背景补充:日本网民一直都有在电视节目播出的同时,在网络平台上吐槽或跟随片中角色喊出台词的习惯,被称作“实况”行为。宫崎骏监督的名作动画《天空之城》于2013年8月2日晚在NTV电视台迎来14次电视重播。当剧情发展到男女主角巴鲁和希达共同念出毁灭之咒“Blase”时,众多网友也在推特上同时发出这条推特,创造了每秒推特发送数量的新纪录。
根据推特日本官方帐号,当地时间8月2日晚11时21分50秒,因为“Blase祭”的影响,推特发送峰值达到了143,199次/秒。这一数字高于此前推特发送峰值的最高纪录,2013年日本时区新年时的33,388次/秒。更高于拉登之死(5106次/秒)、东日本大地震(5530次/秒)、美国流行天后碧昂斯宣布怀孕(8868次/秒)。
下图是峰值发生的邻近时间段的访问频率图,Twitter通常每天的推文数是 5 亿条,平均下来每秒大概产生5700条。这个峰值大概是稳定状态下访问量的25倍!
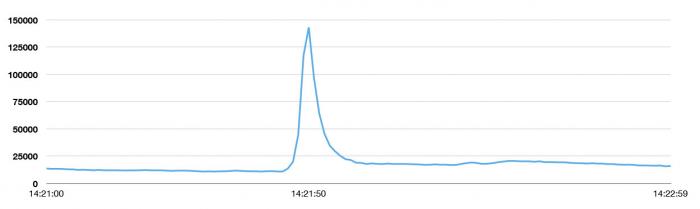
在这个峰值期间,用户并没有感觉到暂时性的功能异常。无论世界上发生了什么,Twitter始终在你身边,这是Twitter的目标之一。
“新的Tweets峰值诞生:143,199次Tweets每秒。通常情况:5亿次每天;平均值5700Tweets每秒”
这个目标在3年前还是遥不可及的,2010年世界杯直接把Twitter变成了全球即时沟通的中心。每一次射门、罚球、黄牌或者红牌,用户都在发推文,这反复地消耗着系统带宽,从而使其在短时间内无法访问。工程师们在这期间彻夜工作,拼命想找到并实现一种方法可以把整个系统的负载提升一个量级。不幸的是,这些性能的提升很快被Twitter用户的快速增长所淹没,工程师们已经开始感到黔驴技穷了。
经历了那次惨痛的经历,Twitter决定要回首反思。那时Twitter决定了要重新设计Twitter,让它能搞定持续增长的访问负载,并保证平稳运行。从那开始Twitter做了很大努力,来保证面临世界各地发生的热点事件时,Twitter仍能提供稳定的服务。Twitter现在已经能扛住诸如播放“天空之城”,举办超级碗,庆祝新年夜等重大事件带来的访问压力。重新设计/架构,不但使系统在突发访问峰值期间的稳定性得到了保证,还提供了一个可伸缩的平台,从而使新特性更容易构建,其中包括不同设备间同步消息,使Tweets包含更丰富内容的Twitter卡,包含用户和故事的富搜索体验等等特性。其他更多的特性也即将呈现。
开始重新架构
2010年世界杯尘埃落定,Twitter总览了整个项目,并有如下的发现:
Twitter正运行着世界上最大的Ruby on Rails集群,Twitter非常快速的推进系统的演进–在那时,大概200个工程师为此工作,无论是新用户数还是绝对负载都在爆炸式的增长,这个系统没有倒下。它还是一个统一的整体,Twitter的所有工作都在其上运行,从管理纯粹的数据库,memcache连接,站点的渲染,暴露共有API这些都集中在一个代码库上。这不但增加了程序员搞清整个系统的难度,也使管理和同步各个项目组变得更加困难。
Twitter的存储系统已经达到阈值–Twitter依赖的MySQL存储系统是临时切分的,它只有一个单主节点。这个系统在消化/处理快速涌现的tweets时会陷入麻烦,Twitter在运营时不得不不断的增加新的数据库。Twitter的所有数据库都处于读写的热点中。
Twitter面临问题时,只是一味的靠扔进更多的机器来扛住,并没有用工程的方式来解决它–根据机器的配置,前端Ruby机器的每秒事务处理数远没有达到Twitter预定的能力。从以往的经验,Twitter知道它应该能处理更多的事务。
最后,从软件的角度看,Twitter发现自己被推到了一个”优化的角落“,在那Twitter以代码的可读性和可扩展性为代价来换取性能和效率的提升。
