redis数据结构之intset的实例详解
在redis中,intset主要用于保存整数值,由于其底层是使用数组来保存数据的,因而当对集合进行数据添加时需要对集合进行扩容和迁移操作,因而也只有在数据量不大时redis才使用该数据结构来保存整数集合。其具体的底层数据结构如下:
typedef struct intset {
// 编码方式
uint32_t encoding;
// 集合包含的元素数量
uint32_t length;
// 保存元素的数组
int8_t contents[];
} intset;
整数集合主要有三个属性:encoding用于保存当前集合的编码,有16位,32位和64位三种;length保存了当前整数集合中保存的数据数量;contents属性则保存了具体的数据,其每个数据占用的位数由encoding属性指定。
这里主要需要进行说明的是redis的intset中数据是采用从小到大的顺序存储的,因而对于数据的查询可以采用二分法进行查询,具体的搜索代码如下:
static uint8_t intsetSearch(intset *is, int64_t value, uint32_t *pos) {
int min = 0, max = intrev32ifbe(is->length)-1, mid = -1;
int64_t cur = -1;
/* The value can never be found when the set is empty */
// 处理 is 为空时的情况
if (intrev32ifbe(is->length) == 0) {
if (pos) *pos = 0;
return 0;
} else {
/* Check for the case where we know we cannot find the value,
* but do know the insert position. */
// 因为底层数组是有序的,如果 value 比数组中最后一个值都要大
// 那么 value 肯定不存在于集合中,
// 并且应该将 value 添加到底层数组的最末端
if (value > _intsetGet(is,intrev32ifbe(is->length)-1)) {
if (pos) *pos = intrev32ifbe(is->length);
return 0;
// 因为底层数组是有序的,如果 value 比数组中最前一个值都要小
// 那么 value 肯定不存在于集合中,
// 并且应该将它添加到底层数组的最前端
} else if (value _intsetGet(is,0)) {
if (pos) *pos = 0;
return 0;
}
}
// 在有序数组中进行二分查找
// T = O(log N)
while(max >= min) {
mid = (min+max)/2;
cur = _intsetGet(is,mid);
if (value > cur) {
min = mid+1;
} else if (value cur) {
max = mid-1;
} else {
break;
}
}
// 检查是否已经找到了 value
if (value == cur) {
if (pos) *pos = mid;
return 1;
} else {
if (pos) *pos = min;
return 0;
}
}
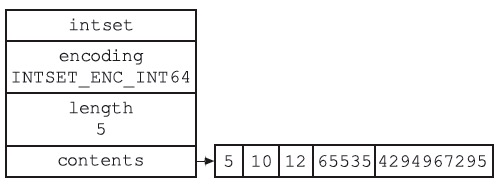
此外,整数集合中具体还有两个需要说明的操作是升级和降级。升级指的是当向低编码的整数集合中添加位数较高的数值时,就会扩容并将整数集合中的所有元素都转换为高位数的编码格式,然后把新添加的元素插入到指定位置;降级指的是当将整数集合中唯一一个高位的元素删除时会将其余元素转换为低位数的编码格式,但是为了提升速率,redis中并不会为剩余元素重新分配内存并进行编码转换,而只是会将该高位元素给删除,并重新分配内存给剩余的元素,然后迁移数据。如图是inset保存数据的示例:
如有疑问请留言或者到本站社区交流讨论,感谢阅读,希望能帮助到大家,谢谢大家对本站的支持!
您可能感兴趣的文章:- Redis底层数据结构详解
- 详解Redis数据结构之跳跃表
- redis中的数据结构和编码详解
- redis内部数据结构之SDS简单动态字符串详解
- 详解redis数据结构之sds
- 详解redis数据结构之压缩列表
- Redis中5种数据结构的使用场景介绍
- Redis底层数据结构之dict、ziplist、quicklist详解


 咨 询 客 服
咨 询 客 服