一、前言
matplotlib是一个用于创建出版质量图表的桌面绘图包(主要是2D方面)。该项目是由John Hunter于2002年启动的,其目的是为Python构建一个MATLAB式的绘图接口。matplotlib和IPython社区进行合作,简化了从IPython shell(包括现在的Jupyter notebook)进行交互式绘图。matplotlib支持各种操作系统上许多不同的GUI后端,而且还能将图片导出为各种常见的矢量(vector)和光栅(raster)图:PDF、SVG、JPG、PNG、BMP、GIF等。除了几张,本书中的大部分图都是用它生成的。
对于创建用于打印或网页的静态图形,我建议默认使用matplotlib和附加的库,比如pandas和seaborn。对于交互式图形以便在Web上发布,可以使用Plotly和Boken
学习本章代码案例的最简单方法是在Jupyter notebook进行交互式绘图。在Jupyter notebook中执行下面的语句:%matplotlib notebook
二、matplotlib API 入门
1.引入matplotlib,并创建简单的图形
import matplotlib.pyplot as plt
import numpy as np
data = np.arange(10)
plt.plot(data)
虽然seaborn这样的库和pandas的内置绘图函数能够处理许多普通的绘图任务,但如果需要自定义一些高级功能的话就必须学习matplotlib API。matplotlib的示例库和文档是学习高级特性的最好资源。
2.matplotlib的图像都位于Figure对象中。你可以用plt.figure创建一个新的Figure,但不能通过空Figure绘图。必须用add_subplot创建一个或多个subplot才行:
fig = plt.figure()
ax1 = fig.add_subplot(2, 2, 1)
ax2 = fig.add_subplot(2, 2, 2)
ax3 = fig.add_subplot(2, 2, 3)
plt.plot(np.random.randn(50).cumsum(), 'k--') # 在最后一个用过的subplot上进行绘制,隐藏创建figure和subplot的过程
提示:使用Jupyter notebook有一点不同,即每个小窗重新执行后,图形会被重置。因此,对于复杂的图形,,你必须将所有的绘图命令存在一个小窗里。
由fig.add_subplot所返回的对象是AxesSubplot对象,直接调用它们的实例方法就可以在其它空着的格子里面画图了
ax1.hist(np.random.randn(100), bins=20, color='k', alpha=0.3)