结论是Twitter应该开启一个新工程来重新审视Twitter的系统。Twitter设立了三个目标来激励自己。
Twitter一直都需要一个高屋建瓴的建构来确保性能/效率/可靠性,Twitter想要保证在正常情况下有较好的平均系统响应时间,同时也要考虑到异常峰值的情况,这样才能保证在任何时间都能提供一致的服务和用户体验。Twitter要把机器的需求量降低10倍,还要提高容错性,把失败进行隔离以避免更大范围的服务中断–这在机器数量快速增长的背景下尤为重要,因为机器数的快速增长也意味着单体机器故障的可能性在增加。系统中出现失败是不可避免的,Twitter要做的是使整个系统处于可控的状态。
Twitter要划清相关逻辑间的界限,整个公司工作在一个的代码库上的方式把Twitter搞的很惨,所以Twitter开始尝试以基于服务的松耦合的模式进行划分模块。Twitter曾经的目标是鼓励封装和模块化的最佳实践,但这次Twitter把这个观点深入到了系统层次,而不是类/模块或者包层。
最重要的是要更快的启动新特性。以小并自主放权的团队模式展开工作,他们可以内部决策并发布改变给用户,这是独立于其他团队的。
针对上面的要求,Twitter构建了原型来证明重新架构的思路。Twitter并没有尝试所有的方面,并且即使Twitter尝试的方面在最后也可能并像计划中那样管用。但是,Twitter已经能够设定一些准则/工具/架构,这些使Twitter到达了一个憧憬中的更靠谱的状态。
The JVM VS the Ruby VM
首先,Twitter在三个维度上评估了前端服务节点:CPU,内存和网络。基于Ruby的机器在CPU和内存方面遭遇瓶颈–但是Twitter并未处理预计中那么多的负载,并且网络带宽也没有接近饱和。Twitter的Rails服务器在那时还不得不设计成单线程并且一次处理一个请求。每一个Rails主机跑在一定数量的Unicorn处理器上来提供主机层的并发,但此处的复制被转变成了资源的浪费(这里译者没太理清,请高手矫正,我的理解是Rails服务在一台机器上只能单线程跑,这浪费了机器上多核的资源)。归结到最后,Rails服务器就只能提供200~300次请求每秒的服务。
Twitter的负载总是增长的很快,做个数学计算就会发现搞定不断增长的需求将需要大量的机器。
在那时,Twitter有着部署大规模JVM服务的经验,Twitter的搜索引擎是用Java写的,Twitter的流式API的基础架构还有Twitter的社交图谱系统Flock都是用Scala实现的。Twitter着迷于JVM提供的性能。在Ruby虚拟机上达到Twitter要求的性能/可靠性/效率的目标不是很容易,所以Twitter着手开始写运行在JVM上的代码。Twitter评估了这带来的好处,在同样的硬件上,重写Twitter的代码能给Twitter带来10倍的性能改进–现今,Twitter单台服务器达到了每秒10000-20000次请求的处理能力。
Twitter对JVM存在相当程度的信任,这是因为很多人都来自那些运营/调配着大规模JVM集群的公司。Twitter有信心使Twitter在JVM的世界实现巨变。现在Twitter不得不解耦Twitter的架构从而找出这些不同的服务如何协作/通讯。
编程模型
在Twitter的Ruby系统中,并行是在进程的层面上管理的:一个单个请求被放进某一进程的队列中等待处理。这个进程在请求的处理期间将完全被占用。这增加了复杂性,这样做实际上使Twitter变成一个单个服务依赖于其他服务的回复的架构。基于Ruby的进程是单线程的,Twitter的响应时间对后台系统的响应非常敏感,二者紧密关联。Ruby提供了一些并发的选项,但是那并没有一个标准的方法去协调所有的选项。JVM则在概念和实现中都灌输了并发的支持,这使Twitter可以真正的构建一个并发的编程平台。
