前言,这几天查看了很多关于SQL SERVER收缩数据文件方面的文章,准备写一篇关于收缩日志方面的文章,但是突然有种冲动将看过经典的文章翻译出来,下面这篇文章是翻译的是Paul Randal – “Why You Should Not Shrink Your Data Files”。有些比较难以翻译、清晰的地方,我会贴上原文。好了,不啰嗦了,直接看下面的翻译吧。
我最大的一个热点问题是关于收缩数据文件,虽然在微软的时候,我自己写了相关收缩数据文件代码,我再也没有机会去重写它,让它操作起来更方便。我真的不喜欢收缩。
现在,不要混淆了收缩事务日志文件和收缩数据文件,当事务日志文件的增长失控或为了移除过多的VLF碎片(这里和这里看到金佰利的优秀文章),然而,收缩事务日志数据文件不要频繁使用(罕见的操作)并且不应是你执行定期维护计划的一部分。
收缩数据文件应该执行得甚至更少。这就是为什么——数据文件收缩导致产生了大量索引碎片,让我用一个简单并且你可以运行的脚步来演示。下面的脚本将会创建一个数据文件,创建一个10MB大小的“filler”表,一个10MB大小的“production”聚簇索引,然后分析新建的聚集索引的碎片情况。
USE [master];
GO
IF DATABASEPROPERTYEX(N'DBMaint2008', N'Version') IS NOT NULL
DROP DATABASE [DBMaint2008];
GO
CREATE DATABASE DBMaint2008;
GO
USE [DBMaint2008];
GO
SET NOCOUNT ON;
GO
-- Create the 10MB filler table at the 'front' of the data file
CREATE TABLE [FillerTable](
[c1] INT IDENTITY,
[c2] CHAR (8000) DEFAULT 'filler');
GO
-- Fill up the filler table
INSERT INTO [FillerTable] DEFAULT VALUES;
GO 1280
-- Create the production table, which will be 'after' the filler table in the data file
CREATE TABLE [ProdTable](
[c1] INT IDENTITY,
[c2] CHAR (8000) DEFAULT 'production');
CREATE CLUSTERED INDEX [prod_cl] ON [ProdTable]([c1]);
GO
INSERT INTO [ProdTable] DEFAULT VALUES;
GO 1280
-- Check the fragmentation of the production table
SELECT
[avg_fragmentation_in_percent]
FROM sys.dm_db_index_physical_stats(
DB_ID(N'DBMaint2008'), OBJECT_ID(N'ProdTable'), 1, NULL, 'LIMITED');
GO
执行结果如下

聚集索引的逻辑碎片在收缩数据文件前大约接近0.4%。[但是我测试结果是0.54%,如上图所示,不过也算是接近0.4%]
现在我删除filter表,运行收缩数据文件命令后,重新分析聚集索引的碎片化。
-- Drop the filler table, creating 10MB of free space at the 'front' of the data file
DROP TABLE [FillerTable];
GO
-- Shrink the database
DBCC SHRINKDATABASE([DBMaint2008]);
GO
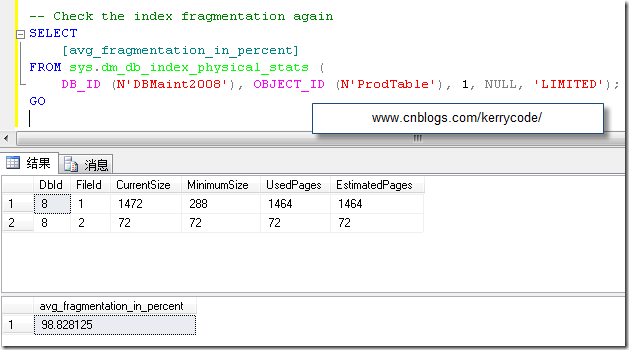
-- Check the index fragmentation again
SELECT
[avg_fragmentation_in_percent]
FROM sys.dm_db_index_physical_stats(
DB_ID(N'DBMaint2008'), OBJECT_ID(N'ProdTable'), 1, NULL, 'LIMITED');
GO
下面是我的执行结果,作者执行结果,请看原文:
原文:
Wow! After the shrink, the logical fragmentation is almost 100%. The shrink operation *completely* fragmented the index, removing any chance of efficient range scans on it by ensuring the all range-scan readahead I/Os will be single-page I/Os.
译文:
哇,真是恐怖!数据文件收缩后,索引的逻辑碎片几乎接近100%,收缩数据文件导致了索引的完全碎片化。消除了任何关于它的有效范围扫描的机会,确保所有执行提前读范围扫描的 I/O 在单页的 I/O操作
为什么会这样呢? 当单个数据文件收缩操作一次后,它会用GAM位图索引找出数据文件中分配最高的页,然后尽可能的向前移动到文件能够移动的地方,就这样子,在上面的例子中,它完全反转了聚集索引,让它从非碎片化到完全碎片化。
同样的代码用于DBCC SHRINKFILE, DBCC SHRINKDATABASE,以及自动收缩,他们同样糟糕,就像索引的碎片化,数据文件的收缩同样产生了大量的I/O操作,耗费大量的CPU资源,并且生成了*load*事务日志,因为任何操作都会全部记录下来。
数据文件收缩决不能作为定期维护的一部分,你决不能启用“自动收缩”属性,我尝试把它从SQL 2005和SQL 2008产品中移除,它还存在的唯一原因是为了更好的向前兼容,不要掉入这样的陷阱:创建一个维护计划,重新生成所有索引,然后尝试回收重建索引耗费的空间采取收缩数据文件 — — 这就是你做的生成了大量事务日志,但实质没有提高性能的零和游戏。
所以,你为什么要运行一个收缩呢,?举例来说,如果你把一个相当大的数据库删除了相当大的比例,该数据库不太可能增长,或者你需要转移一个数据库文件前先清空数据文件?
译文:
我很想推荐的方法如下:
创建一个新的文件组
将所有受影响的表和索引移动到一个新的文件组用CREATE INDEX ... WITH (DROP_EXISTING=ON)的脚本,在移动表的同时,删除表中的碎片。
删掉那些你准备收缩的旧文件组,你反正要收缩(或缩小它的方式下来,如果它的主文件组)。
基本上你需要提供一些更多的空间,才可以收缩的旧文件,但它是一个更清晰的设置。
原文:
The method I like to recommend is as follows:
Create a new filegroup
Move all affected tables and indexes into the new filegroup using the CREATE INDEX … WITH (DROP_EXISTING = ON) ON syntax, to move the tables and remove fragmentation from them at the same time
Drop the old filegroup that you were going to shrink anyway (or shrink it way down if its the primary filegroup)
Basically you need to provision some more space before you can shrink the old files, but it's a much cleaner mechanism.
如果你完全没有选择需要收缩日志文件,请注意这个操作会导致索引的碎片化,你应该在收缩数据文件采取一些步骤消除它可能导致的性能问题,唯一的方式是用DBCC INDEXDEFPAGE或 ALTER INDEX ...REORGANIZE消除索引的碎片不要引起数据文件的增长,这些命令要求扩展空间8KB的页代替重建一个新的索引在索引重建操作中。
底线 — — 尽量避免不惜一切代价运行数据文件收缩
所以,还在用作业定期收缩数据文件或数据库开启了“自动收缩”属性的朋友们,请及时纠正你们的错误认识吧!
支持原著,也希望大家支持我辛苦的翻译劳动,请加上链接潇湘隐者博客。


 咨 询 客 服
咨 询 客 服