本文主要讨论PostgreSQL中大小写不敏感存在的问题。
默认情况下,PostgreSQL会将列名和表名全部转换为小写状态。
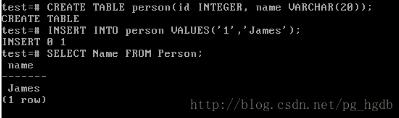
图1 Person与person
如图1所示,我们创建表person,其中包含name列。然后插入一条记录。执行SELECT查询时,使用列名Name和表名Person而不是name和person,发现仍然可以正常获取刚刚插入表person中的记录。

图2 创建表Person?
此时如果我们再想创建表Person,会得到一个错误,因为此时PostgreSQL实际上把表名从Person转换成了person。由于已经存在表person,所以会报错。
通常情况下,这种大小写不敏感是很方便的,但是当我们想创建大小写敏感的表名和列名(需要使用双引号)时,会产生一些问题。
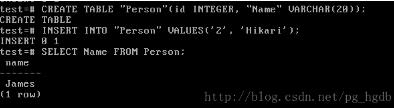
图3 创建表Person
如图3所示,我们成功创建了表Person,并插入了一条记录,此条记录和插入person中的不同以示区分。再次使用SELECT查询,并且使用表名Person和列名Name,但是返回的结果却是person中的记录。这还是因为PostgreSQL将Person转换成了person。所以想要正确查询,需要使用“Person”和“Name”(如图4所示)。
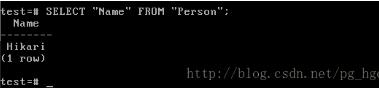
图4 获取表Person中的记录
此时查看数据库中的表(见图5),可以发现Person和person这两个表都在数据库中。如果我们使用DROP TABLE Person,删除的仍然是表person。
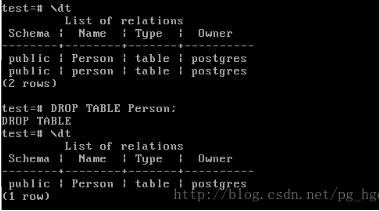
图5 删除操作
综上所述,当创建表或者写SQL查询语句时,建议避免使用双引号。
补充:PostgreSQL大小写不敏感排序
pg12开始支持不区分大小写,或者区分大小写的排序的collate。
语法:
CREATE COLLATION [ IF NOT EXISTS ] name (
[ LOCALE = locale, ]
[ LC_COLLATE = lc_collate, ]
[ LC_CTYPE = lc_ctype, ]
[ PROVIDER = provider, ]
[ DETERMINISTIC = boolean, ]
[ VERSION = version ]
)
CREATE COLLATION [ IF NOT EXISTS ] name FROM existing_collation
其中两个关键参数:
PROVIDER:指定用于与此排序规则相关的区域服务的提供程序。可能的值是: icu、libc。 默认 是libc。但若要设置大小写不敏感,目前只支持icu。
DETERMINISTIC:设置成not deterministic表示大小写不敏感。
例子:
—正常情况的排序
我们可以看到,正常的order by会区分大小写。
bill@bill=>create table test (c1 text);
CREATE TABLE
bill@bill=>insert into test values ('a'),('b'),('c'),('A'),('B'),('C');
INSERT 0 6
bill@bill=>select * from test order by c1;
c1
----
A
B
C
a
b
c
(6 rows)
同样,在oracle中也是一样:
SQL> select * from test order by c1;
C1
--------------------------------------------------------------------------------
A
B
C
a
b
c
6 rows selected.
—不区分大小写排序
可以看到我们指定collate为zh_CN时便没有区分大小写排序。
bill@bill=>select * from test order by c1 collate "zh_CN";
c1
----
a
A
b
B
c
C
(6 rows)
我们也可以自定义collation支持不区分大小写的排序,但是需要注意在编译数据库的时候加上 —with-icu才可以,否则会出现报错:
bill@bill=>CREATE COLLATION case_insensitive (provider = icu, locale = 'zh_Hans', deterministic = false);
ERROR: ICU is not supported in this build
HINT: You need to rebuild PostgreSQL using --with-icu.
正常情况:
bill@bill=> CREATE COLLATION case_insensitive (provider = icu, locale = 'zh_Hans', deterministic = false);
CREATE COLLATION
bill@bill=> select * from test order by c1 collate "case_insensitive";
c1
----
a
A
b
B
c
C
(6 rows)
目前collate不支持=操作不区分大小写,目前需要citext插件。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持脚本之家。如有错误或未考虑完全的地方,望不吝赐教。
您可能感兴趣的文章:- PostgreSQL LIKE 大小写实例
- Postgresql 数据库转义字符操作
- postgresql~*符号的含义及用法说明
- postgresql数据库使用说明_实现时间范围查询
- postgresql 实现将数组变为行
- 基于PostgreSql 别名区分大小写的问题


 咨 询 客 服
咨 询 客 服