
| f_id | f_name | f_price |
|---|---|---|
| a1 | apple | 5 |
| a2 | appricot | 2 |
| b1 | blackberry | 10 |
| b2 | berry | 8 |
| c1 | cocount | 9 |
供应商表 suppliers表
| s_id | s_name |
|---|---|
| 101 | 天虹 |
| 102 | 沃尔玛 |
| 103 | 家乐福 |
| 104 | 华润万家 |
我们将用这两张表做演示。
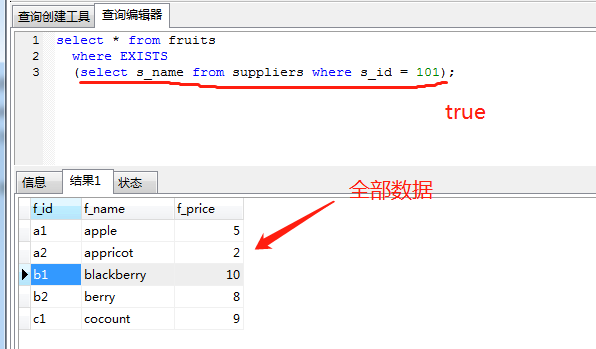
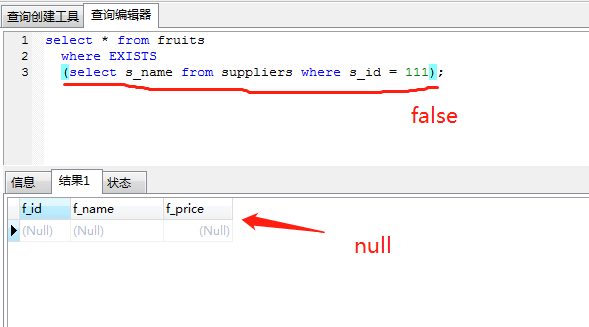
exists关键字后面的参数是一个任意的子查询,系统对子查询进行运算以判断它是否返回行,如果至少返回一行,那么exists的结果为true ,此时外层的查询语句将进行查询;如果子查询没有返回任何行,那么exists的结果为false,此时外层语句将不进行查询。
需要注意的是,当我们的子查询为 SELECT NULL 时,MYSQL仍然认为它是True。
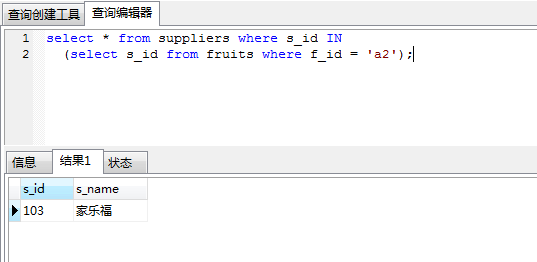
in 关键字进行子查询时,内层查询语句仅仅返回一个数据列,这个数据列的值将提供给外层查询语句进行比较操作。
为了测试in 关键字,我在水果表中加了s_id一列
水果表 fruits表
| f_id | f_name | f_price | s_id |
|---|---|---|---|
| a1 | apple | 5 | 101 |
| a2 | appricot | 2 | 103 |
| b1 | blackberry | 10 | 102 |
| b2 | berry | 8 | 104 |
| c1 | cocount | 9 | 103 |
in和exists到底有啥区别那,要什么时候用in,什么时候用exists?
我们先记住口诀再说细节!“外层查询表小于子查询表,则用exists,外层查询表大于子查询表,则用in,如果外层和子查询表差不多,则爱用哪个用哪个。”
我想你已经看出来了,当fruits表数据很大的时候不适合用in,因为它最多会将fruits表数据全部遍历一次。
如:suppliers表有10000条记录,fruits表有1000000条记录,那么最多有可能遍历10000*1000000次,效率很差。
再如:suppliers表有10000条记录,fruits表有100条记录,那么最多有可能遍历10000*100次,遍历次数大大减少,效率大大提升。
但是:suppliers表有10000条记录,fruits表有100条记录,那么exists()还是执行10000次,还不如使用in()遍历10000*100次,因为in()是在内存里遍历,而exists()需要查询数据库,我们都知道查询数据库所消耗的性能更高,而内存比较很快。
因此我们只需要记住口诀:“外层查询表小于子查询表,则用exists,外层查询表大于子查询表,则用in,如果外层和子查询表差不多,则爱用哪个用哪个。”

和exists一样,用到了suppliers上的id索引,exists()执行次数为fruits.length,不缓存exists()的结果集。

因为not in实质上等于!= and != ···,因为!=不会使用索引,故not in不会使用索引。
我们假设有100万数据,s_id只有0和1两个值,利用索引我们要先读索引文件,然后二分查找,找到对应的数据磁盘指针,再根据读到的指针在磁盘上对应的数据,影响结果集50万,这种情况,和直接全表扫描哪个快显而易见。
如果你s_id字段是一个unique,就会用到索引。
如果你一定要用索引,可以用force index,不过效率不会有改善一般还会更慢就是了。
合理使用索引,Cardinality是一个重要指标,太小的话跟没建没区别,还浪费空间。
因此,不管suppliers和fruits大小如何,均使用not exists效率会更高。
到此这篇关于MySQL中in和exists区别详解的文章就介绍到这了,更多相关MySQL in和exists区别内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!

 咨 询 客 服
咨 询 客 服