针对并发提供单个/统一的方式已经被证明是有必要的,这个需求在处理网络请求是尤为突出。Twitter都知道,实现并发的代码(包括并发的网络处理代码)是个艰巨的任务,它可以有多种实现方式。事实上,Twitter已经开始碰到这些问题了。当Twitter开始把系统解耦成服务时,每一个团队都或多或少的采用了不尽相同的方式。例如,客户端到服务的失效并没有很好的交互:这是由于Twitter没有一致的后台抗压机制使服务器返回某值给客户端,这导致了Twitter经历了野牛群狂奔式的疯狂请求,客户端猛戳延迟的服务。这些失效的区域警醒Twitter–拥有一个统一完备的客户/服务器间的库来包含连接池/失效策略/负载均衡是非常重要的。为了把这个理念深入人心,Twitter引入了”Futures and Finagle”协议。
现在,Twitter不仅有了一致的做事手段,Twitter还把系统需要的所有东西都包含进核心的库里,这样Twitter开新项目时就会进展飞速。同时,Twitter现在不需要过多的担心每个系统是如何运行,从而可以把更多的经历放到应用和服务的接口上。
独立的系统
Twitter实施了架构上的重大改变,把集成化的Ruby应用变成一个基于服务的架构。Twitter集中力量创建了Tweet时间线和针对用户的服务–这是Twitter的核心所在。这个改变带给组织更加清晰的边界和团队级别的责任制与独立性。在Twitter古老的整体/集成化的世界,Twitter要么需要一个了解整个工程的大牛,要么是对某一个模块或类清楚的代码所有者。
悲剧的是,代码膨胀的太快了,找到了解所有模块的大牛越来越难,然而实践中,仅仅依靠几个对某一模块/类清楚的代码作者又不能搞定问题。Twitter的代码库变得越来越难以维护,各个团队常常要像考古一样把老代码翻出来研究才能搞清楚某一功能。不然,Twitter就组织类似“捕鲸征程”的活动,耗费大量的人力来搞出大规模服务失效的原因。往往一天结束,Twitter花费了大量的时间在这上面,而没有精力来开发/发布新特性,这让Twitter感觉很糟。
Twitter的理念曾经并一直都是–一个基于服务的架构可以让Twitter并行的开发系统–Twitter就网络RPC接口达成一致,然后各自独立的开发系统的内部实现–但,这也意味着系统的内部逻辑是自耦合的。如果Twitter需要针对Tweets进行改变,Twitter可以在某一个服务例如Tweets服务进行更改,然后这个更改会在整个架构中得到体现。然而在实践中,Twitter发现不是所有的组都在以同样的方式规划变更:例如一个在Tweet服务的变更要使Tweet的展现改变,那么它可能需要其他的服务先进行更新以适应这个变化。权衡利弊,这种理念还是为Twitter赢得了更多的时间。

这个系统架构也反映了Twitter一直想要的方式,并且使Twitter的工程组织有效的运转。工程团队建立了高度自耦合的小组并能够独立/快速的展开工作。这意味着Twitter倾向于让项目组启动运行自己的服务并调用后台系统来完成任务。这实际也暗含了大量运营的工作。
存储
即使Twitter把Twitter板结成一坨的系统拆开成服务,存储仍然是一个巨大的瓶颈。Twitter在那时还把tweets存储在一个单主的MySQL数据库中。Twitter采用了临时数据存储的策略,数据库中的每一行是一个tweet,Twitter把tweet有序的存储在数据库中,当一个库满了Twitter就新开一个库然后重配软件开始往新库中添加数据。这个策略为Twitter节省了一定的时间,但是面对突发的高访问量,Twitter仍然一筹莫展,因为大量的数据需要被串行化到一个单个的主数据库中以至于Twitter几台局部的数据库会发生高强度的读请求。Twitter得为Tweet存储设计一个不同的分区策略。
