开窗函数:在开窗函数出现之前存在着很多用 SQL 语句很难解决的问题,很多都要通过复杂的相关子查询或者存储过程来完成。为了解决这些问题,在 2003 年 ISO SQL 标准加入了开窗函数,开窗函数的使用使得这些经典的难题可以被轻松的解决。目前在 MSSQLServer、Oracle、DB2 等主流数据库中都提供了对开窗函数的支持,不过非常遗憾的是 MYSQL 暂时还未对开窗函数给予支持。
开窗函数简介:与聚合函数一样,开窗函数也是对行集组进行聚合计算,但是它不像普通聚合函数那样每组只返回一个值,开窗函数可以为每组返回多个值,因为开窗函数所执行聚合计
算的行集组是窗口。在 ISO SQL 规定了这样的函数为开窗函数,在 Oracle 中则被称为分析函数。
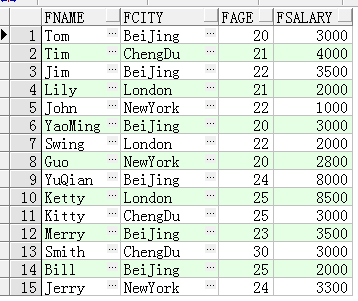
数据表(Oracle):T_Person 表保存了人员信息,FName 字段为人员姓名,FCity 字段为人员所在的城市名,FAge 字段为人员年龄,FSalary 字段为人员工资
CREATE TABLE T_Person (FName VARCHAR2(20),FCity VARCHAR2(20),FAge INT,FSalary INT)
向 T_Person 表中插入一些演示数据:
INSERT INTO T_Person(FName,FCity,FAge,FSalary)
VALUES('Tom','BeiJing',20,3000);
INSERT INTO T_Person(FName,FCity,FAge,FSalary)
VALUES('Tim','ChengDu',21,4000);
INSERT INTO T_Person(FName,FCity,FAge,FSalary)
VALUES('Jim','BeiJing',22,3500);
INSERT INTO T_Person(FName,FCity,FAge,FSalary)
VALUES('Lily','London',21,2000);
INSERT INTO T_Person(FName,FCity,FAge,FSalary)
VALUES('John','NewYork',22,1000);
INSERT INTO T_Person(FName,FCity,FAge,FSalary)
VALUES('YaoMing','BeiJing',20,3000);
INSERT INTO T_Person(FName,FCity,FAge,FSalary)
VALUES('Swing','London',22,2000);
INSERT INTO T_Person(FName,FCity,FAge,FSalary)
VALUES('Guo','NewYork',20,2800);
INSERT INTO T_Person(FName,FCity,FAge,FSalary)
VALUES('YuQian','BeiJing',24,8000);
INSERT INTO T_Person(FName,FCity,FAge,FSalary)
VALUES('Ketty','London',25,8500);
INSERT INTO T_Person(FName,FCity,FAge,FSalary)
VALUES('Kitty','ChengDu',25,3000);
INSERT INTO T_Person(FName,FCity,FAge,FSalary)
VALUES('Merry','BeiJing',23,3500);
INSERT INTO T_Person(FName,FCity,FAge,FSalary)
VALUES('Smith','ChengDu',30,3000);
INSERT INTO T_Person(FName,FCity,FAge,FSalary)
VALUES('Bill','BeiJing',25,2000);
INSERT INTO T_Person(FName,FCity,FAge,FSalary)
VALUES('Jerry','NewYork',24,3300);
