前言,因为经常使用Excel处理数据,像表格内的筛选,表格间数据的复制,都是简单重复的操作,十分枯燥无聊,为了提高效率,主要是自己懒,特地研究openpyxl,发现能够简化个人劳动量,自己也是小白,特意写一篇文章,共同探讨。
安装openpyxl
这个要说简单也很简单,就是 pip install openpyxl
难也十分难,因为很多人安装不成功,各种报错,而且错误都是英文,还看不懂。大家可以搜索安装openpyxl,有教程指导,应该问题不大。
开始学习
首先导入库 openpyxl
import openpyxl as op
‘引入库,并把库的名字改为op,这样后面操作会少打很多字母,毕竟懒才是促进社会进步的阶梯'
打开指定工作表
wb = op.load_workbook('C:\\Users\\Administrator\\Desktop\\演示表.xlsx')
注意 \中第一个斜杠是转移符, .xlsx才是openpyxl可以处理的格式
显示工作表中有哪些子表
我操作的工作表中只有一个表,代码显示结果是

操作工作表
要实现操作工作表,首先要选中它
有多种方法可以选中这个表,这里就用最简单的一种,就是 工作表 + 子表名字
打印一个A1表格的内容
打印一列表格的内容,
for i in w1['A']:
print(i.value)
打印一列表格中部分内容
for i in w1['A2':'A5']:
for j in i:
print(j.value)
注意,这里多加了一个循环,在选中一列中部分表格时(A2到A5),第一次循环产生的格式和选中整列的格式会不一样,需要再一次循环,才能访问到单元格的值
批量改变某一列的内容
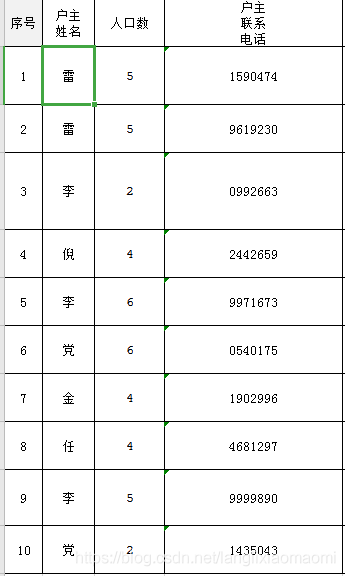
我们将给户主姓名这一列加入数字,一次为1,2,3,4…
import openpyxl as op
wb = op.load_workbook('C:\\Users\\Administrator\\Desktop\\演示表.xlsx')
print(wb.sheetnames)
w1 = wb['表1']
m = 0
for i in w1['B3':'B12']:
for j in i:
m = m + 1
s = j.value + str(m)
w1['B%d'%(m+2)] = s
wb.save('C:\\Users\\Administrator\\Desktop\\演示表.xlsx')
运行后表格如下
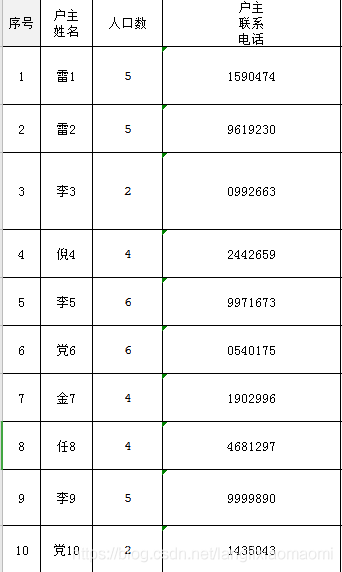
需要注意的是,操作时表格应处于关闭状态,操作完需要保存命令
根据某一项内容,改变对应项的内容
如果姓名含“雷”这个字,则要将其电话更改为0
import openpyxl as op
wb = op.load_workbook('C:\\Users\\Administrator\\Desktop\\演示表.xlsx')
print(wb.sheetnames)
w1 = wb['表1']
m = 0
for i in w1['B3':'B12']:
for j in i:
for n in j.value:
if n == '雷':
s = str(j)
s = s[-3:]
s = ''.join([x for x in s if x.isdigit()])
s = int(s)
w1['D%d'%s] = 0
print(s)
wb.save('C:\\Users\\Administrator\\Desktop\\演示表.xlsx')
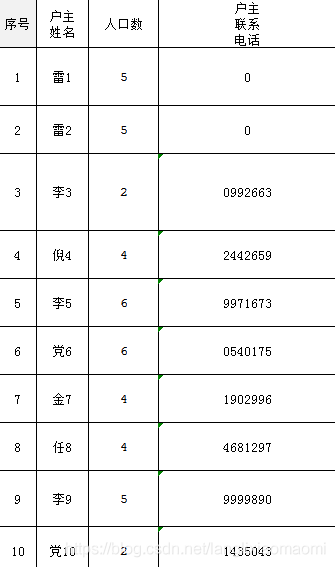
这段代码实现了我们的诉求,即如果姓名含“雷”这个字,则要将其电话更改为0,但是十分丑陋,因为我没找到一个简洁的命令或是方法,实现根据单元格参数筛选出对应的行数,希望有这个的大神指点迷津,这是这段代码的结果
总结
python 很强大,openpyxl也很强大,能够批量处理Excel数据,但本人python功底不足,代码实在不好看,希望有大神指点一二,共同提高python水平
以上就是Python使用openpyxl批量处理数据的详细内容,更多关于Python批量处理的资料请关注脚本之家其它相关文章!
您可能感兴趣的文章:- python 利用openpyxl读取Excel表格中指定的行或列教程
- python3.7 openpyxl 删除指定一列或者一行的代码
- python利用openpyxl拆分多个工作表的工作簿的方法
- python 的 openpyxl模块 读取 Excel文件的方法
- 浅谈Python_Openpyxl使用(最全总结)
- python openpyxl使用方法详解
- python批量处理txt文件的实例代码
- python遍历文件目录、批量处理同类文件
- 基于python批量处理dat文件及科学计算方法详解


 咨 询 客 服
咨 询 客 服