目录
- 1、逻辑结构
- 2、物理结构
- 3、增删改查
- 4、应用场景
- 5、参考资料
HBase是一种分布式、可扩展、支持海量数据存储的NoSQL数据库。分布式是因为HBase底层使用HDFS存储数据,可扩展也是基于HDFS的横向扩展能力,作为大数据的存储当然支持海量数据的存储,NoSQL非关系型数据库表结构和关系型数据库(如Mysql)的逻辑结构、物理结构很不一样,性质特点、应用场景也不一样。
1、逻辑结构
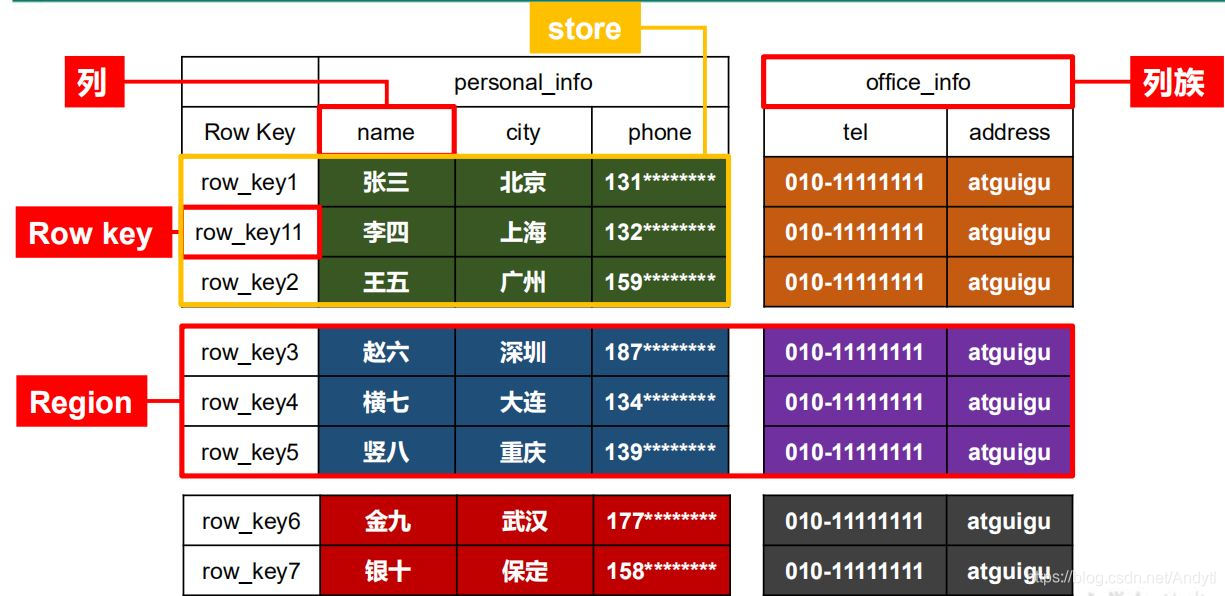
1)Name Space
命名空间,类似于关系型数据库的 DatabBase 概念,每个命名空间下有多个表。HBase有两个自带的命名空间,分别是 hbase 和 default,hbase 中存放的是 HBase 内置的表,default 表是用户默认使用的命名空间。
2)Region
类似于关系型数据库的表概念。不同的是,HBase 定义表时只需要声明列族即可,不需要声明具体的列。这意味着,往 HBase 写入数据时,字段可以动态、按需指定。因此,和关系型数据库相比,HBase 能够轻松应对字段变更的场景。
3)Row
HBase 表中的每行数据都由一个 RowKey 和多个 Column(列)组成,数据是按照 RowKey的字典顺序存储的,并且查询数据时只能根据 RowKey 进行检索,所以 RowKey 的设计十分重要。
4)Column
HBase 中的每个列都由 Column Family(列族)和 Column Qualifier(列限定符)进行限定,例如 info:name,info:age。建表时,只需指明列族,而列限定符无需预先定义。
5)Time Stamp
用于标识数据的不同版本(version),每条数据写入时,如果不指定时间戳,系统会自动为其加上该字段,其值为写入 HBase 的时间。
6)Cell
由{rowkey, column Family:column Qualifier, time Stamp} 唯一确定的单元。cell 中的数据是没有类型的,全部是字节码形式存贮。
2、物理结构
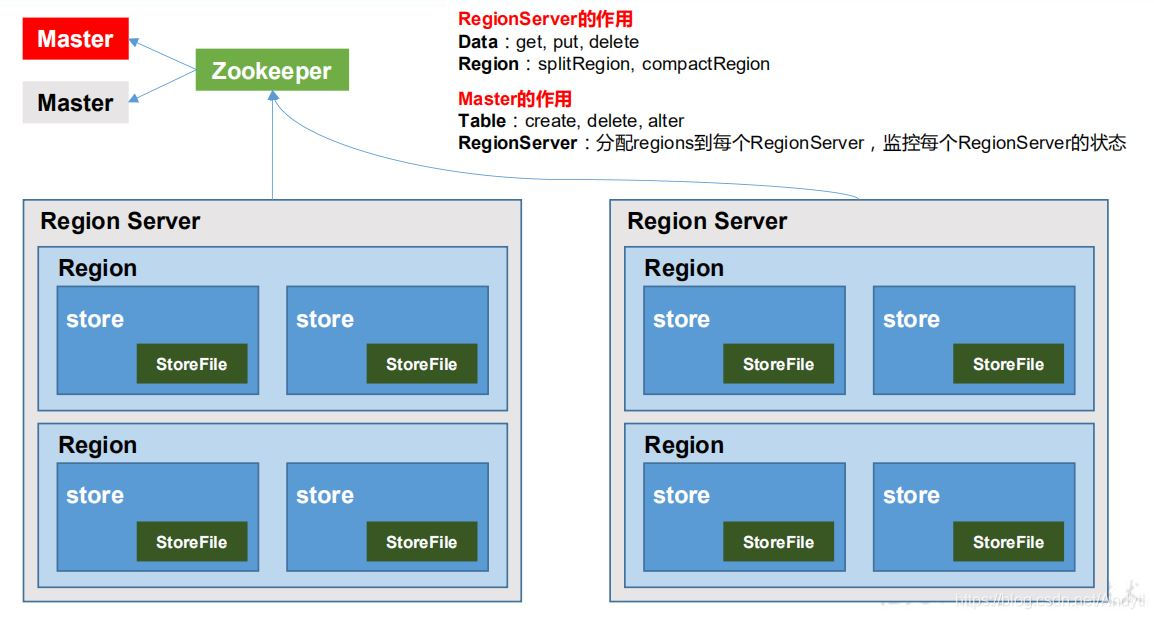
1)Region Server
Region Server 为 Region 的管理者,其实现类为 HRegionServer,主要作用如下:对于数据的操作:get, put, delete;对于 Region 的操作:splitRegion、compactRegion。
2)Master
Master 是所有 Region Server 的管理者,其实现类为 HMaster,主要作用如下:对于表的操作:create, delete, alter对于 RegionServer的操作:分配 regions到每个RegionServer,监控每个 RegionServer的状态,负载均衡和故障转移。
3)Zookeeper
HBase 通过 Zookeeper 来做 Master 的高可用、RegionServer 的监控、元数据的入口以及集群配置的维护等工作。
4)HDFS
HDFS 为 HBase 提供最终的底层数据存储服务,同时为 HBase 提供高可用的支持。
3、增删改查