ax2.scatter(np.arange(30), np.arange(30) + 3 * np.random.randn(30))
3.plt.subplots,它可以创建一个新的Figure,并返回一个含有已创建的subplot对象的NumPy数组:fig, axes = plt.subplots(2, 3)。可以轻松地对axes数组进行索引,就好像是一个二维数组一样,例如axes[0,1]。还可以通过sharex和sharey指定subplot应该具有相同的X轴或Y轴。在比较相同范围的数据时,这也是非常实用的,否则,matplotlib会自动缩放各图表的界限。

4.利用Figure的subplots_adjust(也是个顶级函数)方法可以轻而易举地修改间距:subplots_adjust(left=None, bottom=None, right=None, top=None, wspace=None, hspace=None),其中wspace和hspace用于控制宽度和高度的百分比,可以用作subplot之间的间距。
5.在plot函数中可以通过字符串来指定颜色和线型:ax.plot(x, y,'g--')
这种更为明确的方式也能得到同样的效果:ax.plot(x, y, linestyle='--', color='g')
常用的颜色可以使用颜色缩写,也可以指定颜色码(例如,#CECECE)
在IPython和Jupyter中使用plot?可以查看文档说明。
6.线图可以使用标记强调数据点。因为matplotlib可以创建连续线图,在点之间进行插值,因此有时可能不太容易看出真实数据点的位置。标记也可以放到格式字符串中,但标记类型和线型必须放在颜色后面:
from numpy.random import randn
plt.plot(randn(30).cumsum(), 'ko--')
plot(randn(30).cumsum(), color='k', linestyle='dashed', marker='o')
7.在线型图中,非实际数据点默认是按线性方式插值的。可以通过drawstyle选项修改
data = np.random.randn(30).cumsum()
plt.plot(data,'k--', label='Default')
plt.plot(data,'k-', drawstyle='steps-post', label='steps-post')
plt.legend(loc='best')
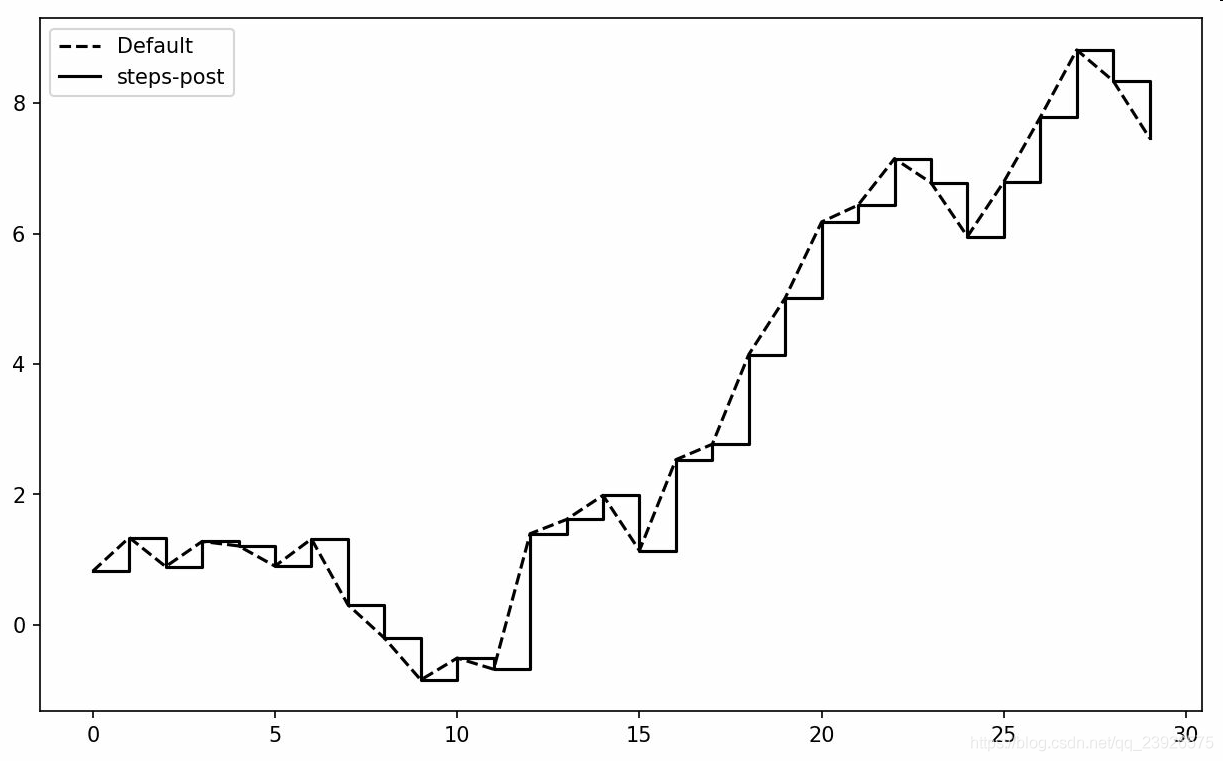
笔记:你必须调用plt.legend(或使用ax.legend,如果引用了轴的话)来创建图例,无论你绘图时是否传递label标签选项。