Twitter引入了Gizzard并把它应用到了tweets,它可以创建分片并容错的分布式数据库。Twitter创造了T-Bird(没懂啥意思,意思是Twitter的速度快起来了?)。这样,Gizzard充当了MySQL集群的前端,每当一个tweet抵达系统,Gizzard对其进行哈希计算,然后选择一个适当的数据库进行存储。当然,这意味着Twitter失去了依靠MySQL产生唯一ID的功能。Snowflake很好的解决了上述问题。Snowflake使Twitter能够创建一个几乎可以保证全局唯一的ID。Twitter依靠它产生新的tweet ID,作为代价,Twitter将没有“把某数加1产生新ID”的功能。一旦Twitter得到一个IDTwitter靠Gizzard来存储它。假设Twitter的哈希算法足够好,从而Twitter的tweets是接近于均匀的分布于各个储存的,Twitter就能够实现用同样数量的数据库承载更多的数据。Twitter的读请求同样也接近平均的分布于整个分布式集群中,这也增加了Twitter的吞度量。
可观察性和可统计性
把那坨脆弱的板结到一起的系统变成一个更健壮的/良好封装的/但也蛮复杂的/基于服务的应用。Twitter不得不搞出一些工具来使管理这头野兽变得可能。基于大家都在快速的构建各种服务,Twitter需要一种可靠并简单的方式来得到这些服务的运行情况的数据。数据为王是默认准则,Twitter需要是使获取上述的数据变得非常容易。
当Twitter将要在一个快速增长的巨大系统上启动越来越多的服务,Twitter必须使这种工作变得轻松。运行时系统组开发为大家开发了两个工具:Viz和Zipkin。二者都暴露并集成到了Finagle,所以所有基于Finagle的服务都可以自动的获取到它们。
stats.timeFuture("request_latency_ms") {
// dispatch to do work
}
上面的代码就是一个服务生成统计报告给Via所需做的唯一事情。从那里,任何Viz用户都可以写一个查询来生成针对一些有趣的数据的时间/图表,例如第50%和第99%的request_latency_ms。
运行时配置和测试
最后,当Twitter把所有的好东西放一起时,两个看似无关的问题摆在面前:第一,整个系统的启动需要协调多个系列的不同的服务,Twitter没有一个地方可以把Twitter这个量级的应用所需要的服务弄到一起。Twitter已经不能依靠通过部署来把新特性展现给客户,应用中的各个服务需要协调。第二,Twitter已经变得太庞大,在一个完全封闭的环境下测试整个系统变得越来越困难。相对而言,Twitter测试自己孤立的系统是没有问题的–所以Twitter需要一个办法来测试大规模的迭代。Twitter接纳了运行时配置。
Twitter通过一个称作Decider的系统整合所有的服务。当有一个变更要上线,它允许Twitter只需简单开启一个开关就可以让架构上的多个子系统都和这个改变进行几乎即时的交互。这意味着软件和多个系统可以在团队认为成熟的情况下产品化,但其中的某一个特性不需要已经被激活。Decider还允许Twitter进行二进制或百分比的切换,例如让一个特性只针对x%的用户开放。Twitter还可以先把完全未激活并完全安全的特性部署上线,然后梯度的开启/关闭,知道Twitter有足够的自信保证特性可以正确的运行并且系统可以负担这个新的负荷。所有这些努力都可以减轻Twitter进行团队之间沟通协调的活动,取而代之Twitter可以在系统运行时做Twitter想要的定制/配置。


 咨 询 客 服
咨 询 客 服