select * from t_person:
要计算所有人员的总数,我们可以执行下面的 SQL 语句:SELECT COUNT(*) FROM T_Person
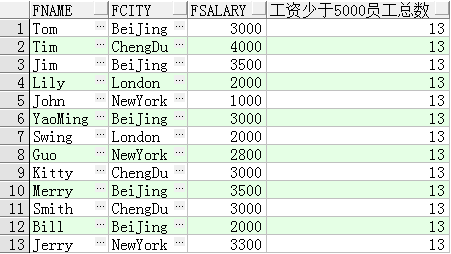
除了这种较简单的使用方式,有时需要从不在聚合函数中的行中访问这些聚合计算的值。比如我们想查询每个工资小于 5000 元的员工信息(城市以及年龄),并且在每行中都显示所有工资小于 5000 元的员工个数:
select fname,
fcity,
fsalary,
(select count(*) from t_person where fsalary 5000) 工资少于5000员工总数
from t_person
where fsalary 5000
虽然使用子查询能够解决这个问题,但是子查询的使用非常麻烦,使用开窗函数则可以大大简化实现,下面的 SQL 语句展示了如果使用开窗函数来实现同样的效果:
select fname, fcity, fsalary, count(*) over() 工资小于5000员工数
from t_person
where fsalary 5000
可以看到与聚合函数不同的是,开窗函数在聚合函数后增加了一个 OVER 关键字。
开窗函数格式: 函数名(列) OVER(选项)
OVER 关键字表示把函数当成开窗函数而不是聚合函数。SQL 标准允许将所有聚合函数用做开窗函数,使用 OVER 关键字来区分这两种用法。
在上边的例子中,开窗函数 COUNT(*) OVER()对于查询结果的每一行都返回所有符合条件的行的条数。OVER 关键字后的括号中还经常添加选项用以改变进行聚合运算的窗口范围。如果 OVER 关键字后的括号中的选项为空,则开窗函数会对结果集中的所有行进行聚合运算。
PARTITION BY 子句:
开窗函数的 OVER 关键字后括号中的可以使用 PARTITION BY 子句来定义行的分区来供进行聚合计算。与 GROUP BY 子句不同,PARTITION BY 子句创建的分区是独
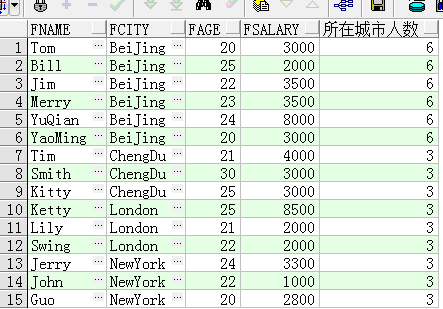
立于结果集的,创建的分区只是供进行聚合计算的,而且不同的开窗函数所创建的分区也不互相影响。下面的 SQL 语句用于显示每一个人员的信息以及所属城市的人员数:
select fname,fcity,fage,fsalary,count(*) over(partition by fcity) 所在城市人数 from t_person
COUNT(*) OVER(PARTITION BY FCITY)表示对结果集按照FCITY进行分区,并且计算当前行所属的组的聚合计算结果。比如对于FName等于 Tom的行,它所属的城市是BeiJing,同
属于BeiJing的人员一共有6个,所以对于这一列的显示结果为6。
这就不需要先对fcity分组求和,然后再和t_person表连接查询了,省事儿。
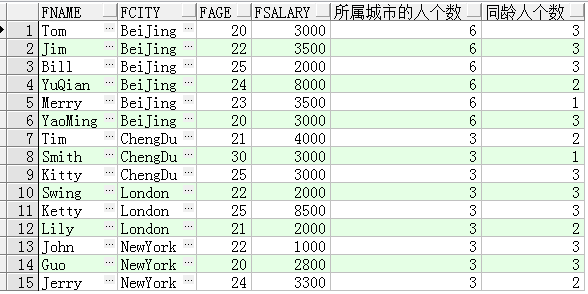
在同一个SELECT语句中可以同时使用多个开窗函数,而且这些开窗函数并不会相互干
扰。比如下面的SQL语句用于显示每一个人员的信息、所属城市的人员数以及同龄人的人数:
--显示每一个人员的信息、所属城市的人员数以及同龄人的人数:
select fname,
fcity,
fage,
fsalary,
count(*) over(partition by fcity) 所属城市的人个数,
count(*) over(partition by fage) 同龄人个数
from t_person
ORDER BY子句:
开窗函数中可以在OVER关键字后的选项中使用ORDER BY子句来指定排序规则,而且有的开窗函数还要求必须指定排序规则。使用ORDER BY子句可以对结果集按
照指定的排序规则进行排序,并且在一个指定的范围内进行聚合运算。ORDER BY子句的语法为:
ORDER BY 字段名 RANGE|ROWS BETWEEN 边界规则1 AND 边界规则2
RANGE表示按照值的范围进行范围的定义,而ROWS表示按照行的范围进行范围的定义;边界规则的可取值见下表:
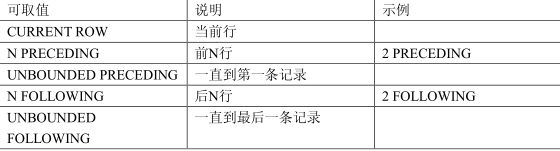
“RANGE|ROWS BETWEEN 边界规则1 AND 边界规则2”部分用来定位聚合计算范围,这个子句又被称为定位框架。
例子程序一:查询从第一行到当前行的工资总和:
select fname,
fcity,
fage,
fsalary,
sum(fsalary) over(order by fsalary rows between unbounded preceding and current row) 到当前行工资求和
from t_person
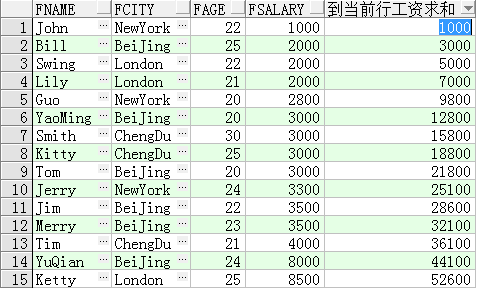
这里的开窗函数“SUM(FSalary) OVER(ORDER BY FSalary ROWS BETWEEN
UNBOUNDED PRECEDING AND CURRENT ROW)”表示按照FSalary进行排序,然后计算从第
一行(UNBOUNDED PRECEDING)到当前行(CURRENT ROW)的和,这样的计算结果就是按照
工资进行排序的工资值的累积和。
“RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW”是开窗函数中最常使用的定位框架,为了简化使用,如果使用的是这种定位框架,则可以省略定位框架声明部分,
也就是说上边的sql可以简化成:
select fname,
fcity,
fage,
fsalary,
sum(fsalary) over(order by fsalary) 到当前行工资求和
from t_person
例子程序二:把例子程序一的row换成了range,是按照范围进行定位的
select fname,
fcity,
fage,
fsalary,
sum(fsalary) over(order by fsalary range between unbounded preceding and current row) 到当前行工资求和
from t_person
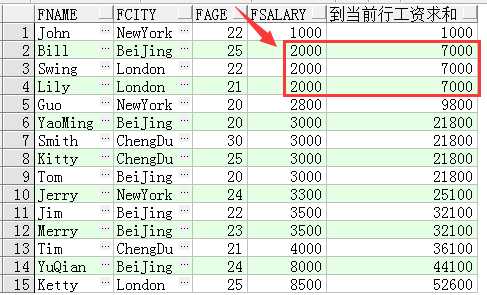
区别:
这个SQL语句与例1中的SQL语句唯一不同的就是“ROWS”被替换成了“RANGE”。“ROWS”
是按照行数进行范围定位的,而“RANGE”则是按照值范围进行定位的,这两个不同的定位方式
主要用来处理并列排序的情况。比如 Lily、Swing、Bill这三个人的工资都是2000元,如果按照
“ROWS”进行范围定位,则计算从第一条到当前行的累积和,而如果 如果按照 “RANGE”进行
范围定位,则仍然计算从第一条到当前行的累积和,不过由于等于2000元的工资有三个人,所
以计算的累积和为从第一条到2000元工资的人员结,所以对 Lily、Swing、Bill这三个人进行开
窗函数聚合计算的时候得到的都是7000( “ 1000+2000+2000+2000 ”)。
下边这的估计不常用:
例子程序三:
SELECT FName,
FSalary,
SUM(FSalary) OVER(ORDER BY FSalary ROWS BETWEEN 2 PRECEDING AND 2 FOLLOWING) 前二后二和
FROM T_Person;
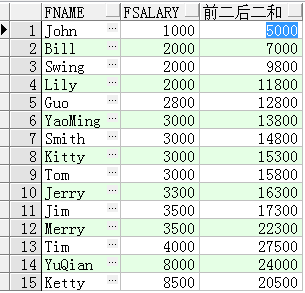
这里的开窗函数“SUM(FSalary) OVER(ORDER BY FSalary ROWS BETWEEN 2
PRECEDING AND 2 FOLLOWING)”表示按照FSalary进行排序,然后计算从当前行前两行(2
PRECEDING)到当前行后两行(2 FOLLOWING)的工资和,注意对于第一条和第二条而言它们
的“前两行”是不存在或者不完整的,因此计算的时候也是要按照前两行是不存在或者不完整进
行计算,同样对于最后两行数据而言它们的“后两行”也不存在或者不完整的,同样要进行类似
的处理。
例子程序四:
SELECT FName, FSalary,
