nil是什么
相信写过Golang的程序员对下面一段代码是非常非常熟悉的了:
if err != nil {
// do something....
}
当出现不等于nil的时候,说明出现某些错误了,需要我们对这个错误进行一些处理,而如果等于nil说明运行正常。那什么是nil呢?查一下词典可以知道,nil的意思是无,或者是零值。零值,zero value,是不是有点熟悉?在Go语言中,如果你声明了一个变量但是没有对它进行赋值操作,那么这个变量就会有一个类型的默认零值。
这是每种类型对应的零值:
bool -> false
numbers -> 0
string -> ""
pointers -> nil
slices -> nil
maps -> nil
channels -> nil
functions -> nil
interfaces -> nil
所以,我们经常将 nil 赋值给 error 类型,并且以此来判断是否有错误,那是因为 error 是个接口,而接口的零值就是 nil
type error interface {
Error() string
}
举个例子,当你定义了一个struct:
type Person struct {
AgeYears int
Name string
Friends []Person
}
var p Person // Person{0, "", nil}
变量p只声明但没有赋值,所以p的所有字段都有对应的零值。那么,这个nil到底是什么呢?Go的文档中说到,nil是预定义的标识符,代表指针、通道、函数、接口、映射或切片的零值,也就是预定义好的一个变量:
type Type int
var nil Type
是不是有点惊讶?nil并不是Go的关键字之一,你甚至可以自己去改变nil的值:
var nil = errors.New("hi")
这样是完全可以编译得过的,但是最好不要这样子去做。
nil有什么用
在了解了什么是nil之后,再来说说nil有什么用。
pointers
var p *int
p == nil // true
*p // panic: invalid memory address or nil pointer dereference
指针表示指向内存的地址,如果对为nil的指针进行解引用的话就会导致panic。那么为nil的指针有什么用呢?先来看一个计算二叉树和的例子:
type tree struct {
v int
l *tree
r *tree
}
// first solution
func (t *tree) Sum() int {
sum := t.v
if t.l != nil {
sum += t.l.Sum()
}
if t.r != nil {
sum += t.r.Sum()
}
return sum
}
上面的代码有两个问题,一个是代码重复:
另一个是当t是nil的时候会panic:
var t *tree
sum := t.Sum() // panic: invalid memory address or nil pointer dereference
怎么解决上面的问题?我们先来看看一个指针接收器的例子:
type person struct {}
func sayHi(p *person) { fmt.Println("hi") }
func (p *person) sayHi() { fmt.Println("hi") }
var p *person
p.sayHi() // hi
对于指针对象的方法来说,就算指针的值为nil也是可以调用的,基于此,我们可以对刚刚计算二叉树和的例子进行一下改造:
func(t *tree) Sum() int {
if t == nil {
return 0
}
return t.v + t.l.Sum() + t.r.Sum()
}
跟刚才的代码一对比是不是简洁了很多?对于nil指针,只需要在方法前面判断一下就ok了,无需重复判断。换成打印二叉树的值或者查找二叉树的某个值都是一样的:
func(t *tree) String() string {
if t == nil {
return ""
}
return fmt.Sprint(t.l, t.v, t.r)
}
// nil receivers are useful: Find
func (t *tree) Find(v int) bool {
if t == nil {
return false
}
return t.v == v || t.l.Find(v) || t.r.Find(v)
}
所以如果不是很需要的话,不要用NewX()去初始化值,而是使用它们的默认值。
slices
// nil slices
var s []slice
len(s) // 0
cap(s) // 0
for range s // iterates zero times
s[i] // panic: index out of range
一个为nil的slice,除了不能索引外,其他的操作都是可以的,当你需要填充值的时候可以使用append函数,slice会自动进行扩充。那么为nil的slice的底层结构是怎样的呢?根据官方的文档,slice有三个元素,分别是长度、容量、指向数组的指针:
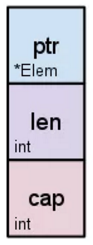
当有元素的时候:
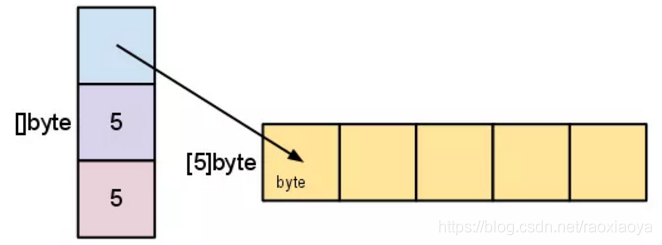
所以我们并不需要担心slice的大小,使用append的话slice会自动扩容。(视频中说slice自动扩容速度很快,不必担心性能问题,这个值得商榷,在确定slice大小的情况只进行一次内存分配总是好的)
map
对于Go来说,map,function,channel都是特殊的指针,指向各自特定的实现,这个我们暂时可以不用管。
// nil map