8.pyplot接口的设计目的就是交互式使用,含有诸如xlim、xticks和xticklabels之类的方法。它们分别控制图表的范围、刻度位置、刻度标签等。其使用方式有以下两种:
- 调用时不带参数,则返回当前的参数值(例如,
plt.xlim()返回当前的X轴绘图范围)。
- 调用时带参数,则设置参数值(例如,
plt.xlim([0,10])会将X轴的范围设置为0到10)。
所有这些方法都是对当前或最近创建的AxesSubplot起作用的。它们各自对应subplot对象上的两个方法,以xlim为例,就是ax.get_xlim和ax.set_xlim。
9. 设置标题、轴标签、刻度以及刻度标签
fig = plt.figure()
ax = fig.add_subplot(1, 1, 1)
ax.plot(np.random.randn(1000).cumsum()) # 创建随机漫步数据
ticks = ax.set_xticks([0,250,500,750,1000]) # 改变x轴刻度
labels = ax.set_xticklabels(['one','two','three','four','five'], rotation=30, fontsize='small') # 设置轴标签
ax.set_title('My first matplotlib plot') # 设置题目
ax.set_xlabel('Stages') # 设置轴名称
props ={
'title':'My first matplotlib plot',
'xlabel':'Stages'
}
ax.set(**props) # 设置题目和轴名称
10.图例(legend)是另一种用于标识图表元素的重要工具。最简单的是在添加subplot的时候传入label参数。要从图例中去除一个或多个元素,不传入label或传入label='nolegend‘即可。
fig = plt.figure(); ax = fig.add_subplot(1,1,1)
ax.plot(randn(1000).cumsum(),'k', label='one')
ax.plot(randn(1000).cumsum(),'k--', label='two')
ax.plot(randn(1000).cumsum(),'k.', label='three')
ax.legend(loc='best') # 必须调用legend方法才能显示图例
11.注解以及在Subplot上绘图
- 注解和文字可以通过text、arrow和annotate函数进行添加。text可以将文本绘制在图表的指定坐标(x,y),还可以加上一些自定义格式:
ax.text(x, y,'Hello world!', family='monospace', fontsize=10)
- 注解中可以既含有文本也含有箭头。
- 要在图表中添加一个图形,你需要创建一个块对象shp,然后通过