SUM(FSalary) OVER(ORDER BY FSalary ROWS BETWEEN 1 FOLLOWING AND 3 FOLLOWING) 后面一到三之和
FROM T_Person;
这里的开窗函数“SUM(FSalary) OVER(ORDER BY FSalary ROWS BETWEEN 1
FOLLOWING AND 3 FOLLOWING)”表示按照FSalary进行排序,然后计算从当前行后一行(1
FOLLOWING)到后三行(3 FOLLOWING)的工资和。注意最后一行没有后续行,其计算结果为
空值NULL而非0。
例子程序五:算工资排名
SELECT FName, FSalary,
COUNT(*) OVER(ORDER BY FSalary ROWS BETWEEN UNBOUNDED PRECEDING AND
CURRENT ROW)
FROM T_Person;
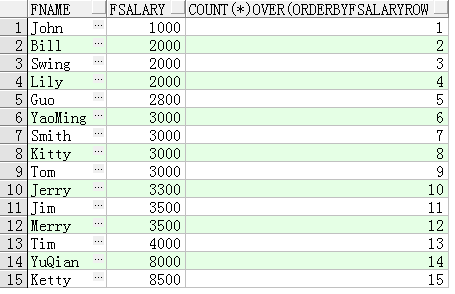
这里的开窗函数“COUNT(*) OVER(ORDER BY FSalary RANGE BETWEEN UNBOUNDED
PRECEDING AND CURRENT ROW)”表示按照FSalary进行排序,然后计算从第一行
(UNBOUNDED PRECEDING)到当前行(CURRENT ROW)的人员的个数,这个可以看作是计算
人员的工资水平排名。
不再用ROWNUM 了 省事了。这个over简写就会出错。
例子程序6:结合max求到目前行的最大值
SELECT FName, FSalary,FAge,
MAX(FSalary) OVER(ORDER BY FAge) 此行之前最大值
FROM T_Person;

这里的开窗函数“MAX(FSalary) OVER(ORDER BY FAge)”是“MAX(FSalary)
OVER(ORDER BY FAge RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW)”
的简化写法,它表示按照FSalary进行排序,然后计算从第一行(UNBOUNDED PRECEDING)
到当前行(CURRENT ROW)的人员的最大工资值。
例子程序6:over(partition by XX order by XX) partition by和order by 结合
员工信息+同龄人最高工资,按工资排序
SELECT FName, FSalary,FAge,
MAX(FSalary) OVER(PARTITION BY FAge order by fsalary) 同龄人最高工资
FROM T_Person;
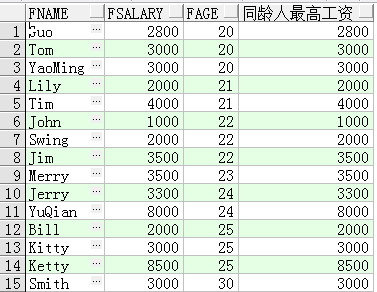
PARTITION BY子句和ORDER BY 可以 共 同 使用,从 而 可以 实现 更 加复 杂 的 功能
==================================================================================
高级开窗函数/ 排名的实现ROW_NUMBER();rank() ,dense_rank()
除了可以在开窗函数中使用COUNT()、SUM()、MIN()、MAX()、AVG()等这些聚合函数,
还可以在开窗函数中使用一些高级的函数,有些函数同时被DB2和Oracle同时支持,比如
RANK()、DENSE_RANK()、ROW_NUMBER(),而有些函数只被Oracle支持,比如
RATIO_TO_REPORT()、NTILE()、LEAD()、LAG()、FIRST_VALUE()、LAST_VALUE()。
下面对这几个函数进行详细介绍。
RANK()和DENSE_RANK()函数都可以用于计算一行的排名,不过对于并列排名的处理方式
不同;ROW_NUMBER()函数计算一行在结果集中的行号,同样可以将其当成排名函数。这三个
函数的功能存在一定的差异,举例如下:工资从高到低排名:
SELECT FName, FSalary,FAge,
RANK() OVER(ORDER BY fsalary desc) f_RANK,
