1中科信利连续语音识别引擎基本原理
1.1 概述
中科信利连续语音识别引擎,针对连续音频流(即来自说话人直接录入的语音,或者电话或其他音视频领域的音频信号)进行识别,将音频信息自动转化成文字。覆盖汉语中绝大多数词语,适用于说普通话的任何人群。输出的结果都是汉字,兼容数字。
在输入的声音中,检测出可靠的语音,排除静音、背景噪声、音乐等,判断男女,实时送入语音识别解码器进行识别。
识别引擎把音视频中提取出的语音分成25毫秒一帧,提取有用特征,然后识别出一些类似拼音的结果(声学模型),再根据汉语字词句之间的搭配概率(语言模型),综合考虑。当然,考虑的越多(beam路径越大),识别准确率相对提高,同时消耗的时间就增长了;所以我们有优化策略,及时排除不可能的结果,避免系统过慢。用户可以通过调节这些参数来平衡识别质量和速度,以满足实际的需要。
最后返回的识别结果,软件以汉语中基本词语为单位给出了多种可能(1到十几种)以及可能性大小供用户参考选择。
需要说明的是,对识别正确率以及识别速度来说,输入语音(普通话)的质量(采音过程)是很重要的。采音时应尽可能的排除噪声和音乐、增大语音,识别效果就会好得多,因此建议用户在采音的时候选用质量较好的麦克风。
另外,系统在检测是否有语音信号时可能会带来一定的时间滞后,用户在实时录入时在每句话结束后,需要略有停顿,这样可以提高系统语音检测的速度和精度。语音检测的越好,识别引擎的识别效果会越好。
1.2 引擎架构和基本原理
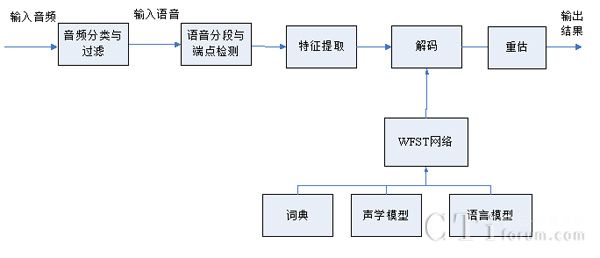
下图给出了连续语音识别引擎的基本架构图:
图1.语音识别引擎架构图
系统流程
如图1所示,首先对输入的音频数据进行自动分类,过滤掉彩铃、振铃、传真、音乐以及其他噪音,保留有效用户语音数据,然后进行自动分段和端点检测,获取逐句的有效语音数据,然后将其送入特征提取和处理模块,接着对于提取的声学特征进行解码,解码过程利用发音字典、声学模型、语言模型等信息构建WFST搜索空间,在搜索空间内寻找匹配概率最大的最优路径,得到识别结果。后续可采用重估模块,增加其他知识源,进一步提升语音识别系统性能。
核心技术特点
采用两遍的维纳滤波技术消除背景噪声;采用垃圾语音混合高斯建模的方法去除垃圾语音(笑声、咳嗽声等非自然人语音);采用谐波检测技术检测语音起始点。
从人的听觉感知及发音机理等现有基础研究成果出发,分析提取具备抗噪性、鉴别性、互补性的特征参数。
采用PLP/CMN/HLDA/VTLN/高斯化等稳健性特征提取和处理技术,减少信道影响,进一步提高特征的区分性。
采用基于深度神经网络DNN的声学建模技术,采用业界领先的鉴别性模型训练算法,大幅度提升语音识别系统性能。在训练数据、特征提取等方面都充分考虑了自然环境噪声的干扰,并且采用多条件的训练策略,能够显着提高对于噪声的稳健性。采用大量实网语音的训练数据库,适应用户自然口语发音特点和地方口音特点。
充分利用网上业务语料,采用高阶文法的统计语言模型技术。
积累了大量的分类文本语料(1T左右),使得语言模型能够很好地覆盖各个领域。同时对语言模型存取速度进行了大幅度优化以满足实用需求。
采用基于WFST的Cross-word静态搜索空间构建方法,有效地单遍集成各种知识源,将声学模型、声学上下文、发音词典、语言模型等静态编译成状态网络,通过充分的前向后向归并算法优化网络。在识别率相当的情况下,比WFST开源工具包解码速度快5倍以上。
采用模型自学习技术,基于实网语音数据进行声学模型和语言模型的自适应,适应于多种地区的用户口音。
1.3 引擎应用模式
中科信利连续语音识别引擎API提供两种应用模式:
一种是在线实时录音,检测语音并进行识别。这种方法适合用于需要实时获得讲话内容的场合。目前可以在各类会议讨论中进行开发使用。
另一种是离线读入录音文件进行识别,可以充分的利用聚类、实时自适应等技术,把语音的内容充分分析,进一步提高识别准确度。这种模式适用于希望取得精确文本内容,而对时间要求不高的应用。
2 中科信利连续语音识别引擎的功能和性能
2.1 连续语音识别引擎的特点和性能
核心引擎采用中科信利具有自主知识产权的国际领先的大词汇量连续语音识别技术。
能够自动将连续语音的内容转成文字,支持在线语音流识别或离线语音数据识别。
可以实时对语音分段,判别类型,可自动分辨和过滤背景音乐、噪声等非表义音频段,对语音分男女进行识别。
识别结果除了文字外,还可同时给出时间索引信息(精确到每个字),有利于进行多媒体信息检索;多候选信息为人工校对提供方便。
能够达到较高的识别准确率
引擎准确率性能:
- 对于朗读类型语音(如:手机语音搜索或输入类语音、广播电视新闻等),识别准确率在90%以上,经过模型优化训练以后能达到95%。
- 对于自然对话类型语音(如:电视访谈语音或电话自然交谈语音),识别准确率为85%左右,经过模型优化训练以后能够达到90%。
引擎速度性能:
- 在普通台式机上可以达到1倍实时。
- 并发性:针对普通服务器(IntelXeonE5**双cpu,每cpu六核),可支持24路语音数据流的实时识别(或相当于机器1小时能够处理24小时的语音数据)。
支持说话人口音自适应(声学自适应)和领域语料自适应(语言自适应)
核心算法支持海量并行处理,多线程
核心算法与语种无关,即系统语种可移植,支持汉语普通话、粤语和英语等语言的识别
引擎提供标准C接口,可供C/C++及各种语言的开发者直接调用。
能够提供方便灵活的开发接口,多项参数可调,使用户可以方便灵活地进行应用开发。
2.2 连续语音识别引擎资源配置
(一) 硬件环境
PC/工作站/服务器:
- CPU:性能相当于Intel酷睿2.2GHZ以上或兼容,双核
- 内存:8GB以上(建议为16GB),200GB以上硬盘
(二) 软件环境
PC/工作站/服务器:WINXP/Win7/WinServer2008等操作系统,或Linux操作系统
2.3 连续语音识别引擎的应用
在智能客服语音导航、客服录音质量检测、录音文本自动语音录入、Internet信息检索、多媒体信息检索、广电监控系统等领域具有相当广泛的用途。


 咨 询 客 服
咨 询 客 服