手写数字识别算法
import pandas as pd
import numpy as np
from sklearn.neural_network import MLPRegressor #从sklearn的神经网络中引入多层感知器
data_tr = pd.read_csv('BPdata_tr.txt') # 训练集样本
data_te = pd.read_csv('BPdata_te.txt') # 测试集样本
X=np.array([[0.568928884039633],[0.379569493792951]]).reshape(1, -1)#预测单个样本
#参数:hidden_layer_sizes中间层的个数 activation激活函数默认relu f(x)= max(0,x)负值全部舍去,信号相应正向传播效果好
#random_state随机种子,max_iter最大迭代次数,即结束,learning_rate_init学习率,学习速度,步长
model = MLPRegressor(hidden_layer_sizes=(10,), activation='relu',random_state=10, max_iter=8000, learning_rate_init=0.3) # 构建模型,调用sklearn实现神经网络算法
model.fit(data_tr.iloc[:, :2], data_tr.iloc[:, 2]) # 模型训练(将输入数据x,结果y放入多层感知器拟合建立模型) .iloc是按位置取数据
pre = model.predict(data_te.iloc[:, :2]) # 模型预测(测试集数据预测,将实际结果与预测结果对比)
pre1 = model.predict(X)#预测单个样本,实际值0.467753075712819
err = np.abs(pre - data_te.iloc[:, 2]).mean()# 模型预测误差(|预测值-实际值|再求平均)
print("模型预测值:",pre,end='\n______________________________\n')
print('模型预测误差:',err,end='\n++++++++++++++++++++++++++++++++\n')
print("单个样本预测值:",pre1,end='\n++++++++++++++++++++++++++++++++\n')
#查看相关参数。
print('权重矩阵:','\n',model.coefs_) #list,length n_layers - 1,列表中的第i个元素表示对应于层i的权重矩阵。
print('偏置矩阵:','\n',model.intercepts_) #list,length n_layers - 1,列表中的第i个元素表示对应于层i + 1的偏置矢量。