ax.add_patch(shp)将其添加到subplot中:
fig = plt.figure()
ax = fig.add_subplot(1,1,1)
rect = plt.Rectangle((0.2,0.75),0.4,0.15, color='k', alpha=0.3)
circ = plt.Circle((0.7,0.2),0.15, color='b', alpha=0.3)
pgon = plt.Polygon([[0.15,0.15],[0.35,0.4],[0.2,0.6]],
color='g', alpha=0.5)
ax.add_patch(rect)
ax.add_patch(circ)
ax.add_patch(pgon)
12.将图表保存到文件
plt.savefig可以将当前图表保存到文件。该方法相当于Figure对象的实例方法savefig。
参数:
dpi:控制“每英寸点数”分辨率;
bbox_inches:可以剪除当前图表周围的空白部分
plt.savefig('figpath.png', dpi=400, bbox_inches='tight')
savefig并非一定要写入磁盘,也可以写入任何文件型的对象,比如BytesIO:
from io importBytesIO
buffer =BytesIO()
plt.savefig(buffer)
plot_data = buffer.getvalue()

13.matplotlib自带一些配色方案,以及为生成出版质量的图片而设定的默认配置信息。几乎所有默认行为都能通过一组全局参数进行自定义,它们可以管理图像大小、subplot边距、配色方案、字体大小、网格类型等。一种Python编程方式配置系统的方法是使用rc方法。
- 要将全局的图像默认大小设置为10×10,可以执行:
plt.rc('figure', figsize=(10,10))
rc的第一个参数是希望自定义的对象,如'figure'、'axes'、'xtick'、'ytick'、'grid'、'legend'等。其后可以跟上一系列的关键字参数。一个简单的办法是将这些选项写成一个字典:
font_options ={
'family':'monospace',
'weight':'bold',
'size':'small'
}
plt.rc('font',**font_options)
三、使用pandas和seaborn绘图
在pandas中,我们有多列数据,还有行和列标签。pandas自身就有内置的方法,用于简化从DataFrame和Series绘制图形。另一个库seaborn简化了许多常见可视类型的创建。
提示:引入seaborn会修改matplotlib默认的颜色方案和绘图类型,以提高可读性和美观度。即使你不使用seaborn API,你可能也会引入seaborn,作为提高美观度和绘制常见matplotlib图形的简化方法。