初学或者测试阶段对HBase操作可以使用HBase shell。增删改查等基本命令如下:
(1)创建表
test是表名,cf是列族名,你会发现HBase的表在新建的时候并没有地方让你定义列(和关系型数据库很不一样吧)。这是因为HBase中的列全部都是灵活的,可以随便定义的。列只有在你插入第一条数据的时候才会生成。那么表的属性在哪里定义呢?其实HBase的所有数据属性都是定义在列族上的。
(2)查看表属性
输出:
hbase(main):002:0> desc 'test'
Table test is ENABLED
test, {TABLE_ATTRIBUTES => {DURABILITY => 'USE_DEFAULT', METADATA => {'IS_ROOT'
=> 'false', 'LINDORM_TABLE_ATTRS' => '\x00\x08\x00\x00\x00\x16WAL_EDIT_WITH_FULL
_ROW\x05false\x00\x00\x00\x0BCONSISTENCY\x08eventual\x00\x00\x00\x16LEADER_BALAN
CE_ENABLED\x01\xFF\x00\x00\x00\x1FFULL_ROW_EDIT_CARRY_LATEST_DATA\x04true\x00\x0
0\x00\x0FDYNAMIC_COLUMNS\x04true\x00\x00\x00\x0FALLOW_FILTERING\x01\x00\x00\x00\
x00\x13LEADER_BALANCE_TYPE\x06single\x00\x00\x00\x12DEFERRED_LOG_FLUSH\x05false'
, 'TABLEMETAVERSION' => '`\xE4n\x0F'}}
COLUMN FAMILIES DESCRIPTION
{NAME => 'cf', VERSIONS => '1', EVICT_BLOCKS_ON_CLOSE => 'false', NEW_VERSION_BE
HAVIOR => 'false', KEEP_DELETED_CELLS => 'FALSE', CACHE_DATA_ON_WRITE => 'false'
, DATA_BLOCK_ENCODING => 'DIFF', TTL => 'FOREVER', MIN_VERSIONS => '0', REPLICAT
ION_SCOPE => '0', BLOOMFILTER => 'ROW', CACHE_INDEX_ON_WRITE => 'false', IN_MEMO
RY => 'false', CACHE_BLOOMS_ON_WRITE => 'false', PREFETCH_BLOCKS_ON_OPEN => 'fal
se', COMPRESSION => 'ZSTD', BLOCKCACHE => 'true', BLOCKSIZE => '65536', METADATA
=> {'STORAGE_POLICY' => 'DEFAULT', 'COMPRESS_TAGS' => 'true', 'DFS_REPLICATION'
=> '2', 'CHS_PROMOTE_ON_MAJOR' => 'true'}}
