一、三种数据文件的读取

二、csv、tsv、txt 文件读取
1)CSV文件读取:
语法格式:pandas.read_csv(文件路径)
CSV文件内容如下:
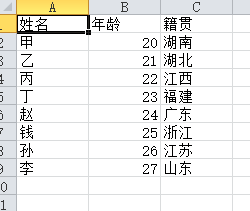
import pandas as pd
file_path = "e:\\pandas_study\\test.csv"
content = pd.read_csv(file_path)
content.head() # 默认返回前5行数据
content.head(3) # 返回前3行数据
content.shape # 返回一个元组(总行数,总列数),总行数不包括标题行
content.index # 返回索引,是一个可迭代的对象class 'pandas.core.indexes.range.RangeIndex'>
content.column # 返回所有的列名 Index(['姓名', '年龄', '籍贯'], dtype='object')
content.dtypes # 返回的是每列的数据类型
姓名 object
年龄 int64
籍贯 object
dtype: object
2)CSV文件读取:
语法格式:pandas.read_csv(文件路径)
CSV文件内容如下:
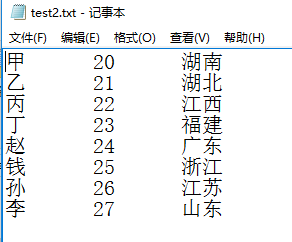
import pandas as pd
file_path = "e:\\pandas_study\\test2.txt"
content = pd.read_csv(file_path,sep='\t',header = None ,names= ['name','age','adress'])
#参数说明:
# header = None 表示没有标题行
# sep='\t' 表示去除分割符中的空格
# names= ['name','age','adress'] ,列名依次自定义为'name','age','adress'
content.head() # 默认返回前5行数据
content.head(3) # 返回前3行数据
content.shape # 返回一个元组(总行数,总列数),总行数不包括标题行
content.index # 返回索引,是一个可迭代的对象class 'pandas.core.indexes.range.RangeIndex'>
content.column # 返回所有的列名 Index(['姓名', '年龄', '籍贯'], dtype='object')
content.dtypes # 返回的是每列的数据类型
三、excel文件读取
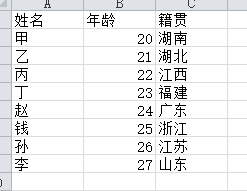
import pandas as pd
file_path = "e:\\pandas_study\\test3.xlsx"
content = pd.read_excel(file_path)
content.head() # 默认返回前5行数据
content.head(3) # 返回前3行数据
content.shape # 返回一个元组(总行数,总列数),总行数不包括标题行
content.index # 返回索引,是一个可迭代的对象class 'pandas.core.indexes.range.RangeIndex'>
content.column # 返回所有的列名 Index(['姓名', '年龄', '籍贯'], dtype='object')
content.dtypes # 返回的是每列的数据类型
姓名 object
年龄 int64
籍贯 object
dtype: object
四、数据库表格读取
语法: pandas.read_sql(sql语句,数据库连接对象)
数据对象的创建,可以根据pymysql,cx_oracle等模块连接mysql或者oracle。
到此这篇关于Python数据分析之pandas读取数据的文章就介绍到这了,更多相关pandas读取数据内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
您可能感兴趣的文章:- Python 循环读取数据内存不足的解决方案
- Python随机函数random随机获取数字、字符串、列表等使用详解
- python实现scrapy爬虫每天定时抓取数据的示例代码
- Python从文件中读取数据的方法步骤
- python从PDF中提取数据的示例
- python从Oracle读取数据生成图表
- python3:excel操作之读取数据并返回字典 + 写入的案例
- Python爬取数据并实现可视化代码解析
- Python定时从Mysql提取数据存入Redis的实现
- 使用Python脚本从文件读取数据代码实例
- python3实现从kafka获取数据,并解析为json格式,写入到mysql中
- Python实现一个自助取数查询工具


 咨 询 客 服
咨 询 客 服