问题描述:
在使用了alwayson后,主从库实时同步,原理是通过事务日志同步的,所以造成主数据库的事务日志一直在使用,而且无法收缩主数据库的事务日志。
在主从库同步时,收缩数据库是不起作用的。由于主数据库无法收缩,所以从数据库的日志也会一直跟着增长,造成磁盘空间一直增长。
网上大量的收缩日志的方法,基本上都不管用,怀疑根本没有在实际环境中使用过,以下方案是我在实际中使用后总结记录的。
解决方案:
最开始发现这个问题后,也是研究了好久,发现的方法,先是全手动操作。因为这些操作,并不能用语句来实现自动化,所以一直是手动处理的。
可能人都是比较懒的吧(人只有懒,才能促进机械自动化,才会有各种发表创造!不是吗?呵呵),一直想能过脚本,实现自动化。
今天终于摸索出来了,总结一下。
大概的思路如下
通过脚本将alwayson从库,从可用性数据库是移除,就是取消主从同步,这样主库变成单库模式了。然后再收缩事务日志,收缩后再把主从数据库加上。
考虑到有一点,操作中需要删除从库上的数据库,为防止操作错误,把主库的数据库删除了,这个操作相当危险啊,所以将脚本分为三个。在两个机器上来回操作。
第一个脚本在db1上执行。
第二个脚本在db3上执行
第三个脚本在db1上执行
(这里db1是主库,db3是从库。不要问我db2呢,因为创建时先创建的db2后来db2有问题删除了。你根据你的实际情况替换就行了。)
待时机成熟,或者加上判断,可以考虑将以下三个脚本合成一个脚本,然后一键执行,或者加到定时任务,每月自动执行一次。
以下脚本经过亲测可用
syncdb 为alwayson同步的名字,
DBSERVER1和DBSERVER3是主从数据库的名称。DBSERVER1为主库,DBSERVER3为从库。
:Connect DBSERVER1 -U sa -P abc@123 是使用SQLCMD模式连接数据库,请修改后面的密码。
test为数据库名称。
1、取消主从同步
--- YOU MUST EXECUTE THE FOLLOWING SCRIPT IN SQLCMD MODE.
:Connect DBSERVER1 -U sa -P abc@123
USE [master]
GO
ALTER AVAILABILITY GROUP [syncdb] REMOVE DATABASE [test];
GO
2 删除从库上的数据库,在收拾后,再添加上。
:Connect DBSERVER3 -U sa -P abc@123
USE [master]
GO
DROP DATABASE [test]
GO
3.备份事务日志,收缩日志文件,添加从库数据库。
--- YOU MUST EXECUTE THE FOLLOWING SCRIPT IN SQLCMD MODE.
:Connect DBSERVER1 -U sa -P abc@123
USE [master]
GO
BACKUP LOG [test] TO DISK='NUL:'with STATS = 10
go
use [test]
go
DBCC SHRINKFILE (N'test_log' , 20480)
GO
USE [master]
GO
ALTER AVAILABILITY GROUP [test]
ADD DATABASE [test];
GO
:Connect DBSERVER1 -U sa -P test@123
BACKUP DATABASE [test] TO DISK = N'\\dbserver3\e$\share\test.bak' WITH COPY_ONLY, FORMAT, INIT, SKIP, REWIND, NOUNLOAD, COMPRESSION, STATS = 5
GO
:Connect DBSERVER3 -U sa -P test@123
RESTORE DATABASE [test] FROM DISK = N'\\dbserver3\e$\share\test.bak' WITH NORECOVERY, NOUNLOAD, STATS = 5
GO
:Connect DBSERVER1 -U sa -P test@123
BACKUP LOG [test] TO DISK = N'\\dbserver3\e$\share\test.trn' WITH NOFORMAT, NOINIT, NOSKIP, REWIND, NOUNLOAD, COMPRESSION, STATS = 5
GO
:Connect DBSERVER3 -U sa -P test@123
RESTORE LOG [test] FROM DISK = N'\\dbserver3\e$\share\test.trn' WITH NORECOVERY, NOUNLOAD, STATS = 5
GO
:Connect DBSERVER3 -U sa -P test@123
-- Wait for the replica to start communicating
begin try
declare @conn bit
declare @count int
declare @replica_id uniqueidentifier
declare @group_id uniqueidentifier
set @conn = 0
set @count = 30 -- wait for 5 minutes
if (serverproperty('IsHadrEnabled') = 1)
and (isnull((select member_state from master.sys.dm_hadr_cluster_members where upper(member_name COLLATE Latin1_General_CI_AS) = upper(cast(serverproperty('ComputerNamePhysicalNetBIOS') as nvarchar(256)) COLLATE Latin1_General_CI_AS)), 0) > 0)
and (isnull((select state from master.sys.database_mirroring_endpoints), 1) = 0)
begin
select @group_id = ags.group_id from master.sys.availability_groups as ags where name = N'yorkdb'
select @replica_id = replicas.replica_id from master.sys.availability_replicas as replicas where upper(replicas.replica_server_name COLLATE Latin1_General_CI_AS) = upper(@@SERVERNAME COLLATE Latin1_General_CI_AS) and group_id = @group_id
while @conn > 1 and @count > 0
begin
set @conn = isnull((select connected_state from master.sys.dm_hadr_availability_replica_states as states where states.replica_id = @replica_id), 1)
if @conn = 1
begin
-- exit loop when the replica is connected, or if the query cannot find the replica status
break
end
waitfor delay '00:00:10'
set @count = @count - 1
end
end
end try
begin catch
-- If the wait loop fails, do not stop execution of the alter database statement
end catch
ALTER DATABASE [test] SET HADR AVAILABILITY GROUP = [syncdb];
GO
GO
在执行:Connect 命令前记得把SQLCMD模式打开
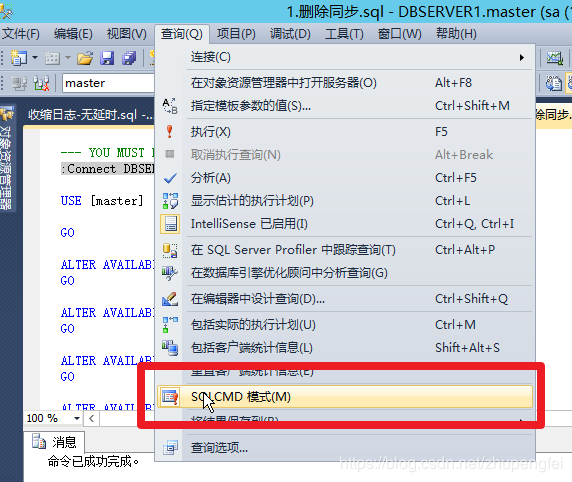
打开后,你能看到SQLCMD命令是灰色的。
到此这篇关于使用alwayson后如何收缩数据库日志的文章就介绍到这了,更多相关alwayson数据库日志内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
您可能感兴趣的文章:- SQL Server AlwaysOn读写分离配置图文教程
- SQL Server 2016 Alwayson新增功能图文详解
- SQL Server 2016 无域群集配置 AlwaysON 可用性组图文教程
- Windows2012配置SQLServer2014AlwaysOn的图解
- SQLServer 2012中设置AlwaysOn解决网络抖动导致的提交延迟问题
- 基于Win2008 R2的WSFC实现 SQL Server 2012高可用性组(AlwaysOn Group)


 咨 询 客 服
咨 询 客 服