Join使用的是Nested-Loop Join算法,Nested-Loop Join有三种
select * from t1 join t2 on t1.a = t2.a;
-- a 100条数据, b 1000条数据
Simple Nested-Loop Join
会遍历t1全表,t1作为驱动表,t1中的每一条数据都会到t2中做一次全表查询,该过程会比较100*1000次。
每次在t2中做全表查询时,全表扫描可就不保证在内存里了,Buffer Pool会淘汰,有可能在磁盘。
Block Nested-Loop Join(MYSQL驱动链接没有使用索引)
会遍历t1全表,将t1数据加载到join_buffer中,再遍历t2全表,让t2的每条数据去匹配join_buffer中t1缓存的数据。
t1全表扫描 = 100次
t2全表扫描 = 1000次
查询次数 = 1100次
join_buffer中比较 = 100 * 1000次
比较的次数和Simple Nested-Loop Join是一样的,但是比较的过程会比Simple Nested-Loop Join快很多,性能更好。
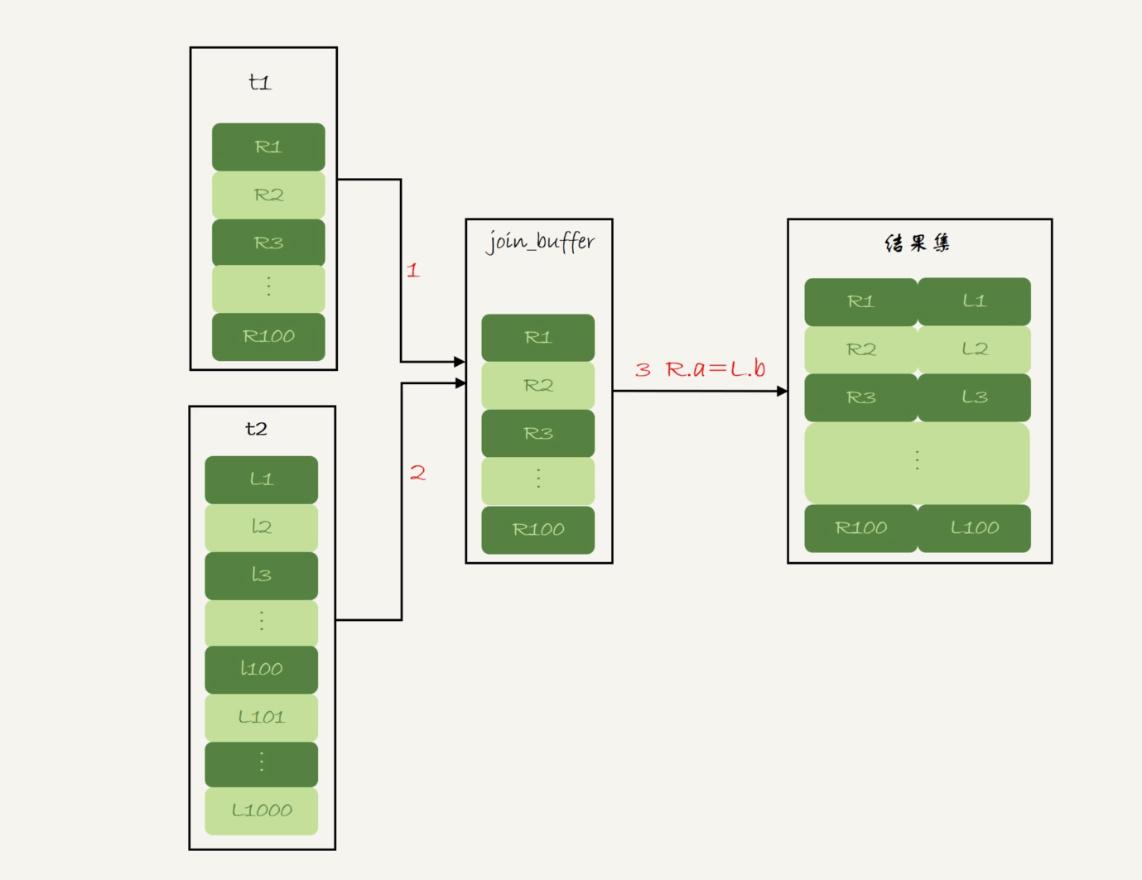
join_buffer是有大小的,如果t1查出来的数据是大于join_buffer大小的,则会先加载部分t1中的数据,比较完t2以后,清空join_buffer,再加载t1中剩余数据,加载不完全,再重复该操作。
t1全表扫描次数和join_buffer中比较1次数不变,但是t2的扫描次数会根据分段次数做一个乘法。
假设,驱动表的数据行数是 N,需要分 K 段才能完成算法流程,被驱动表的数据行数是 M。
K = λ * N
扫描被驱动表次数 = M * λ * N

λ是和join_buffer的大小有关的,join_buffer大小足够的情况下,大表驱动和小表驱动的时间是一样的。
需要分段的情况下,分段次数越少,被驱动表扫描的次数也会越少,所以应该采用小表驱动。
Index Nested-Loop Join(MYSQL驱动链接使用索引)
还是以上面的sql为例,如果a字段是有索引的。
t1表会扫描全表,t1表中每条数据会去t2表中做索引查询,查到id后再进行回表查询(如果连接字段是t2表的主键,回表操作将省略)。
t1扫描全表 = 100次
t2索引查询 = log1000次
t2回表查询 = log1000次
假设,驱动表的数据行数是 N,被驱动表的数据行数是 M。
总查询次数 = N + N * 2logM
由上可见,驱动表数据越大,查询的次数会越多,所以应该使用小表作为驱动表。
文章参考《MySQL实战45讲--第34讲》
总结
到此这篇关于MYSQL数据库基础之Join操作原理的文章就介绍到这了,更多相关MYSQL Join原理内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
您可能感兴趣的文章:- MySQL系列之开篇 MySQL关系型数据库基础概念
- Mysql数据库索引面试题(程序员基础技能)
- Python基础之操作MySQL数据库
- MySql数据库基础知识点总结
- 一篇文章带你了解MySQL数据库基础


 咨 询 客 服
咨 询 客 服
