简介
SQL Server 2014提供了众多激动人心的新功能,但其中我想最让人期待的特性之一就要算内存数据库了。去年我再西雅图参加SQL PASS Summit 2012的开幕式时,微软就宣布了将在下一个SQL Server版本中附带代号为Hekaton的内存数据库引擎。现在随着2014CTP1的到来,我们终于可以一窥其面貌。
内存数据库
在传统的数据库表中,由于磁盘的物理结构限制,表和索引的结构为B-Tree,这就使得该类索引在大并发的OLTP环境中显得非常乏力,虽然有很多办法来解决这类问题,比如说乐观并发控制,应用程序缓存,分布式等。但成本依然会略高。而随着这些年硬件的发展,现在服务器拥有几百G内存并不罕见,此外由于NUMA架构的成熟,也消除了多CPU访问内存的瓶颈问题,因此内存数据库得以出现。
内存的学名叫做Random Access Memory(RAM),因此如其特性一样,是随机访问的,因此对于内存,对应的数据结构也会是Hash-Index,而并发的隔离方式也对应的变成了MVCC,因此内存数据库可以在同样的硬件资源下,Handle更多的并发和请求,并且不会被锁阻塞,而SQL Server 2014集成了这个强大的功能,并不像Oracle的TimesTen需要额外付费,因此结合SSD AS Buffer Pool特性,所产生的效果将会非常值得期待。
SQL Server内存数据库的表现形式
在SQL Server的Hekaton引擎由两部分组成:内存优化表和本地编译存储过程。虽然Hekaton集成进了关系数据库引擎,但访问他们的方法对于客户端是透明的,这也意味着从客户端应用程序的角度来看,并不会知道Hekaton引擎的存在。如图1所示。

图1.客户端APP不会感知Hekaton引擎的存在
首先内存优化表完全不会再存在锁的概念(虽然之前的版本有快照隔离这个乐观并发控制的概念,但快照隔离仍然需要在修改数据的时候加锁),此外内存优化表Hash-Index结构使得随机读写的速度大大提高,另外内存优化表可以设置为非持久内存优化表,从而也就没有了日志(适合于ETL中间结果操作,但存在数据丢失的危险)
下面我们来看创建一个内存优化表:
首先,内存优化表需要数据库中存在一个特殊的文件组,以供存储内存优化表的CheckPoint文件,与传统的mdf或ldf文件不同的是,该文件组是一个目录而不是一个文件,因为CheckPoint文件只会附加,而不会修改,如图2所示。
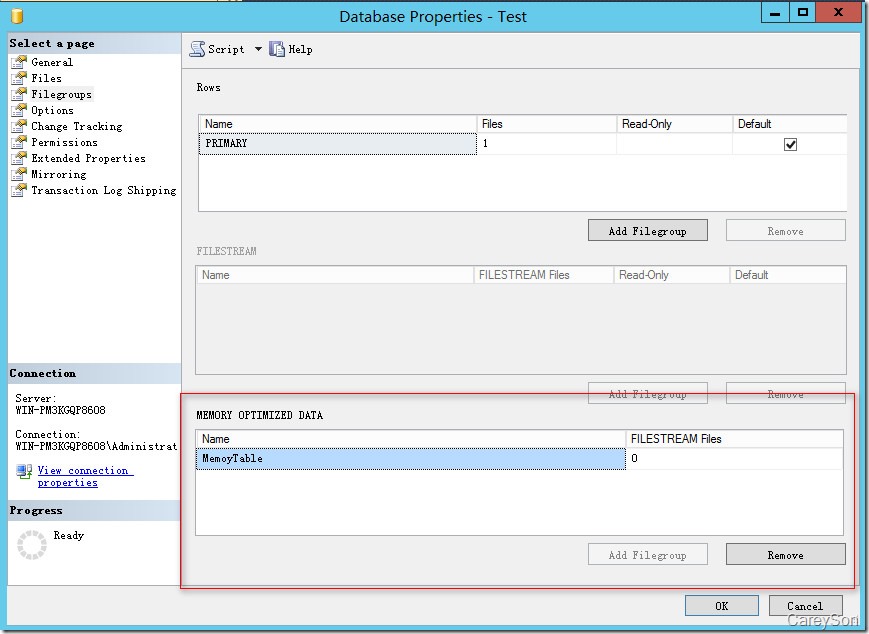
图2.内存优化表所需的特殊文件组
我们再来看一下内存优化文件组的样子,如图3所示。
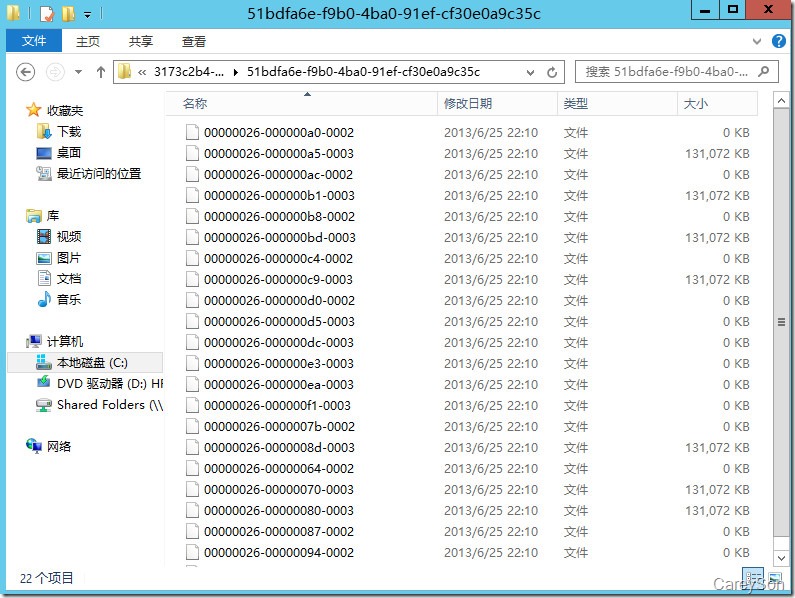
图3.内存优化文件组
有了文件组之后,接下来我们创建一个内存优化表,如图4所示。
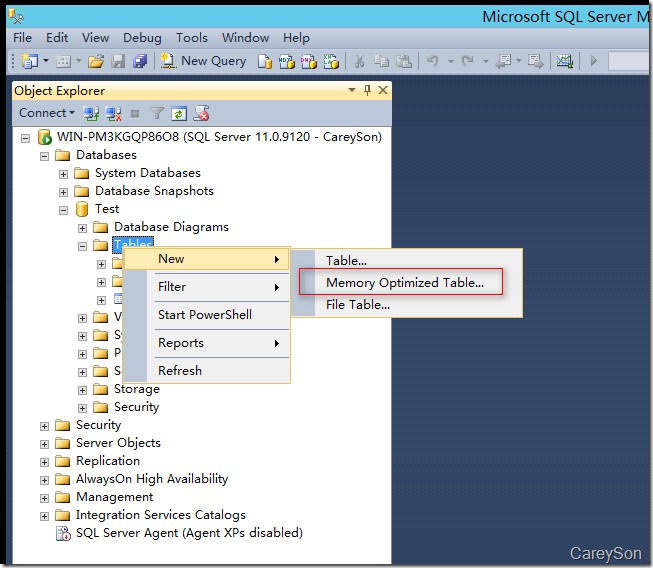
图4.创建内存优化表
目前SSMS还不支持UI界面创建内存优化表,因此只能通过T-SQL来创建内存优化表,如图5所示。

