近日,全球最顶级大数据会议Strata Data Conference在京召开。Strata大会被《福布斯》杂志誉为“大数据运动的里程碑”,吸引了大数据、人工智能领域最具影响力的数据科学家与架构师参会。第四范式联合创始人、首席研究科学家陈雨强受邀出席,并以“人工智能工业应用痛点及解决思路”为题,颁发主题演讲。
陈雨强是世界级深度学习、迁移学习专家,曾在NIPS、AAAI、ACL、SIGKDD等顶会颁发论文,并获APWeb2010 Best Paper Award,KDD Cup 2011名列第三,其学术工作被全球著名科技杂志MIT Technology Review报道。同时,陈雨强也是AI工业应用领军人物,在百度凤巢任职期间主持了世界首个商用的深度学习系统、在今日头条期间主持了全新的信息流保举与广告系统的设计实现,目前担任第四范式首席研究科学家,带领团队研究、转化最领先的机器学习技术,着力打造人工智能平台级产品”先知“。
以下内容按照陈雨强主题演讲编写,略有删减。
大家好,我是来自于第四范式的陈雨强,目前主要负责人工智能算法研发及应用的相关工作。非常高兴与大家分享人工智能在工业界应用的一些痛点、以及相应的解决思路。
工业大数据需要高VC维
人工智能是一个非常炙手可热的名词,且已经成功应用在语音、图像等诸多领域。但是,现在人工智能有没有达到可以简单落地的状态呢?工业界的人工智能需要什么技术呢?带着这些问题开始我们的思考。
首先,我们先探讨一下工业界人工智能需要一个什么样的系统?人工智能的兴起是由于数据量变大、性能提升以及并行计算技术发展共同产生的结果。所以,工业界的问题都是非常复杂的。因此,我们需要一个可扩展系统,不但在吞吐与计算能力上可扩展,还需要随着数据量与用户的增多在智能水平上可扩展。怎么实现一个可扩展系统呢?其实很重要的一点是工业界需要高VC维的模型,去解决智能可扩展性的问题。怎么获得一个高VC维的模型呢?大家都知道,机器学习=数据+特征+模型。如果数据在给定的情况下,我们就需要在特征和模型两个方面进行优化。
特征共分两种,一种叫宏不雅观特征,比喻说年龄、收入,,或是买过多少本书,看过多少部电影。别的一种是微不雅观特征,指的是相比细粒度的特征,你具体看过哪几本书,或者具体看过哪几部电影。每一部电影,每一本书,每一个人,都是差别的特征。书有几百万本,电影有几百万部,所以这样的特征量非常大。
模型可分为两类,一个是简单模型,好比说线性模型。还有一种是复杂模型,好比非线性模型。
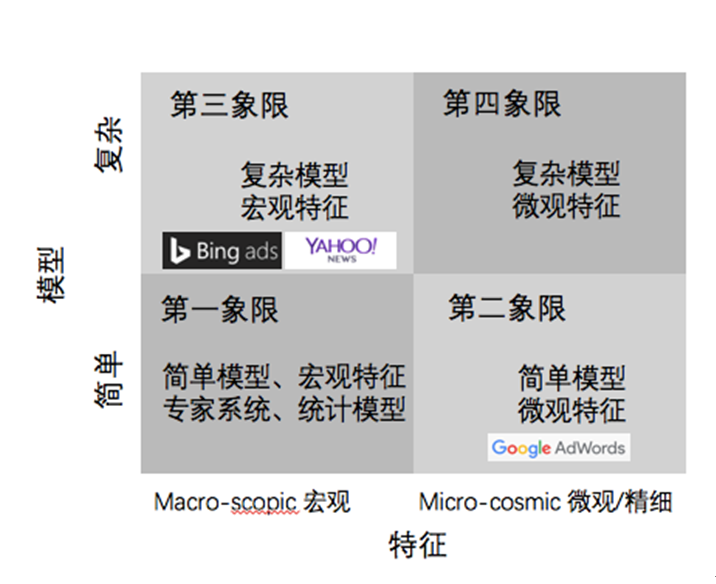
这样就把人工智能分为了四个象限。如上图,左下角是第一象限,使用宏不雅观特征简单模型解决问题。这种模型在工业界应用非常少,因为它特征数少,模型又简单,VC维就是低的,不能解决非常复杂的问题。右下角的第二象限是简单模型加上微不雅观特征,最有名的就是大家熟知的谷歌Adwords,用线性模型加上千亿特征做出了世界顶尖的广告点击率预估系统。左上角的第三象限是复杂模型加宏不雅观特征,也有诸多知名公司做出了非常好的效果,例如Bing广告和Yahoo,经典的COEC+复杂模型在这个象限内是一个惯用手段。最后是第四象限,利用复杂模型加上微不雅观特征,由于模型空间太大,如何计算以及解决过拟合都是研究的热点。
刚才说沿着模型和特征两条路走,那如何沿着模型做更高维度的机器学习呢?研究模型主要是在学术界,大部分的工作是来自于ICML、NIPS、ICLR这样的会议,非线性有三把宝剑别离是Kernel、Boosting、Neural Network。Kernel在十年前非常火,给当时风靡世界的算法SVM提供了非线性能力。Boosting中应用最广泛的当属GBDT,很多问题都能被很好地解决。Neural Network在很多领域也有非常成功的应用。工业界优化模型的方法总结起来有以下几点。首先,基于过去的数据进行思考得到一个假设,然后将假设的数学建模抽象成参数加入,用数据去拟合新加入的参数,最后用另一部分数据验证模型的准确性。这里举一个开普勒沿模型这条路发现开普勒三定律的例子。在中世纪的时候,第谷把本身的头绑在望远镜上坚持不雅观察了30年夜空,将各个行星的运动轨迹都记录下来。基于这些数据,开普勒不停的进行假设,最后假设行星的运动轨道是椭圆的,用椭圆的方程去拟合他的数据,发现拟合的非常好,便得到了一个新的模型:开普勒第必然律。这就是一个典型的沿着模型走的思路,通过不雅观测数据,科学家获得一个假设,这个假设就是一个模型,然后用数据拟合这个模型的参数,最终在新的数据上验证模型是否正确,这是沿着模型走的一条路。


 咨 询 客 服
咨 询 客 服