var m map[t]u
len(m) // 0
for range m // iterates zero times
v, ok := m[i] // zero(u), false
m[i] = x // panic: assignment to entry in nil map
对于nil的map,我们可以简单把它看成是一个只读的map,不能进行写操作,否则就会panic。那么nil的map有什么用呢?看一下这个例子:
func NewGet(url string, headers map[string]string) (*http.Request, error) {
req, err := http.NewRequest(http.MethodGet, url, nil)
if err != nil {
return nil, err
}
for k, v := range headers {
req.Header.Set(k, v)
}
return req, nil
}
对于NewGet来说,我们需要传入一个类型为map的参数,并且这个函数只是对这个参数进行读取,我们可以传入一个非空的值:
NewGet("http://google.com", map[string]string{
"USER_AGENT": "golang/gopher",
},)
或者这样传:
NewGet("http://google.com", map[string]string{})
但是前面也说了,map的零值是nil,所以当header为空的时候,我们也可以直接传入一个nil:
NewGet("http://google.com", nil)
是不是简洁很多?所以,把nil map作为一个只读的空的map进行读取吧。
channel
// nil channels
var c chan t
- c // blocks forever
c - x // blocks forever
close(c) // panic: close of nil channel
关闭一个nil的channel会导致程序panic(如何关闭channel可以看这篇文章:如何优雅地关闭Go channel)举个例子,假如现在有两个channel负责输入,一个channel负责汇总,简单的实现代码:
func merge(out chan- int, a, b -chan int) {
for {
select {
case v := -a:
out - v
case v := - b:
out - v
}
}
}
如果在外部调用中关闭了a或者b,那么就会不断地从a或者b中读出0,这和我们想要的不一样,我们想关闭a和b后就停止汇总了,修改一下代码:
func merge(out chan- int, a, b -chan int) {
for a != nil || b != nil {
select {
case v, ok := -a:
if !ok {
a = nil
fmt.Println("a is nil")
continue
}
out - v
case v, ok := -b:
if !ok {
b = nil
fmt.Println("b is nil")
continue
}
out - v
}
}
fmt.Println("close out")
close(out)
}
在知道channel关闭后,将channel的值设为nil,这样子就相当于将这个select case子句停用了,因为nil的channel是永远阻塞的。
interface
interface并不是一个指针,它的底层实现由两部分组成,一个是类型,一个值,也就是类似于:(Type, Value)。只有当类型和值都是nil的时候,才等于nil。看看下面的代码:
func do() error { // error(*doError, nil)
var err *doError
return err // nil of type *doError
}
func main() {
err := do()
fmt.Println(err == nil)
}
输出结果是false。do函数声明了一个*doErro的变量err,然后返回,返回值是error接口,但是这个时候的Type已经变成了:(*doError,nil),所以和nil肯定是不会相等的。所以我们在写函数的时候,不要声明具体的error变量,而是应该直接返回nil:
func do() error {
return nil
}
再来看看这个例子:
func do() *doError { // nil of type *doError
return nil
}
func wrapDo() error { // error (*doError, nil)
return do() // nil of type *doError
}
func main() {
err := wrapDo() // error (*doError, nil)
fmt.Println(err == nil) // false
}
这里最终的输出结果也是false。为什么呢?尽管wrapDo函数返回的是error类型,但是do返回的却是*doError类型,也就是变成了(*doError,nil),自然也就和nil不相等了。因此,不要返回具体的错误类型。遵从这两条建议,才可以放心地使用if x != nil。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持脚本之家。如有错误或未考虑完全的地方,望不吝赐教。
您可能感兴趣的文章:- golang interface判断为空nil的实现代码
- golang 中的 nil的场景分析
- Golang::slice和nil的对比分析
- golang:json 反序列化的[]和nil操作


 咨 询 客 服
咨 询 客 服