1 row(s)
Took 0.2150 seconds
可以看出对表的描述不多,大量的是对列族的描述,列族更像是传统关系数据库中的表,而表本身反倒变成只是存放列族的空壳了。
(3)查看表
list
输出:
hbase(main):001:0> list
TABLE
test
test1
test2
test_ls
4 row(s)
Took 0.6370 seconds
=> ["test", "test1", "test2", "test_ls"]
(4)插入数据
put 'test','row1','cf:name','jack'
这条语句的意思就是:往test表插入一个单元格。这个单元格的rowkey为row1,也就是说它是属于row1这个行中的一个列。该单元格的列族为cf。该单元格的列名为name。数据值为jack。可见列是在插入数据的时候产生的,Hbase中列可以自由扩展。表的结构中某一行可能没有某个列,但数据并不以NULL替代,而是压根没有该单元格。这样以稀疏k-v方式存储数据可以大大压缩数据存储容量。
(5)扫描数据
输出:
hbase(main):011:0> scan 'test'
ROW COLUMN+CELL
row1 column=cf:name, timestamp=1625911358767, value=jack
1 row(s)
Took 0.5670 seconds
scan命令类似于Mysql中的select * from test。
(6)查看数据
scan命令是批量读取数据,查询某个单元格的数据可以用get命令,
get 'test','row1','cf:name'
由于HBase底层使用键值对存储数据,查询一个单元格的数据非常快,这和Mysql也完全不同。
(7)删除数据
delete 'test','row1','cf:name'
HBase删除记录并不是真的删除了数据,而是放置了一个墓碑标记(tombstone marker),把这个版本连同之前的版本都标记为不可见了。
(8)停用表
表删除之前要停用表
(9)删除表
4、应用场景
HBase采用的是Key/Value的存储方式,这意味着,即使随着数据量增大,也几乎不会导致查询的性能下降。凡事都不可能只有优点而没有缺点。数据分析是HBase的弱项,因为对于HBase乃至整个NoSQL生态圈来说,基本上都是不支持表关联的。
不适用的场景:主要需求是数据分析,比如做报表。单表数据量不超过千万。建议使用MySQL或者Oracle数据库。
适用的场景:单表数据量超千万,而且并发还挺高。数据分析需求较弱,或者不需要那么灵活或者实时。
5、参考资料
《HBase不睡觉书》
《HBase原理与实践》
B站视频《尚硅谷HBase教程(hbase框架快速入门)》
到此这篇关于Hbase列式存储入门的文章就介绍到这了,更多相关Hbase列式存储内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
您可能感兴趣的文章:- 使用Java对Hbase操作总结及示例代码
- python利用thrift服务读取hbase数据的方法
- HBASE 常用shell命令,增删改查方法
- hbase-shell批量命令执行脚本的方法


 咨 询 客 服
咨 询 客 服