图5.使用代码创建内存优化表
当表创建好之后,就可以查询数据了,值得注意的是,查询内存优化表需要snapshot隔离等级或者hint,这个隔离等级与快照隔离是不同的,如图6所示。
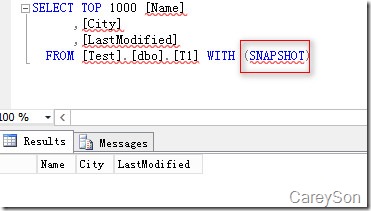
图6.查询内存优化表需要加提示
此外,由创建表的语句可以看出,目前SQL Server 2014内存优化表的Hash Index只支持固定的Bucket大小,不支持动态分配Bucket大小,因此这里需要注意。
与内存数据库不兼容的特性
目前来说,数据库镜像和复制是无法与内存优化表兼容的,但AlwaysOn,日志传送,备份还原是完整支持。
性能测试
上面扯了一堆理论,大家可能都看郁闷了。下面我来做一个简单的性能测试,来比对使用内存优化表+本地编译存储过程与传统的B-Tree表进行对比,B-Tree表如图7所示,内存优化表+本地编译存储过程如图8所示。

图7.传统的B-Tree表

图8.内存优化表+本地编译存储过程
因此不难看出,内存优化表+本地编译存储过程有接近几十倍的性能提升。
您可能感兴趣的文章:- SQL语句实现查询SQL Server内存使用状况
- 优化SQL Server的内存占用之执行缓存
- SQL Server 数据页缓冲区的内存瓶颈分析
- SqlServer如何通过SQL语句获取处理器(CPU)、内存(Memory)、磁盘(Disk)以及操作系统相关信息
- SQL Server 2008 R2占用cpu、内存越来越大的两种解决方法
- 解决SQL Server虚拟内存不足情况
- 浅谈SQL Server 对于内存的管理[图文]
- SQL Server内存遭遇操作系统进程压榨案例分析
- SQL Server在AlwaysOn中使用内存表的“踩坑”记录
- sql server学习基础之内存初探


 咨 询 客 服
咨 询 客 服