1.Series和DataFrame都有一个用于生成各类图表的plot方法。默认情况下,它们所生成的是线型图:
s = pd.Series(np.random.randn(10).cumsum(), index=np.arange(0, 100, 10))
s.plot()
该Series对象的索引会被传给matplotlib,并用以绘制X轴。可以通过use_index=False禁用该功能。X轴的刻度和界限可以通过xticks和xlim选项进行调节,Y轴就用yticks和ylim。


2.pandas的大部分绘图方法都有一个可选的ax参数,它可以是一个matplotlib的subplot对象。这使你能够在网格布局中更为灵活地处理subplot的位置。DataFrame的plot方法会在一个subplot中为各列绘制一条线,并自动创建图例
df = pd.DataFrame(np.random.randn(10, 4).cumsum(0), columns=['A', 'B', 'C', 'D'], index=np.arange(0, 100, 10))
df.plot()
plot属性包含一批不同绘图类型的方法。例如,df.plot()等价于df.plot.line()

笔记:plot的其他关键字参数会被传给相应的matplotlib绘图函数,所以要更深入地自定义图表,就必须学习更多有关matplotlib API的知识。
3.plot.bar()和plot.barh()分别绘制水平和垂直的柱状图。这时,Series和DataFrame的索引将会被用作X(bar)或Y(barh)刻度
fig, axes = plt.subplots(2, 1)
data = pd.Series(np.random.rand(16), index=list('abcdefghijklmnop'))
data.plot.bar(ax=axes[0], color='k', alpha=0.7) # alpha设置透明度
data.plot.barh(ax=axes[1], color='k', alpha=0.7)
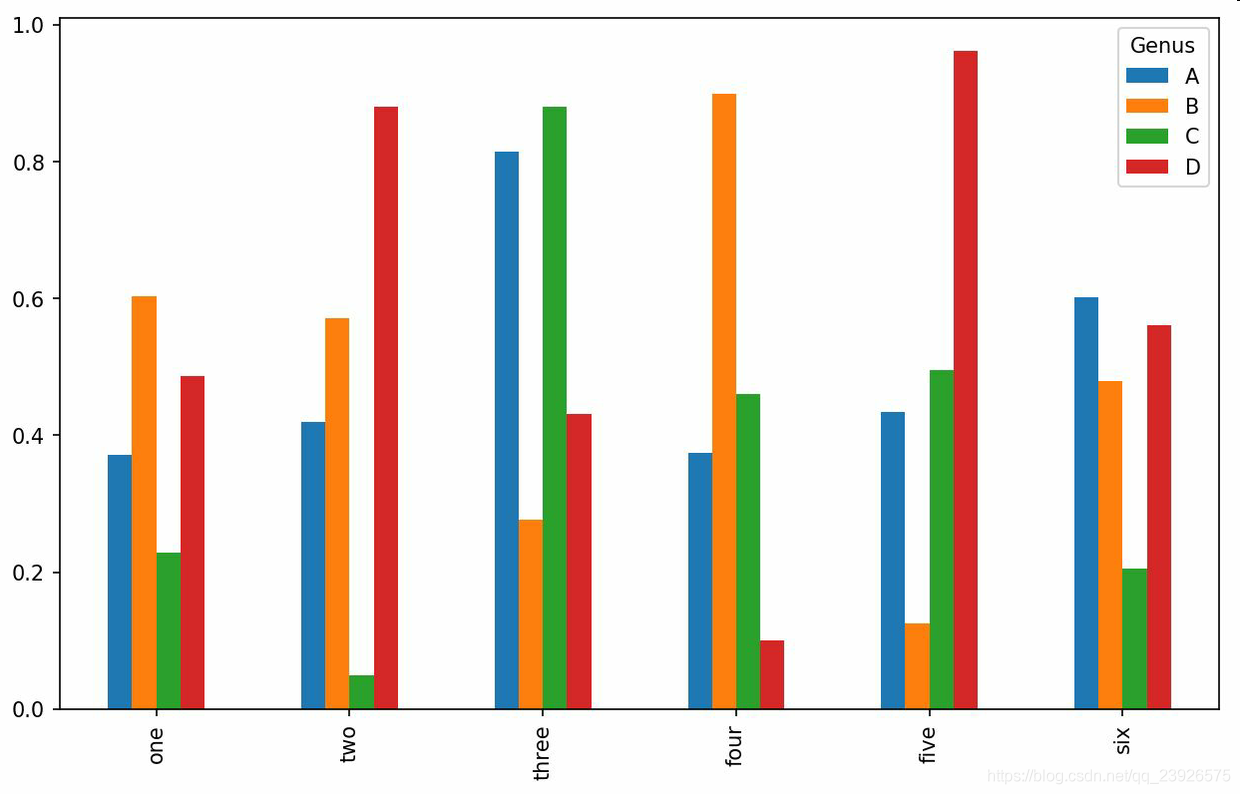
4.对于DataFrame,柱状图会将每一行的值分为一组,并排显示
df = pd.DataFrame(np.random.rand(6, 4), index=['one', 'two', 'three', 'four', 'five', 'six'], columns=pd.Index(['A', 'B', 'C', 'D'], name='Genus'))
df.plot.bar()