数字手写识别系统
#数字手写识别系统,DBRHD和MNIST是数字手写识别的数据集
import numpy as np # 导入numpy工具包
from os import listdir # 使用listdir模块,用于访问本地文件
from sklearn.neural_network import MLPClassifier #从sklearn的神经网络中引入多层感知器
#自定义函数,将图片转换成向量
def img2vector(fileName):
retMat = np.zeros([1024], int) # 定义返回的矩阵,大小为1*1024
fr = open(fileName) # 打开包含32*32大小的数字文件
lines = fr.readlines() # 读取文件的所有行
for i in range(32): # 遍历文件所有行
for j in range(32): # 并将01数字存放在retMat中
retMat[i * 32 + j] = lines[i][j]
return retMat
#自定义函数,获取数据集
def readDataSet(path):
fileList = listdir(path) # 获取文件夹下的所有文件
numFiles = len(fileList) # 统计需要读取的文件的数目
dataSet = np.zeros([numFiles, 1024], int) # 用于存放所有的数字文件juzheng
hwLabels = np.zeros([numFiles, 10]) # 用于存放对应的one-hot标签(每个文件都对应一个10列的矩阵)
for i in range(numFiles): # 遍历所有的文件
filePath = fileList[i] # 获取文件名称/路径
digit = int(filePath.split('_')[0]) # 通过文件名获取标签,split返回分割后的字符串列表
hwLabels[i][digit] = 1.0 # 将对应的one-hot标签置1 .one-hot编码,又称独热编码、一位有效编码.one-hot向量将类别变量转换为机器学习算法易于利用的一种形式的过程,这个向量的表示为一项属性的特征向量,也就是同一时间只有一个激活点(不为0),这个向量只有一个特征是不为0的,其他都是0,特别稀疏。
dataSet[i] = img2vector(path + '/' + filePath) # 读取文件内容
return dataSet, hwLabels
#读取训练数据,并训练模型
train_dataSet, train_hwLabels = readDataSet('trainingDigits')
#参数:hidden_layer_sizes中间层的个数,activation激活函数 logistic:f(x)=1/(1+exp(-x))将值映射在一个0~1的范围内。
#solver权重优化的求解器adam默认,用于较大的数据集,lbfgs用于小型的数据集收敛的更快效果更好。max_iter迭代次数越多越准确
clf = MLPClassifier(hidden_layer_sizes=(50,),activation='logistic', solver='adam',learning_rate_init=0.001, max_iter=700)
clf.fit(train_dataSet, train_hwLabels)#数据集,标签,拟合
# 读取测试数据对测试集进行预测
dataSet, hwLabels = readDataSet('testDigits')
res = clf.predict(dataSet) #预测结果是标签([numFiles, 10]的矩阵)
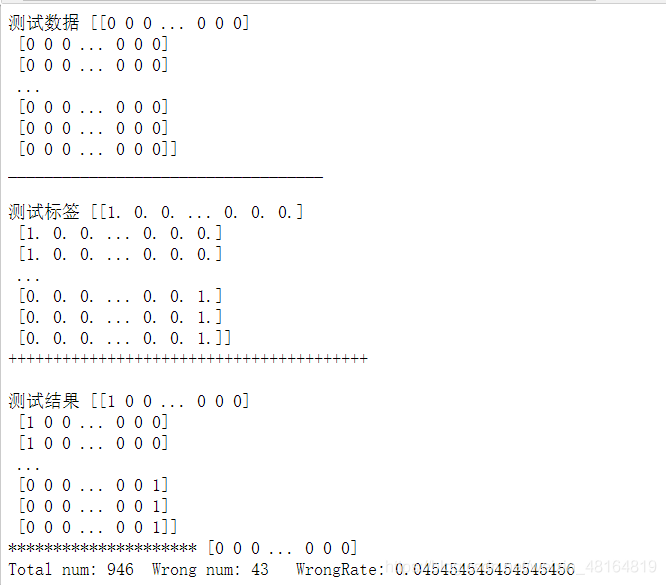
print("测试数据",dataSet,'\n___________________________________\n')
print("测试标签",hwLabels,'\n++++++++++++++++++++++++++++++++++++++++\n')
print("测试结果",res)
error_num = 0 # 统计预测错误的数目
num = len(dataSet) # 测试集的数目
for i in range(num): # 遍历预测结果
# 比较长度为10的数组,返回包含01的数组,0为不同,1为相同
# 若预测结果与真实结果相同,则10个数字全为1,否则不全为1
if np.sum(res[i] == hwLabels[i]) 10:
error_num += 1
print("Total num:", num, " Wrong num:",error_num, " WrongRate:", error_num / float(num))
可视化MNIST是数字手写识别的数据集
from keras.datasets import mnist#导入数字手写识别系统的数据集
import matplotlib.pyplot as plt
(X_train, y_train), (X_test, y_test) = mnist.load_data()
#以2*2(2行2列)图的方式展现
plt.subplot(221)
plt.imshow(X_train[1], cmap=plt.get_cmap('gray_r'))#白底黑字
plt.subplot(222)
plt.imshow(X_train[2], cmap=plt.get_cmap('gray'))#黑底白字
plt.subplot(223)
plt.imshow(X_train[3], cmap=plt.get_cmap('gray'))
plt.subplot(224)
plt.imshow(X_train[4], cmap=plt.get_cmap('gray'))
# show the plot
plt.show()

到此这篇关于python机器学习之神经网络的文章就介绍到这了,更多相关python神经网络内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
您可能感兴趣的文章:- numpy创建神经网络框架
- 教你使用Python建立任意层数的深度神经网络
- python神经网络编程之手写数字识别
- pytorch动态神经网络(拟合)实现
- Python如何使用神经网络进行简单文本分类
- pytorch之深度神经网络概念全面整理


 咨 询 客 服
咨 询 客 服