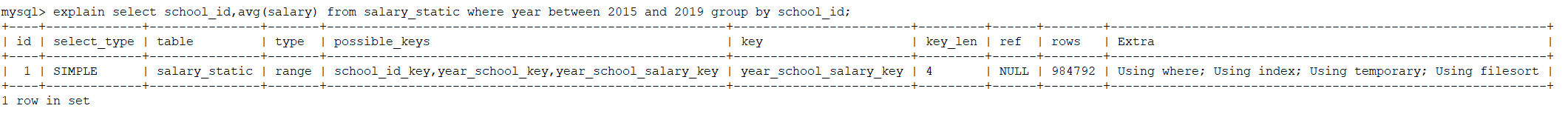CREATE TABLE `salary_static` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '自增主键',
`school_id` int(11) NOT NULL COMMENT '学校id',
`student_id` int(11) NOT NULL COMMENT '毕业生id',
`salary` int(11) NOT NULL DEFAULT '0' COMMENT '毕业薪水',
`year` int(11) NOT NULL COMMENT '毕业年份',
PRIMARY KEY (`id`),
KEY `school_id_key` (`school_id`) USING BTREE,
KEY `year_school_key` (`year`,`school_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='毕业生薪水数据统计';
delimiter //
CREATE PROCEDURE init_salary_static()
BEGIN
DECLARE year INT;
DECLARE schid INT;
DECLARE stuid INT;
SET year = 2000;
WHILE year 2020 DO
START TRANSACTION;
SET schid = 1;
WHILE schid 100 DO
SET stuid = 1;
WHILE stuid 1000 DO
insert into salary_static(school_id,student_id,salary,year) values (schid,stuid,floor(rand()*10000),year);
SET stuid = stuid + 1;
END WHILE;
SET schid = schid + 1;
END WHILE;
SET year = year + 1;
COMMIT;
END WHILE;
END //
delimiter ;
call init_salary_static();
测试数据创建完成后,执行以下sql语句进行统计查询。
select school_id,avg(salary) from salary_static where year between 2016 and 2019 group by school_id;
SET optimizer_trace="enabled=on";
select school_id,avg(salary) from salary_static where year between 2016 and 2019 group by school_id;
SELECT * FROM INFORMATION_SCHEMA.OPTIMIZER_TRACE;
table_scan全表扫描时预估需要扫描1973546条记录,通过show table status like "salary_static"命令可得全表记录为82411520字节(Data_length),innodb每个记录页为16KB即全表扫描需要读取82411520/1024/16 = 5030个记录页。


 咨 询 客 服
咨 询 客 服