5.设置stacked=True即可为DataFrame生成堆积柱状图,这样每行的值就会被堆积在一起:df.plot.barh(stacked=True, alpha=0.5)
笔记:柱状图有一个非常不错的用法:利用value_counts图形化显示Series中各值的出现频率,比如s.value_counts().plot.bar()。
6.做一张堆积柱状图以展示每天各种聚会规模的数据点的百分比。
In [75]: tips = pd.read_csv('pydata-book-2nd-edition/')
In [76]: party_counts = pd.crosstab(tips['day'], tips['size'])
In [77]: party_counts
Out[77]:
size 1 2 3 4 5 6
day
Fri 1 16 1 1 0 0
Sat 2 53 18 13 1 0
Sun 0 39 15 18 3 1
Thur 1 48 4 5 1 3
# Not many 1- and 6-person parties
In [78]: party_counts = party_counts.loc[:, 2:5]
In [79]: party_pcts = party_counts.div(party_counts.sum(1), axis=0) # 进行规格化,使得各行的和为1
In [81]: party_pcts.plot.bar()
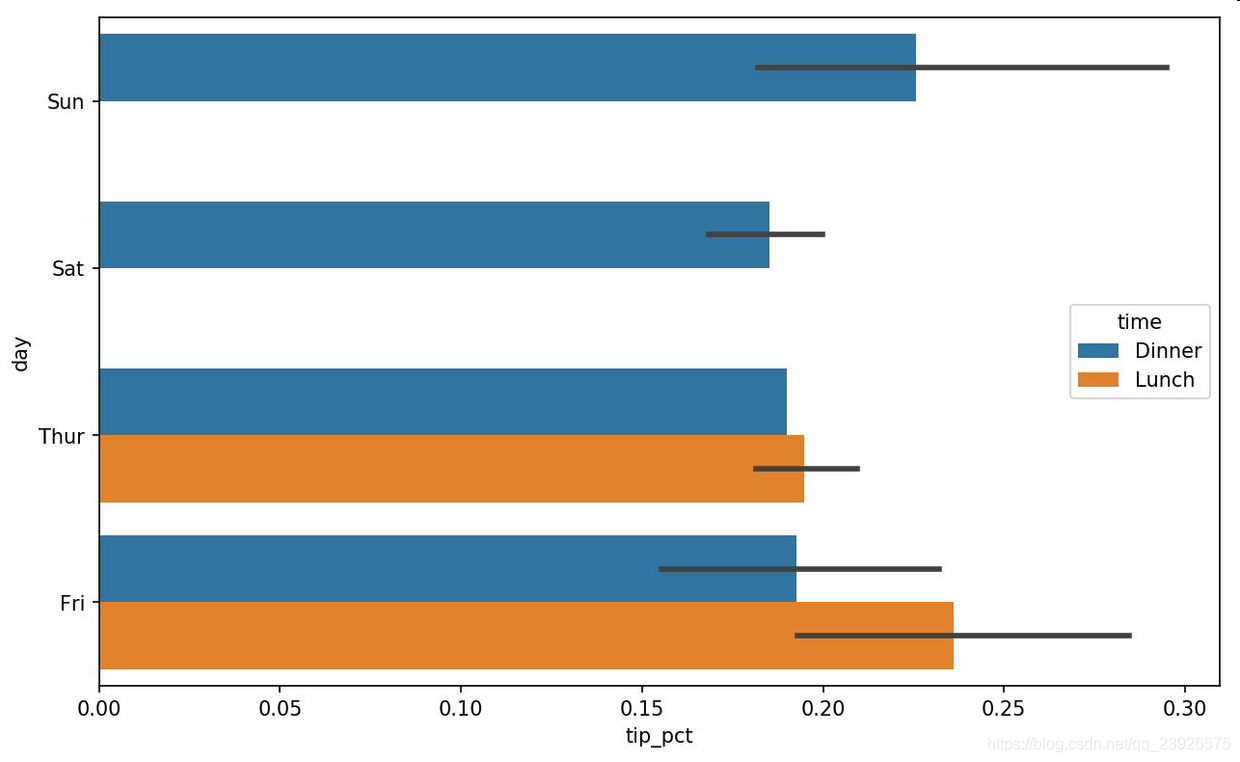
7.对于在绘制一个图形之前,需要进行合计的数据,使用seaborn可以减少工作量。seaborn的绘制函数使用data参数,它可能是pandas的DataFrame。其它的参数是关于列的名字。因为一天的每个值有多次观察,柱状图的值是tip_pct的平均值。绘制在柱状图上的黑线代表95%置信区间(可以通过可选参数配置)。
In [83]: import seaborn as sns
In [84]: %matplotlib inline # 在jupyter中输入,避免无法显示图的问题
In [85]: tips['tip_pct'] = tips['tip'] / (tips['total_bill'] - tips['tip'])
In [86]: tips.head()
Out[86]:
total_bill tip smoker day time size tip_pct
0 16.99 1.01 No Sun Dinner 2 0.063204
1 10.34 1.66 No Sun Dinner 3 0.191244
2 21.01 3.50 No Sun Dinner 3 0.199886
3 23.68 3.31 No Sun Dinner 2 0.162494
