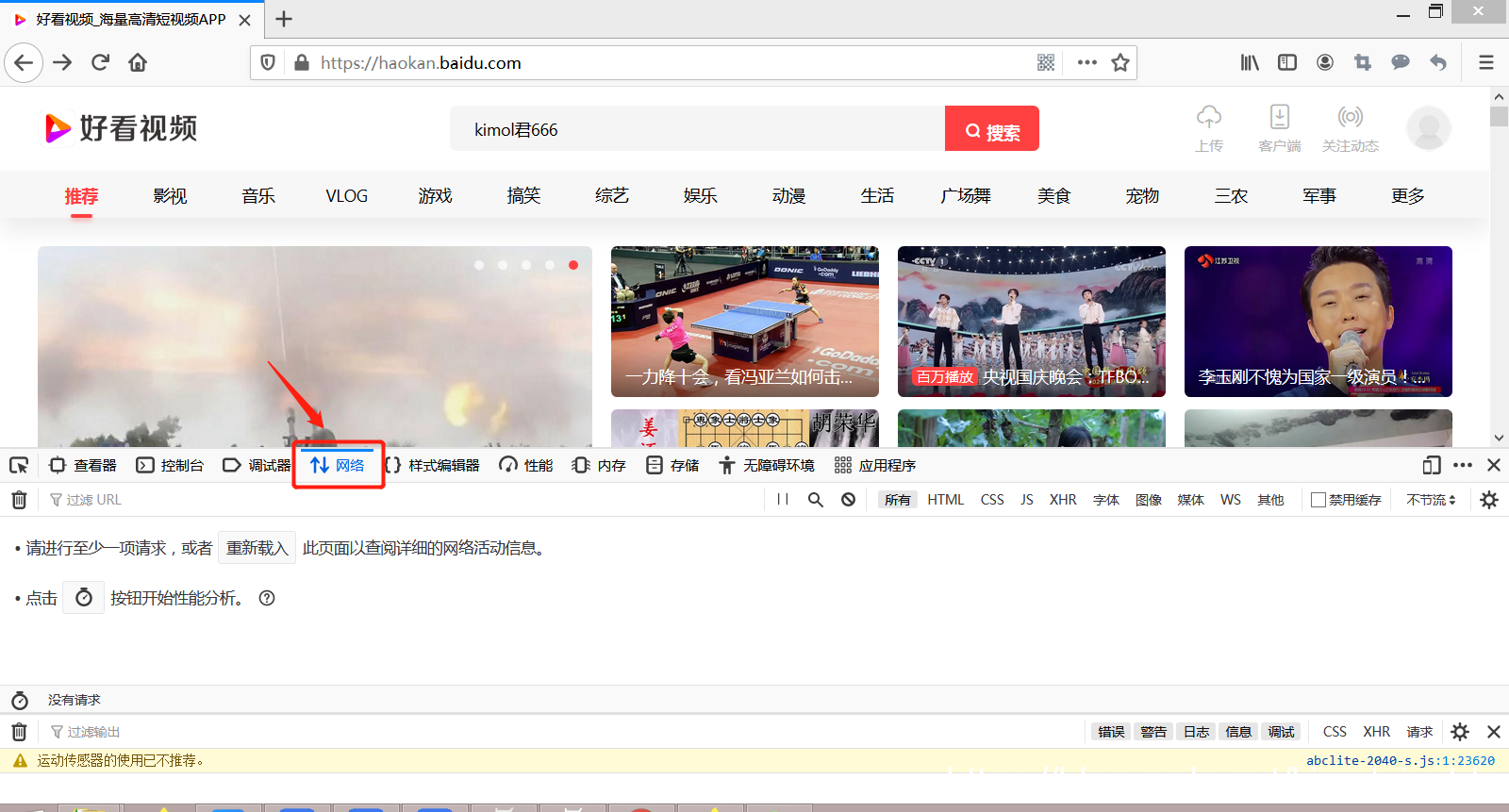
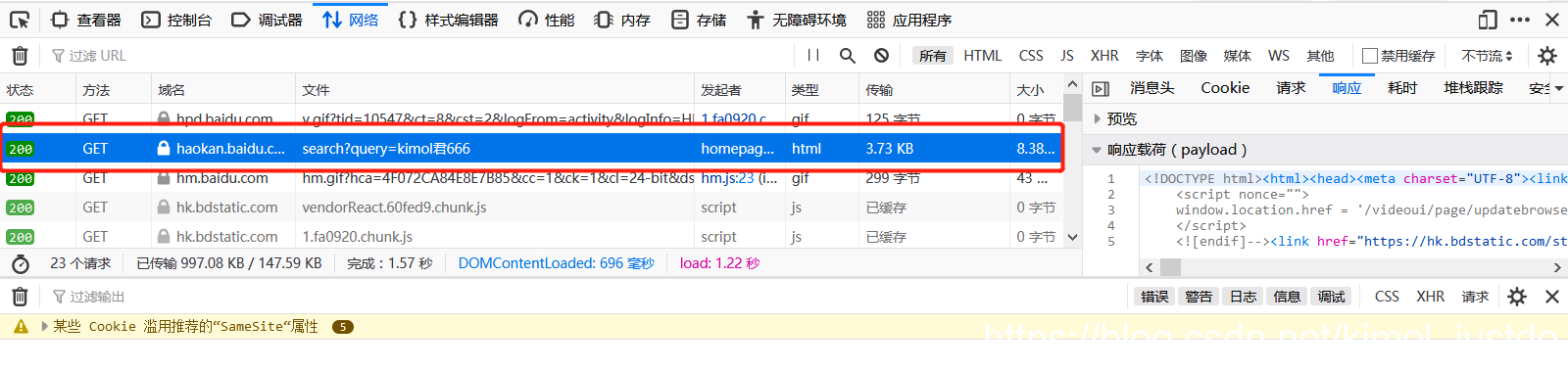
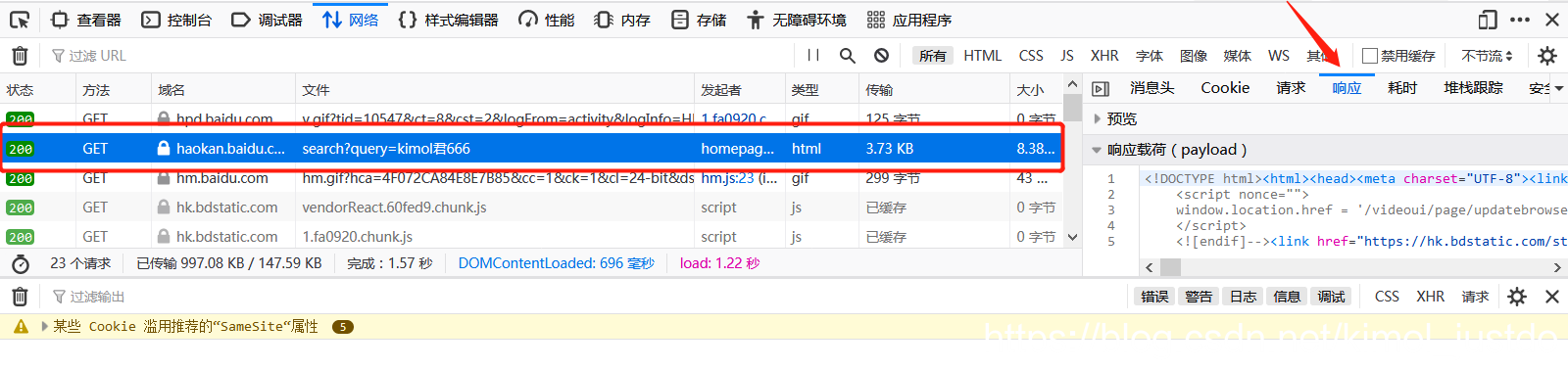
| 参数 | 说明 |
|---|---|
| pn | 请求的页码 |
| rn | 每次请求返回的数据量 |
| _format | 请求返回的数据格式 |
| tab | 请求的标签类型 |
那么,相应的代码可以改为:
import requests page = 1 keyword = 'xxxxx' # xxxxx为搜索的关键字 url = 'https://haokan.baidu.com/videoui/page/search?pn=%drn=10_format=jsontab=videoquery=%s'%(page,keyword) res = requests.get(url) data = res.json()
至此,视频搜索部分的分析算是告于段落了。
视频下载的思路也很清晰,只需进入播放视频的界面找到相应的视频原文件地址即可。
小手一点,我们便进到了一个视频的播放界面,我们可以发现其URL很有规律:它通过一个vid的参数来指向的相应视频。

右键视频播放页面查看源码(或者通过右键视频检查元素也可),我们可以找到视频播放的src,其对应的正则表达式为:
p = 'video class="video" src=(.*?)>'
那么,我们可以定义一个函数来解析视频的原文件地址:
def get_videoUrl(vid):
'''
提取视频信息中的视频源地址
'''
res = requests.get('https://haokan.baidu.com/v?vid=%s'%vid)
html = res.text
videoUrl = re.findall('video class="video" src=(.*?)>',html)[0]
return videoUrl
输入视频的id参数,将返回视频的真正文件地址。有了视频的地址,要下载视频便是信手拈来:
def download_video(vid): ''' 下载视频文件 ''' savePath = 'xxxxx.mp4' # 定义存储的文件名 videoUrl = get_videoUrl(vid) # 获取视频下载地址 res = requests.get(videoUrl) with open(savePath,'wb') as f: f.write(res.content)
至此,我们已经可以根据关键字搜索相关的视频,并且可以把视频下载到本地了。这也意味着:关于本次视频下载爬虫的介绍也就结束了,剩下的就是根据自己实际需求对代码进行包装即可。
这里提供一个我自己的代码,仅供参考:
