目录
- 一、图示
- 二、前期准备
- 三、pdf转word
- 四、GUI设计
- 五、打包代码
一、图示
上面为pdf截图内容,下面为转化后的word截图内容

接下来,我们试试自己动作写这个工具吧!
二、前期准备
由于我们采用的是python进行工具编写,并最终需要打包成一个exe文件供我们使用。为了降低包体大小,我们需要先创建一个虚拟环境备用。
另外,pdf转word有现成的第三方库pdf2docx,同时关于gui我们用的是pysimplegui,打包成exe采用的是pyinstaller。在创建虚拟环境后,我们将这些需要用到的第三方库也一一安装吧。
# 创建虚拟环境
conda create -n env_pdf python=3.8.8
# 激活虚拟环境
conda activate env_pdf
# 安装三个库
pip install pdf2docx
pip install pysimplegui
pip install pyinstaller
关于这三个库,大家可以查阅官方文档了解更多:
pdf2word : https://dothinking.github.io/pdf2docx/index.html
pysimplegui:https://pysimplegui.readthedocs.io/en/latest/
pyinstaller:http://www.pyinstaller.org/
前期准备工具就绪,我们开始进入工具编写阶段。
三、pdf转word
pdf转word感觉是一个存在已久的话题,现在其实市面上很多工具可以使用,不过完全免费的可能需要认真找找。
我们知道python有很多处理pdf文档的第三方库以及处理word的第三方库,所以有人就将这两类库的功能进行了整合,从而有了今天的主角pdf2docx。
基本思路:
- 利用
PyMuPDF获取页面元素,例如文本和形状及其位置
- 再利用元素间的相对位置关系推断内容
- 最后使用
python-docx将上一步解析的内容元素重建为docx格式的Word文档
基于以上情况,咱们这个工具在进行操作的时候会存在以下不足:
- 无法识别和重建PDF扫描件
- 根据有限的、确定的规则建立PDF与docx元素之间的映射并非完全可靠,也就是说仅能处理常见的规范的格式,而非百分百还原
当然,以上这些我们都不用管,直接参考官方给到的代码即可:
from pdf2docx import Converter
import re
# 传入文件绝对路径
def pdf_to_word(fileName):
pdf_file = fileName
# 正则获取不含文件类型后缀的部分,用于组成word文档绝对路径
name = re.findall(r'(.*?)\.',pdf_file)[0]
docx_file = f'{name}.docx'
cv = Converter(pdf_file)
cv.convert(docx_file, start=0, end=None)
cv.close()
其中,start和end参数指定待转换pdf文档的页码范围(默认是从0开始到最后一页);也可以通过pages指定不连续的页面,例如pages=[1,3,5]。
四、GUI设计
关于pdf转word的功能,我们需要的就是选择待转化的文件、开始转化即可,另外记录一下操作流让我们知道进度就完美了。所以,功能其实很简单,我们基于以上功能设计简单的GUI如下:
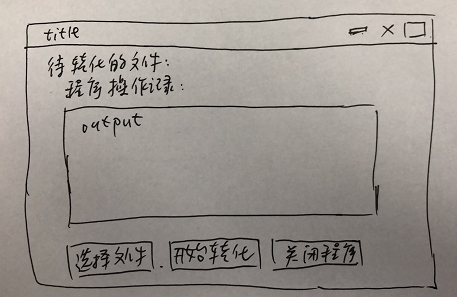
ue设计手稿
由于我们这次用到的是pysimplegui这个超级简单好用的工具库,那么为了满足以上功能,编码如下(思路见注释)。
import PySimpleGUI as sg
import re
# 主题设置
sg.theme('DarkTeal7')
# 布局设置
layout = [
[sg.Text('待转化的文件是:',font=("微软雅黑", 12)),sg.Text('',key='filename',size=(50,1),font=("微软雅黑", 10),text_color='blue')],
[sg.Text('程序操作记录',justification='center')],
[sg.Output(size=(80, 20),font=("微软雅黑", 10))],
[sg.FileBrowse('选择文件',key='file',target='filename'),sg.Button('开始转化'),sg.Button('关闭程序')]
]
# 创建窗口
window = sg.Window('pdf转word工具,作者@微信公众号:可以叫我才哥', layout,font=("微软雅黑", 15),default_element_size=(50,1))
# 事件循环
while True:
event, values = window.read()
if event in (None, '关闭程序'):
break
if event == '开始转化':
if values['file'] and re.findall(r'\.(\S+)',values['file'])[0]=='pdf':
fileName = values['file']
pdf_to_word(fileName)
print('\n----------转化完毕----------\n')
else:
print('文件未选取或文件非pdf文件\n请先选择文件')
window.close()
不得不说,确实会比PyQt5要来的简单。
sg.theme('DarkTeal7')是设置gui的主题,pysimplegui提供很多主题,大家可以自由选择;
layout就是设置布局,具体我们根据UE手稿需求从上到下依次设置:
sg.Text()设置文本内容和格式sg.Output()设置print输出的地方sg.FileBrowse()设置文件选择浏览器,key是指定健名称,target是选定的文件夹名sg.Button()设置按钮sg.Window()是创建窗口,可以带窗口名称等信息
event和values是当执行window.read()函数时的返回值:其中event是事件,如点击按钮、选择文件等;values是包含输入的值,比如我们选择文件后的文件名信息值。
结合之前的pdf转word函数,这里的逻辑如下:
当我们点击开始转化按钮,先判断是否选择了pdf文件,如果是则执行转化函数,否则就提示文件未选择或选择的非pdf文件。
五、打包代码
这里采用的是pyinstaller进行程序代码打包,操作指令如下:
pyinstaller -F -w pdf转word小工具.py
部分参数含义:
-F 表示生成单个可执行文件
-w 表示去掉控制台窗口,这在GUI界面时非常有用
-p 表示你自己自定义需要加载的类路径,一般情况下用不到
-i 表示可执行文件的图标
其实,最新版本的word(office2019)已经天然支持对非扫描版pdf的读取和转化了,大家通过以下流程进行处理:文档—>打开—>选择待转化pdf文件即可。
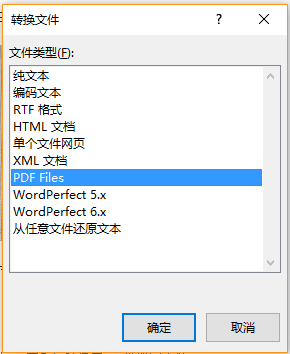
office-word自带转化功能
到此这篇关于只用40行Python代码就能写出pdf转word小工具的文章就介绍到这了,更多相关pdf转word小工具内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
您可能感兴趣的文章:- 使用Python 统计文件夹内所有pdf页数的小工具
- 20行Python代码实现一款永久免费PDF编辑工具的实现
- 用python 制作图片转pdf工具
- Python开发的单词频率统计工具wordsworth使用方法
- Python快速优雅的批量修改Word文档样式
- python提取word文件中的所有图片
- 教你如何利用Python批量翻译英文Word文档并保留格式
- 详解用Python把PDF转为Word方法总结
- 使用python处理一万份word表格简历操作
- python 三种方法提取pdf中的图片


 咨 询 客 服
咨 询 客 服