DENSE_RANK() OVER(ORDER BY fsalary desc) f_DENSE_RANK,
ROW_NUMBER() OVER(ORDER BY fsalary desc) f_ROW_NUMBER
FROM T_Person;
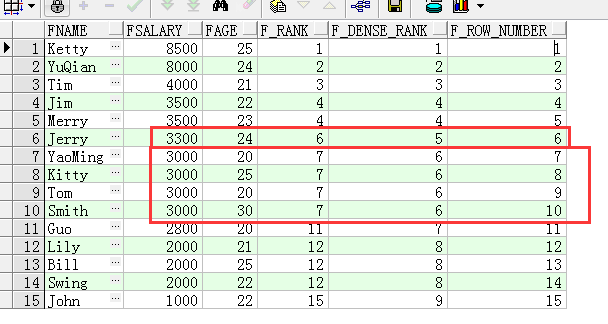
rank(),dense_rank()语法:
RANK()
dense_rank()
【语法】RANK ( ) OVER ( [query_partition_clause] order_by_clause )
dense_RANK ( ) OVER ( [query_partition_clause] order_by_clause )
【功能】聚合函数RANK 和 dense_rank 主要的功能是计算一组数值中的排序值。
【参数】dense_rank与rank()用法相当,
【区别】dence_rank在并列关系是,相关等级不会跳过。rank则跳过
rank()是跳跃排序,有两个第二名时接下来就是第四名(同样是在各个分组内)
dense_rank()l是连续排序,有两个第二名时仍然跟着第三名。
row_number() 函数语法:
ROW_NUMBER()
【语法】ROW_NUMBER() OVER (PARTITION BY COL1 ORDER BY COL2)
【功能】表示根据COL1分组,在分组内部根据 COL2排序,而这个值就表示每组内部排序后的顺序编号(组内连续的唯一的)
row_number() 返回的主要是“行”的信息,并没有排名
【参数】
【说明】Oracle分析函数
主要功能:用于取前几名,或者最后几名等
===================================================================
排序函数实际场景使用:计算排行榜,排名
微信活动,每天参与,有得分,活动结束后选出排名靠前的发奖。
每参与一次,就是一个订单,表结构:
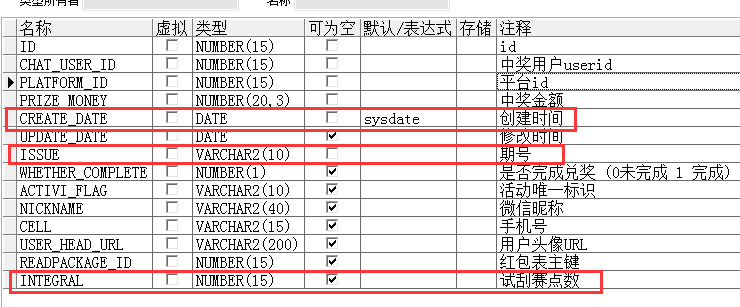
比如要查询期号issue为20170410期的排行榜,按得分倒叙排序,得分一样按订单创建先后,算排行,sql需要这么写:
select ROWNUM rank, t.*
from (select *
from t_zhcw_order
where issue = '20170410'
order by integral desc, create_date asc) t
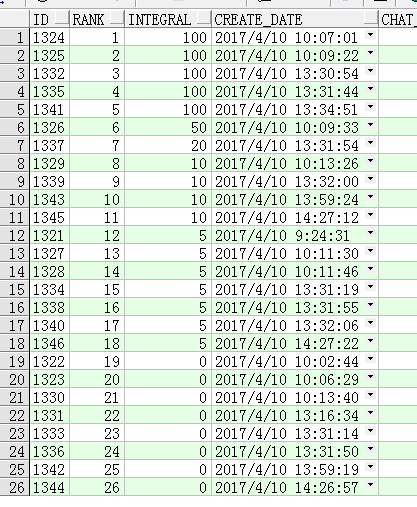
使用了开窗函数后就可以简化:
select t.*,
row_number() over(order by t.integral desc, t.create_date asc) 排名
from t_zhcw_order t
where issue = '20170410'
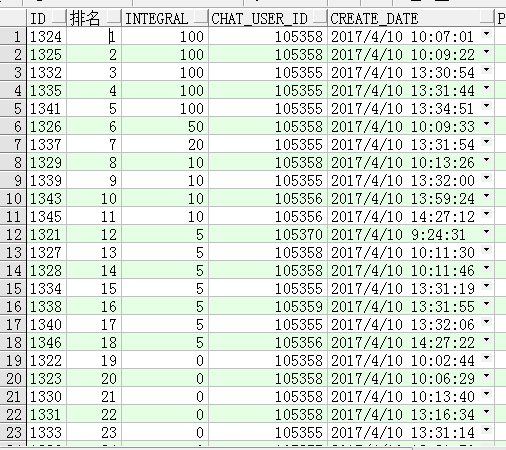
如果想只要排名范围,可以在外边再包一层,这也是高效分页的一种方式:
select tt.* from (
select t.id,
t.integral,
t.cell,
t.create_date,
row_number() over(order by t.integral desc, t.create_date asc) rankNum
from t_zhcw_order t
where t.issue = 20170331
)tt where tt.rankNum=50
到此这篇关于Oracle数据库中SQL开窗函数的使用的文章就介绍到这了,更多相关Oracle SQL开窗函数内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
您可能感兴趣的文章:- SQL中的开窗函数详解可代替聚合函数使用
- Sql Server 开窗函数Over()的使用实例详解
- SQL Server 2012 开窗函数
- sql server如何利用开窗函数over()进行分组统计


 咨 询 客 服
咨 询 客 服