上一篇中我们对TrieTree服务有了一个整体的了解,不知道大家下载完之后有没有真正玩过这个TrieTree服务,如果你还没有玩过,没关系,本文将一步步教你配置和使用TrieTree服务。
TrieTree服务由几大组件组成,如下图

Dictionary组件是核心库,主要提供基本数据定义、配置信息定义,数据结构表示,同时也提供了POSType(参考Pangu的Part of Speech定义)。由于TrieTree是利用内存来加载数据的,所以这个组件的设计直接决定了内存的占用大小和数据查询性能。Dictionary.Providers组件主要负责提供各种自定义数据提供者(DataProvider),你可以把它理解为字典数据的加载器,例如自带的PanguDictProviders就是负责加载盘古自己的dict格式的字典。TrieTree服务的加载器是高度可配置的,你可以通过配置文件来选择你需要使用的加载器,如下所示:
复制代码 代码如下:
dictionaryService>
provider name="pangu_dict" uri="F:\Dropbox\research\NLP\TrieTreeService\DictionaryService.UnitTest\Data\panguDict.dct" type="BluePrint.Dictionary.Providers.PanguDictProvider, BluePrint.Dictionary.Providers" />
provider name="IKdict" uri="F:\Dropbox\research\NLP\TrieTreeService\DictionaryService.UnitTest\Data\IKdict.dic" type="BluePrint.Dictionary.Providers.TxtFileProvider, BluePrint.Dictionary.Providers"/>
/dictionaryService>
上面这个配置选择了2个加载器,分别是PanguDictProvider、TxtFileProvider(纯文本格式加载器,你可以理解为.csv字典加载器),这里的TxtFileProvider是用来加载IKAnalyzer中的IKdict.dic文件的。在服务启动后(调试模式)你会看到类似的提示:

TrieTree中由于使用了log4net的ColoredConsoleAppender,所以能够显示不同颜色的提示信息。你会看到日志中有pangu_dict和IKdict的加载时间,这里的名字是由app.config中的provider的name属性设置的。其实TrieTree也是支持加载基于MongoDB的字典的,只是由于牵扯到相对复杂的MongoDB的配置和一些概念,就不在本文中讲解了,我会考虑在之后的教程中提供。
DictionaryService组件是TrieTree服务的容器组件,主要包含了Windows服务的实现,还有Windows服务的安装器。这个组件是一个控制台程序,它为用户提供了两种运行模式——调试模式和Service模式。调试模式就是直接运行控制台,提供基于log4net的日志信息,方便调试和断点;而Service模式是直接运行为一个Windows服务,主要用于测试与生产环境。由于是控制台程序,切换模式是通过参数完成的,例如-i 表示安装windows服务,-u表示卸载windows服务, -c表示启动控制台模式。
以上便是TrieTree服务的三大核心组件,但我还打算介绍一个非常实用的附加组件DictionaryQuery。
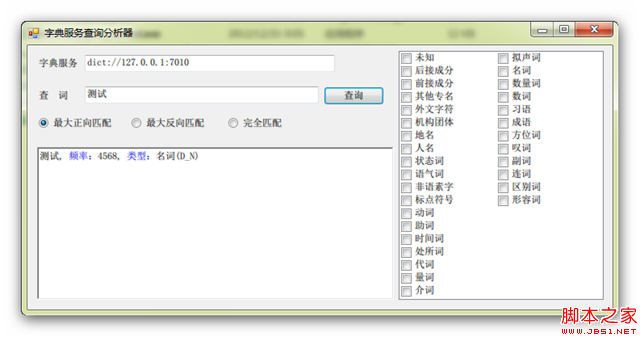
虽然名字也叫查询分析器,但其实和SQL的查询分析器不是一个级别的,你不用去比较,没啥意思。这东西主要是两个作用,第一,测试TrieTree服务的运行情况;第二,检查加载字典后字典中的词的状态。你也可以用右侧的POS过滤器进行筛选,多选表示或的关系,比如你选择了地名和人名,你搜索“上海”,结果是“上海, 频率:251, 类型:地名(A_NS)”,如果找不到的话会显示红色的“未找到合适词”,如下所示。
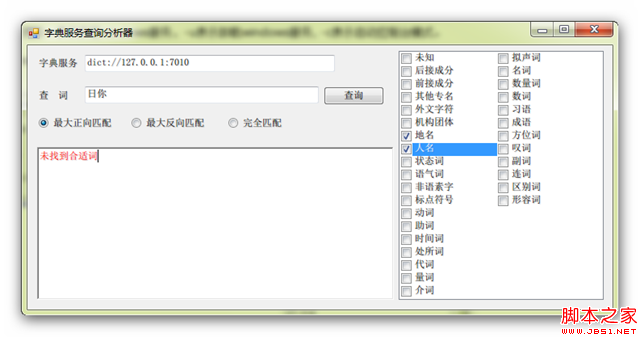
你还可以选择匹配的方式,即最大正向匹配、最大反向匹配和完全匹配,这个就不用我多解释了吧。对了,运行这玩意之前字典服务必须打开,且你要指向你配置的TrieTree服务的端口,默认是7010,图中配置的是dict://127.0.0.1:7010,注意字典服务的URI是以dict://开头的。
您可能感兴趣的文章:- Java中实现双数组Trie树实例
- Python Trie树实现字典排序
- C# TrieTree介绍及实现方法
- Trie树_字典树(字符串排序)简介及实现
- 详解字典树Trie结构及其Python代码实现
- Trie树(字典树)的介绍及Java实现


 咨 询 客 服
咨 询 客 服