# =============================================================================
# 好看视频_v0.1
# =============================================================================
import re
import os
import time
import queue
import requests
import threading
import pandas as pd
class Haokan:
def __init__(self):
self.url = 'https://haokan.baidu.com/videoui/page/search?pn=%drn=20_format=jsontab=videoquery=%s'
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; Win64; x64; rv:80.0) Gecko/20100101 Firefox/80.0',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'Connection': 'keep-alive',
'Upgrade-Insecure-Requests': '1',
'TE': 'Trailers',
}
self.savaPath = './videos' # 视频存储路径
def get_info(self,keywords,page):
'''
搜索关键字,获取相关视频信息
'''
self.result = [] # 相关视频信息
for p in range(1,page+1):
res = requests.get(self.url%(p,keywords),headers=self.headers)
data = res.json()['data']['response']
videos = data['list']
self.result.extend(videos)
print('"第%d页"爬取完成!'%(p+1))
self.result = pd.DataFrame(self.result)
self.result.to_excel('%s.xlsx'%keywords,index=False)
# 定义队列,用于多线程下载视频
self.url_queue = queue.Queue()
for vid,url in zip(self.result['vid'],self.result['url']):
self.url_queue.put((vid,url))
def get_videoUrl(self,url):
'''
提取视频信息中的视频源地址
'''
res = requests.get(url,headers=self.headers)
html = res.text
videoUrl = re.findall('video class="video" src=(.*?)>',html)[0]