4 24.59 3.61 No Sun Dinner 4 0.172069
In [86]: sns.barplot(x='tip_pct', y='day', data=tips, orient='h')
In [87]: sns.barplot(x='tip_pct', y='day', hue='time', data=tips, orient='h') # 根据time列进行颜色区分
In [90]: sns.set(style="whitegrid") # 设置图形外观
8.直方图(histogram)是一种可以对值频率进行离散化显示的柱状图。数据点被拆分到离散的、间隔均匀的面元中,绘制的是各面元中数据点的数量。
tips['tip_pct'].plot.hist(bins=50) # bins表示柱的数量
9.密度图是通过计算“可能会产生观测数据的连续概率分布的估计”而产生的。一般的过程是将该分布近似为一组核(即诸如正态分布之类的较为简单的分布)。因此,密度图也被称作KDE(Kernel Density Estimate,核密度估计)图。使用plot.kde和标准混合正态分布估计即可生成一张密度图:tips['tip_pct'].plot.density()
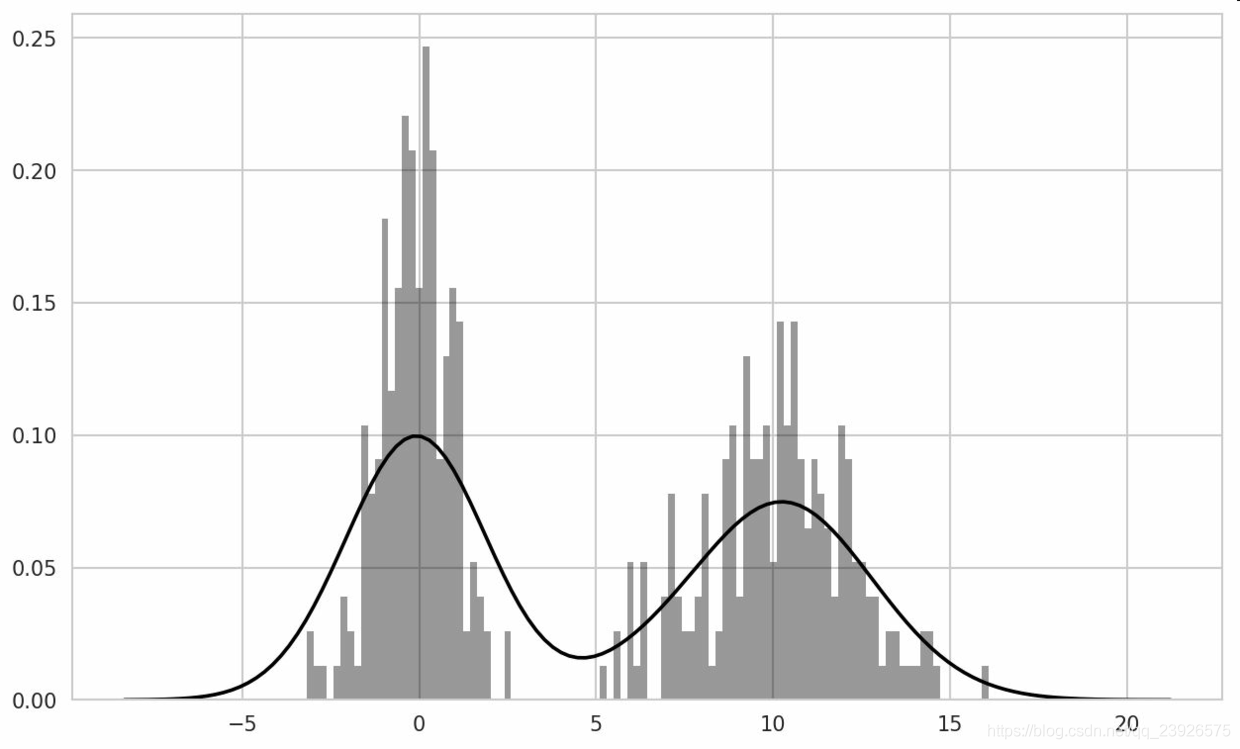
10.seaborn的distplot方法绘制直方图和密度图更加简单,还可以同时画出直方图和连续密度估计图。作为例子,考虑一个双峰分布,由两个不同的标准正态分布组成:
In [96]: comp1 = np.random.normal(0, 1, size=200)
In [97]: comp2 = np.random.normal(10, 2, size=200)
In [98]: values = pd.Series(np.concatenate([comp1, comp2]))
In [99]: sns.distplot(values, bins=100, color='k')
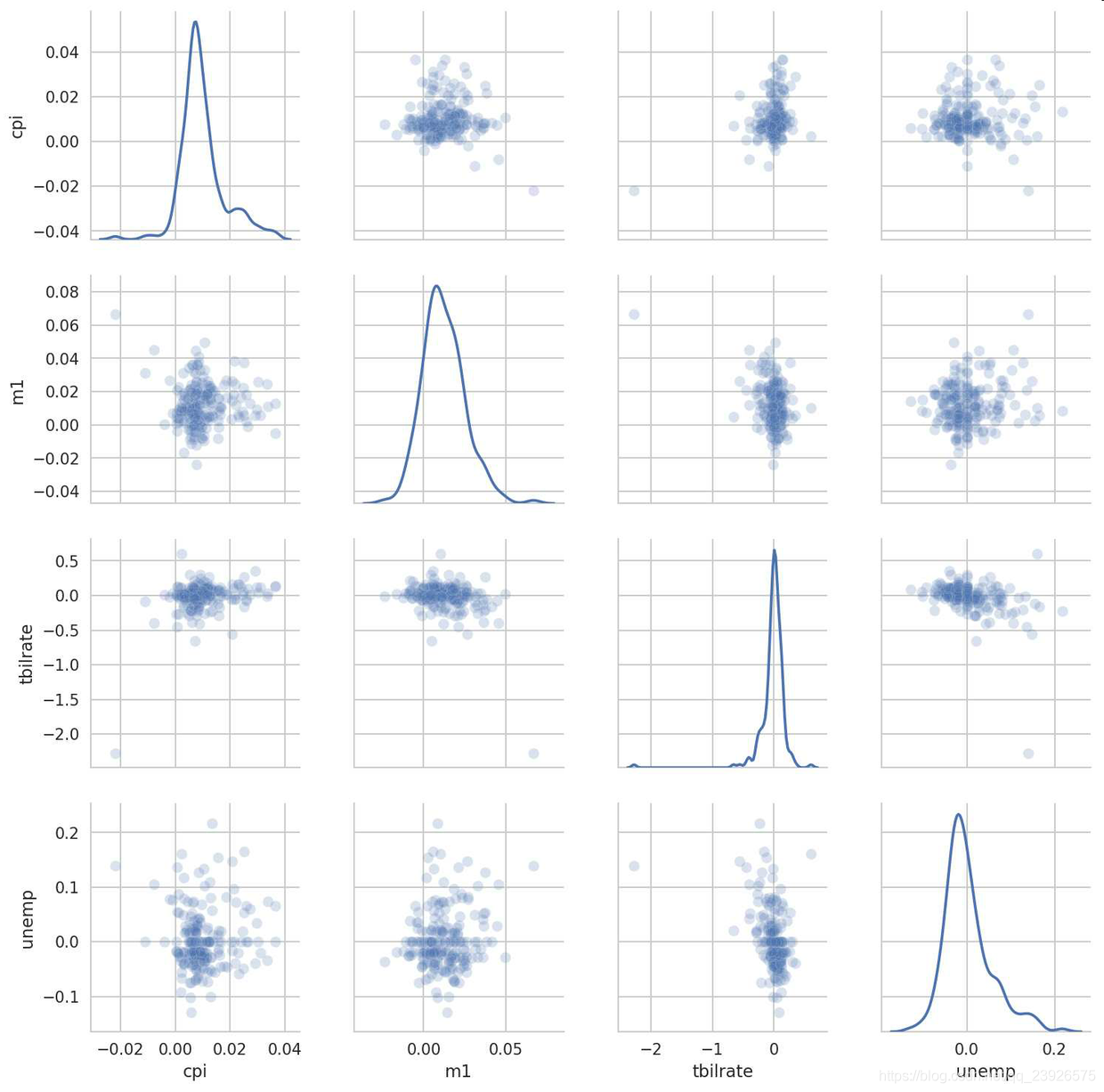
11.点图或散布图是观察两个一维数据序列之间的关系的有效手段。在下面这个例子中,我加载了来自statsmodels项目的macrodata数据集,选择了几个变量,然后计算对数差:
In [100]: macro = pd.read_csv('examples/macrodata.csv')
In [101]: data = macro[['cpi', 'm1', 'tbilrate', 'unemp']]
In [102]: trans_data = np.log(data).diff().dropna()
In [103]: trans_data[-5:]
Out[103]:
cpi m1 tbilrate unemp
