聚簇,其实是相对于InnoDB这个数据库引擎来说的,因此在将聚簇索引的时候,我们通过InnoDB和MyISAM这两个MySQL的数据库引擎展开。
InnoDB和MyISAM的数据分布对比
CREATE TABLE test (col1 int NOT NULL,
col2 int NOT NULL,
PRIMARY KEY(col1),
KEY(col2));
首先通过以上SQL语句创建出一个表格,其中col1是主键,两列数据均创建了索引。然后我们数据的主键取值为1-10000,按照随机的顺序插入数据库中。
MyISAM的数据分布
MyISAM的数据存储逻辑比较简单,就是按照数据插入的顺序创建出一个数据表格。直观上来看如下图:
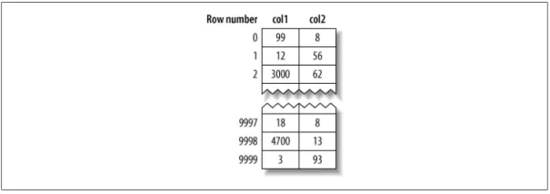
可以看出,数据就是按照插入的顺序“一行一行”生成的。前面还会有一个行号的字段,用处就是在查找到索引的时候能够快速地定位到该行索引的位置。
我们再来看一下具体的细节:
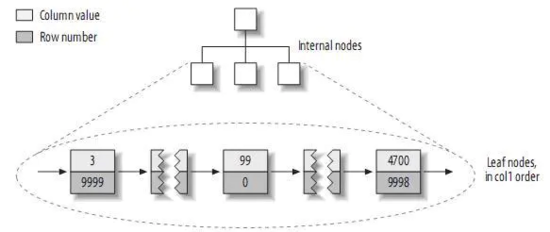
上图展示的情况就是在MyISAM引擎下,按照主键建立的索引的具体实现。可以看出在主键按照顺序排列在叶子结点上的同时,节点中还存储着这个主键在数据库表格中存在的具体的行号,正如我们上面所说的,这个行号可以帮助我们快速地定位到表中数据的位置,也可以把这个行号理解为一个指针,指向了这个主键所在的具体数据行。
那么如果我们按照col2建立索引呢?会有什么不同吗?答案是不会的:

所以得到的结论就是在MyISAM中建立索引是否是主键索引其实是没有区别的,唯一不同的就是这是一个“主键的索引”。
InnoDB的数据分布
因为InnoDB支持聚簇索引,所以会与MyISAM上的索引实现方式有所区别。
我们先看看基于主键的聚簇索引在InnoDB上的实现方式:

首先,和MyISAM上的主键索引一样,这里的索引的叶子结点上同样也是包括了主键的值,并且主键的值是按照顺序排列的。不同的是,每一个叶子结点还包括了事务id,回滚指针和其他非主键列的值(这里指的col2)。所以我们可以理解为InnoDB上的聚簇索引,是将原来表格中的所有的行数据按照主键进行排列然后放在了索引的叶子节点上。这就是一个与MyISAM在主键索引上的一个不同。 MyISAM的主键索引在查找到对应的主键值之后需要通过指针(行号)再去表中找到相对应的数据行,而InnoDB的主键索引,将数据信息全部放在了索引里面,可以直接在索引中查找拿到。
再来看看InnoDB中的二级索引的情况:
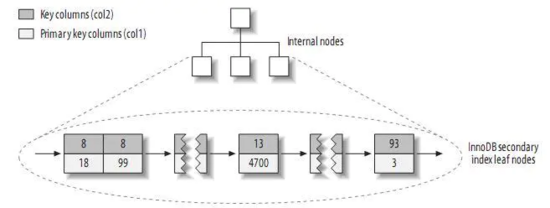
可以看到,和InnoDB中的主键索引不同,二级索引并没有在叶子结点存储所有的行数据信息,而是除了索引列的值外,只存储了这个数据行所对应的主键的信息。我们知道在MyISAM中,二级索引和主键索引一样,除了索引列的值外,只存储了一个指针(行号)的信息。
对比一下两个引擎上的二级索引。即存储指针和存储主键值的优劣。
首先存储主键值会比只存储一个指针带来的空间开销更大。但是当我们数据表在进行分裂或者其他改变结构的操作的时候,存储主键值的索引并不会收到影响,而存储指针的索引,可能就要重新进行更新维护。
用一个图对两个引擎中的两种索引进行对比:

总结
到此这篇关于MySQL学习教程之聚簇索引的文章就介绍到这了,更多相关MySQL聚簇索引内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
您可能感兴趣的文章:- 详解MySQL 聚簇索引与非聚簇索引
- mysql聚簇索引的页分裂原理实例分析
- 一看就懂的MySQL的聚簇索引及聚簇索引是如何长高的


 咨 询 客 服
咨 询 客 服