return videoUrl
def download_video(self,videoId,videoUrl):
'''
下载视频文件
'''
# 如果视频存储目录不存在则创建
if not os.path.exists(self.savaPath):
os.mkdir(self.savaPath)
res = requests.get(videoUrl,headers=self.headers)
with open('%s/%s.mp4'%(self.savaPath,videoId),'wb') as f:
f.write(res.content)
def run(self):
while not self.url_queue.empty():
t_s = time.time()
vid,url = self.url_queue.get()
try:
video_url = self.get_videoUrl(url)
self.download_video(vid,video_url)
except:
print('"%s.mp4"下载失败!'%vid)
continue
t_e = time.time()
print('"%s.mp4"下载完成!(用时%.2fs)'%(vid,t_e-t_s))
if __name__ == "__main__":
keywords = '多啦A梦'
page = 1 # 爬取页数,每页20条信息
t_s = time.time()
haokan = Haokan()
haokan.get_info(keywords,page)
N_thread = 3 # 线程数
thread_list = []
for i in range(N_thread):
thread_list.append(threading.Thread(target=haokan.run))
for t in thread_list:
t.start()
for t in thread_list:
t.join()
t_e = time.time()
print('任务完成!(用时%.2fs)'%(t_e-t_s))
运行代码,可以看到小频频全都来到我的碗里了😍~

今天分享的视频下载算是最基础的了,它宛如一位慈祥的老奶奶,慈眉善目,面带笑容。它没有各种繁琐的反爬机制(甚至连headers都不进行验证),而且数据返回的格式也是极其友好的,就连视频格式也显得如此的温柔。
我相信在“她”的陪伴下,我们可以走好学习爬虫的第一步。纵使日后我们还将面临IP验证、参数验证、验证码、行为检测、瑞数系统等等诸多反爬考验,也许还需应对视频格式转换等挑战。
但是,请记住kimol君将始终陪伴在你们身边~
最后,感谢各位大大的耐心阅读,咋们下次再会~
以上就是用python制作个视频下载器的详细内容,更多关于python 制作视频下载器的资料请关注脚本之家其它相关文章!

 咨 询 客 服
咨 询 客 服