198 -0.007904 0.045361 -0.396881 0.105361
199 -0.021979 0.066753 -2.277267 0.139762
200 0.002340 0.010286 0.606136 0.160343
201 0.008419 0.037461 -0.200671 0.127339
202 0.008894 0.012202 -0.405465 0.042560
In [104]: sns.regplot('m1', 'unemp', data=trans_data) # 做一个散布图,并加上一条线性回归的线
In [107]: sns.pairplot(trans_data, diag_kind='kde', plot_kws={'alpha': 0.2}) # 生成散布图矩阵,pairplot支持在对角线上放置每个变量的直方图或密度估计
plot_kws参数可以传递配置选项到非对角线元素上的图形使用。
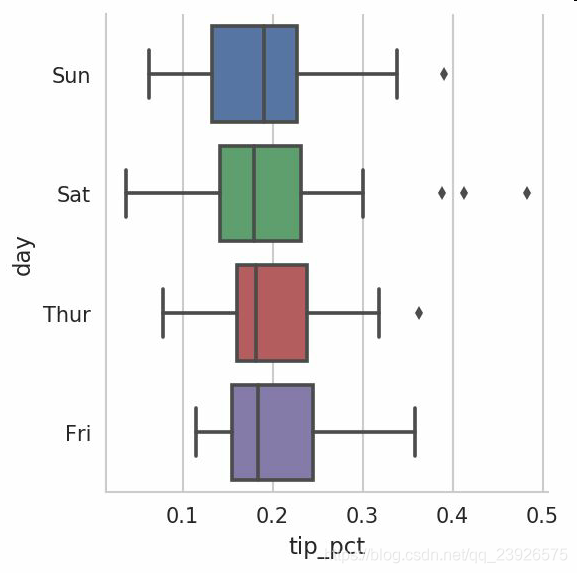
12.有多个分类变量的数据可视化的一种方法是使用小面网格。seaborn有一个有用的内置函数factorplot,可以简化制作多种分面图
sns.factorplot(x='day', y='tip_pct', hue='time', col='smoker', kind='bar', data=tips[tips.tip_pct 1])
sns.factorplot(x='day', y='tip_pct', row='time', col='smoker', kind='bar', data=tips[tips.tip_pct 1]) # 通过给每个时间值添加一行来扩展分面网格
factorplot支持其它的绘图类型,如盒图(它可以显示中位数,四分位数,和异常值):
sns.factorplot(x='tip_pct', y='day', kind='box', data=tips[tips.tip_pct 0.5])
到此这篇关于Python数据分析之绘图和可视化详解的文章就介绍到这了,更多相关Python绘图和可视化内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
您可能感兴趣的文章:- Python数据分析之pandas比较操作
- Python数据分析入门之数据读取与存储
- Python数据分析入门之教你怎么搭建环境
- python学习之panda数据分析核心支持库
- python数据分析之公交IC卡刷卡分析
- Python数据分析库pandas高级接口dt的使用详解
- 用Python 爬取猫眼电影数据分析《无名之辈》
- 高考要来啦!用Python爬取历年高考数据并分析


 咨 询 客 服
咨 询 客 服