append(float(v))
average_rain = sum(rain_item)/len(rain_item)
average_text = "平均值:"+ str(average_rain)
max_rain = max(rain_item) #最大值
min_rain = min(rain_item) #最小值
for k,v in d.items():
if float(v) == min_rain:
city_min.append(k)
min_text = "降雨量最小的城市:"+str(city_min)+" 最小值:"+str(min_rain)
for k,v in d.items():
if float(v) ==max_rain:
city_max.append(k)
max_text = "降雨量最大的城市:"+str(city_max)+" 最大值:"+str(max_rain)
plt.bar(range(len(d)), rain_item, align='center')
plt.xticks(range(len(d)), list(d.keys()))
plt.xlabel('城市',fontsize=20)
plt.ylabel('降水量',fontsize=20)
plt.text(0,12,average_text,fontsize=6)
plt.text(0,13,medium_text,fontsize=6)
plt.text(0,14,max_text,fontsize=6)
plt.text(0,15,min_text,fontsize=6)
plt.show()
2.运行界面
3.互动界面
使用tkinter库进行GUI的构建使用button函数实现交互,调用编写的get函数获取对用户输入的内容进行获取并使用循环进行遍历处理,若城市输入正确,则在界面上输出当地的降水量代码:
#-*- codeing = utf-8 -*-
from lxml import etree
from selenium import webdriver
import re
import matplotlib
matplotlib.rc("font",family='YouYuan')
from tkinter import *
import tkinter as tk
city = [''for n in range(34)] #存放城市列表
rain = [''for n in range(34)] #存放有关降雨量信息的数值
driver = webdriver.Chrome(executable_path='chromedriver') #使用chrome浏览器打开
for a in range(1,5): #直辖市数据
url_a= f'http://www.weather.com.cn/weather1dn/1010{a}0100.shtml' #网址
driver.get(url_a) #打开网址
rain_list = []
city_list = []
resp_text = driver.page_source
page_html = etree.HTML(resp_text)
city_list = page_html.xpath('/html/body/div[4]/div[2]/a')[0] #通过xpath爬取城市名称
rain_list = page_html.xpath('//*[@id="weatherChart"]/div[2]/p[5]')[0] #通过xpath爬取降雨量数据
city[a-1] = city_list.text #存入城市列表
rain[a-1] = re.findall(r"\d+\.?\d*",rain_list.text)[0] #存入数值
for a in range(5,10): #非直辖一位数字网址数据
url_a= f'http://www.weather.com.cn/weather1dn/1010{a}0101.shtml'
driver.get(url_a)
rain_list = []
city_list = []
resp_text = driver.page_source
page_html = etree.HTML(resp_text)
city_list = page_html.xpath('/html/body/div[4]/div[2]/a')[0] #通过xpath爬取城市名称
rain_list = page_html.xpath('//*[@id="weatherChart"]/div[2]/p[5]')[0] #通过xpath爬取降雨量数据
city[a-1] = city_list.text #存入城市列表
rain[a-1] = re.findall(r"\d+\.?\d*",rain_list.text)[0] #存入数值
for a in range(10,35): #非直辖二位数字网址数据
url_a= f'http://www.weather.com.cn/weather1dn/101{a}0101.shtml'
driver.get(url_a)
rain_list = []
city_list = []
resp_text = driver.page_source
page_html = etree.HTML(resp_text)
city_list = page_html.xpath('/html/body/div[4]/div[2]/a')[0] #通过xpath爬取城市名称
rain_list = page_html.xpath('//*[@id="weatherChart"]/div[2]/p[5]')[0] #通过xpath爬取降雨量数据
city[a-1] = city_list.text #存入城市列表
rain[a-1] = re.findall(r"\d+\.?\d*",rain_list.text)[0] #存入数值
d = dict(zip(city,rain)) #将城市和降水量的列表合成为字典
root=tk.Tk()
root.title('降水量查询')
root.geometry('500x200')
def get():
values = entry.get()
for k,v in d.items():
if k == values:
label = Label(root, text= v+'mm')
label.pack()
frame = Frame(root)
frame.pack()
u1 = tk.StringVar()
entry = tk.Entry(frame, width=20, textvariable=u1, relief="sunken")
entry.pack(side="left")
frame1 = Frame(root)
frame1.pack()
btn1=Button(frame1, text="查询", width=20, height=1, relief=GROOVE, command=lambda :get())
btn1.pack(side="left")
root.mainloop()
4.运行界面

写在最后
在爬取天气的过程中,仅发现中国天气网有各省份降水量的数据,可见我国在数据开源方面还有很长的路要走
到此这篇关于python爬取各省降水量及可视化详解的文章就介绍到这了,更多相关python爬取请搜索脚本之家以前的文章或继续浏览下面的相关文章,希望大家以后多多支持脚本之家!
您可能感兴趣的文章:- Python编写可视化界面的全过程(Python+PyCharm+PyQt)
- Python实现K-means聚类算法并可视化生成动图步骤详解
- python数据分析之员工个人信息可视化
- 关于Python可视化Dash工具之plotly基本图形示例详解
- python用pyecharts实现地图数据可视化
- Python绘制K线图之可视化神器pyecharts的使用
- Python绘制词云图之可视化神器pyecharts的方法
- python 可视化库PyG2Plot的使用
- Python数据分析之彩票的历史数据
- Python 数据分析之逐块读取文本的实现
- Python数据分析库pandas高级接口dt的使用详解
- Python Pandas数据分析工具用法实例
- 用Python 爬取猫眼电影数据分析《无名之辈》
- 大数据分析用java还是Python
- python 数据分析实现长宽格式的转换
- PyCharm设置Ipython交互环境和宏快捷键进行数据分析图文详解
- Python实战之疫苗研发情况可视化


 咨 询 客 服
咨 询 客 服