申明:资料来源于网络及书本,通过理解、实践、整理成学习笔记。
Pythion的Selenium自动化测试之获取哔哩哔哩主播的头像以昵称命名保存到本地文件
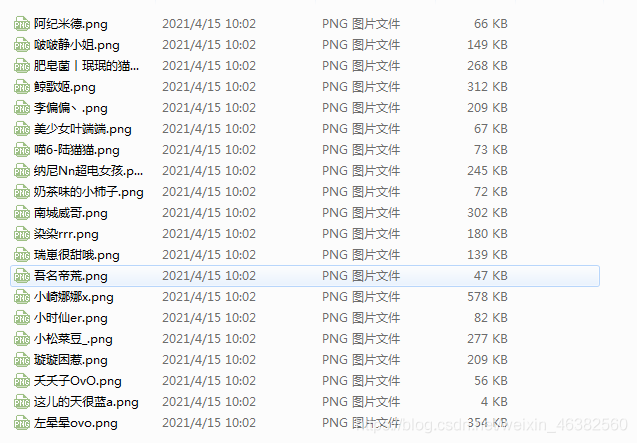
效果图
方法1
通过接口获取
首先使用pip下载requests包
pip install requests
import requests
# 通过接口获取请求的接口:想要获取网页的url
url = 'https://api.live.bilibili.com/xlive/web-interface/v1/second/getList?platform=webparent_area_id=1area_id=0sort_type=sort_type_152page=1'
# 发送get请求,获取返回数据
request = requests.get(url)
# 保存图片的路径
dir = '../requests/bilibili/'
# 将获取的数据转化为json文件并获取到图片的链接
info = request.json()['data']['list']
for i in info:
# 将图片以主播的昵称命名
file = open(dir + '{}.png'.format(i['uname']), 'wb')
# 将图片保存到之前的路径
file.write(requests.get(i['face']).content)
# 关闭文件流
file.close()
方法2
通过html定位获取
首先使用pip下载requests和selenium包
pip install requests
pip install selenium

import requests
from selenium import webdriver
# 使用谷歌驱动打开谷歌浏览器
driver = webdriver.Chrome()
# 访问哔哩哔哩直播页面
driver.get('https://live.bilibili.com/p/eden/area-tags?visit_id=2mwktlg4e2q0areaId=0parentAreaId=1')
# 循环30次一次保存的头像图片
for i in range(1, 31):
# xpth定位头像的位置
image_xpath = '/html/body/div[1]/div[3]/div/ul/li[{}]/a/div[1]/div/div'.format(i)
# 获取位置的style属性值
image_style_value = driver.find_element_by_xpath(image_xpath).get_attribute('style')
# 从style属性值中切片出图片的链接
image_url = image_style_value[image_style_value.find('h'):image_style_value.find('@'):1]
# xpath定位昵称的位置
title_xpath = '/html/body/div[1]/div[3]/div/ul/li[{}]/a/div[2]/div[2]/div/span'.format(i)
# 获取位置的title值
name_title_value = driver.find_element_by_xpath(title_xpath).get_attribute('title')
print(image_url)
# 发送get请求,获取返回数据
request = requests.get(image_url)
# 保存图片的路径
file = open('D:Python Projects/requests/bilibili/{}.jpg'.format(name_title_value), 'wb')
# 将图片保存到路径
file.write(request.content)
# 关闭文件流
file.close()
最后,在为大家增加一个获取b站视频信息的操作代码
# coding:utf-8
import requests
import json
import time
import pymysql
import bs4
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36'
}
result = []
def get_aid(page):
url = 'https://search.bilibili.com/all?keyword=爬虫from_source=nav_searchspm_id_from=333.851.b_696e7465726e6174696f6e616c486561646572.11' + 'page=' + str(page)
response = requests.get(url, headers=headers, verify=False).text
time.sleep(1)
try:
soup = bs4.BeautifulSoup(response, 'lxml').find('div', attrs={'id':'all-list'}).find('div', attrs={'class':'mixin-list'})
ul = soup.find('ul', attrs={'class':'video-list clearfix'}).find_all('li', attrs={'class':'video-item matrix'})
for item in ul:
# print(item)
info = item.find('div', attrs={'class': 'headline clearfix'}).find('span', attrs={'class': 'type avid'}).get_text()
aid = info.replace('av', '')
print(aid)
result.append(aid)
return result
except:
print('something is wrong')
def get_contents(url):
response = requests.get(url=url, headers=headers, verify=False).json()
time.sleep(1)
try:
data_1 = response['data']
data = data_1['stat']
aid = data['aid']
view = data['view']
coin = data['coin']
like = data['like']
favorite = data['favorite']
share = data['share']
danmaku = data['danmaku']
print('视频编号', aid)
print('观看数量', view)
print('投币数量', coin)
print('收藏数量', favorite)
print('点赞数量', like)
print('分享数量', share)
print('弹幕数量', danmaku)
except:
print('------------')
if __name__ == '__main__':
for i in range(1, 50):
result = get_aid(i)
for i in result:
url = 'https://api.bilibili.com/x/web-interface/view?aid=' + str(i)
get_contents(url)
到此这篇关于Selenium爬取b站主播头像并以昵称命名保存到本地的文章就介绍到这了,希望对大家有所帮助,更多相关python爬取内容请搜索脚本之家以前的文章或继续浏览下面的相关文章,希望大家以后多多支持脚本之家!
您可能感兴趣的文章:- python爬取晋江文学城小说评论(情绪分析)
- Python如何利用正则表达式爬取网页信息及图片
- 用基于python的appium爬取b站直播消费记录
- Python爬虫之爬取2020女团选秀数据
- 用python爬虫爬取CSDN博主信息


 咨 询 客 服
咨 询 客 服