本次案例以爬取起小点小说为例
案例目的:
通过爬取起小点小说月票榜的名称和月票数,介绍如何破解字体加密的反爬,将加密的数据转化成明文数据。
程序功能:
输入要爬取的页数,得到每一页对应的小说名称和月票数。
案例分析: 找到目标的url:
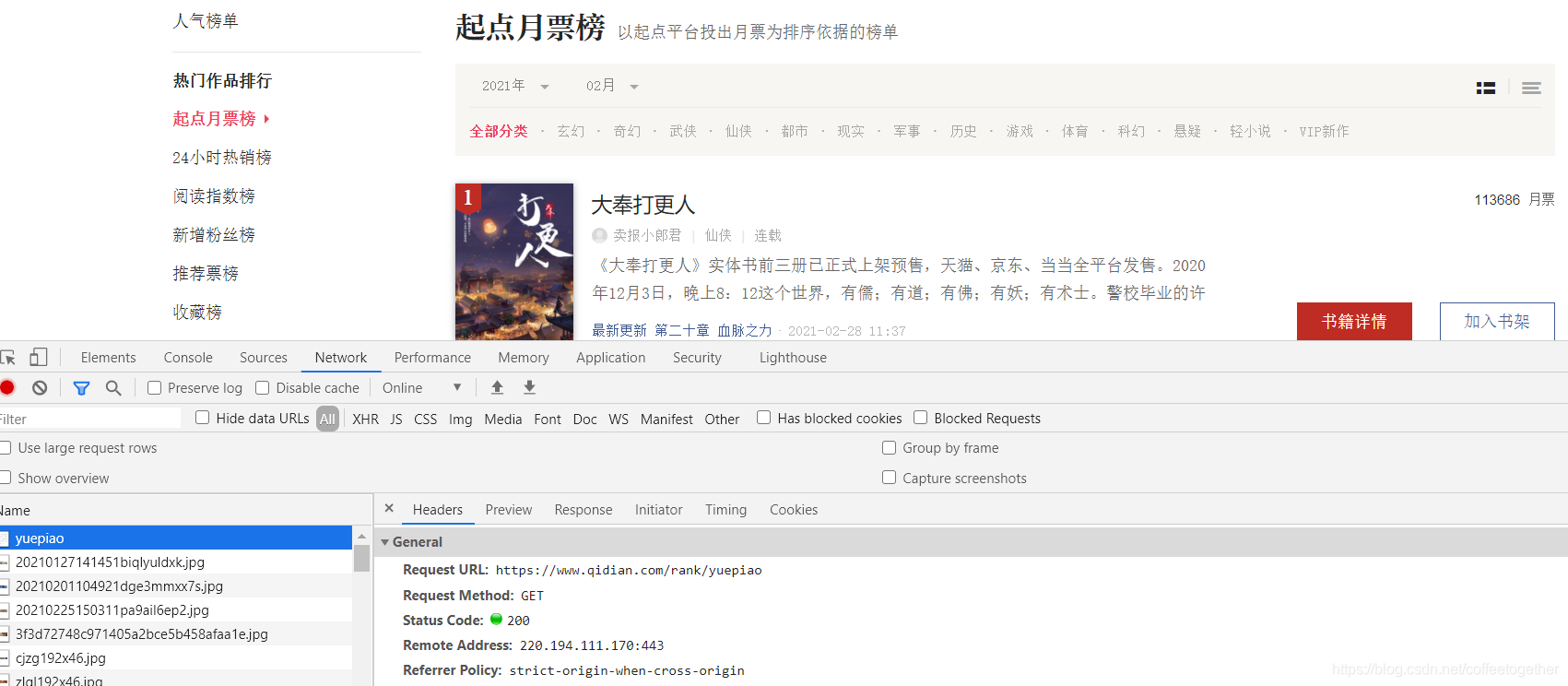
(右键检查)找到小说名称所在的位置:
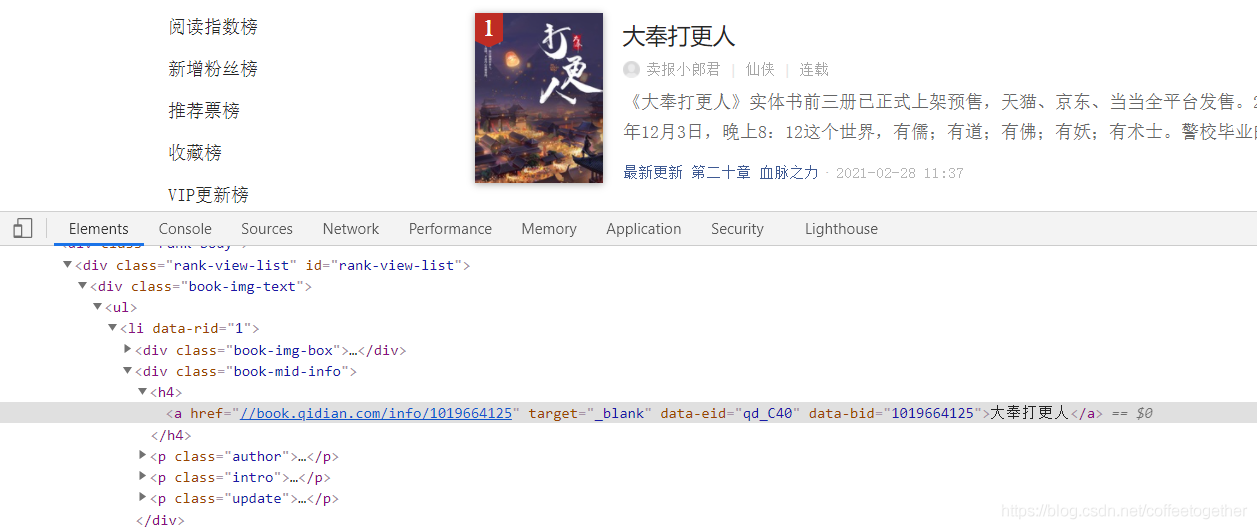
通过名称所在的节点位置,找到小说名称的xpath语法:
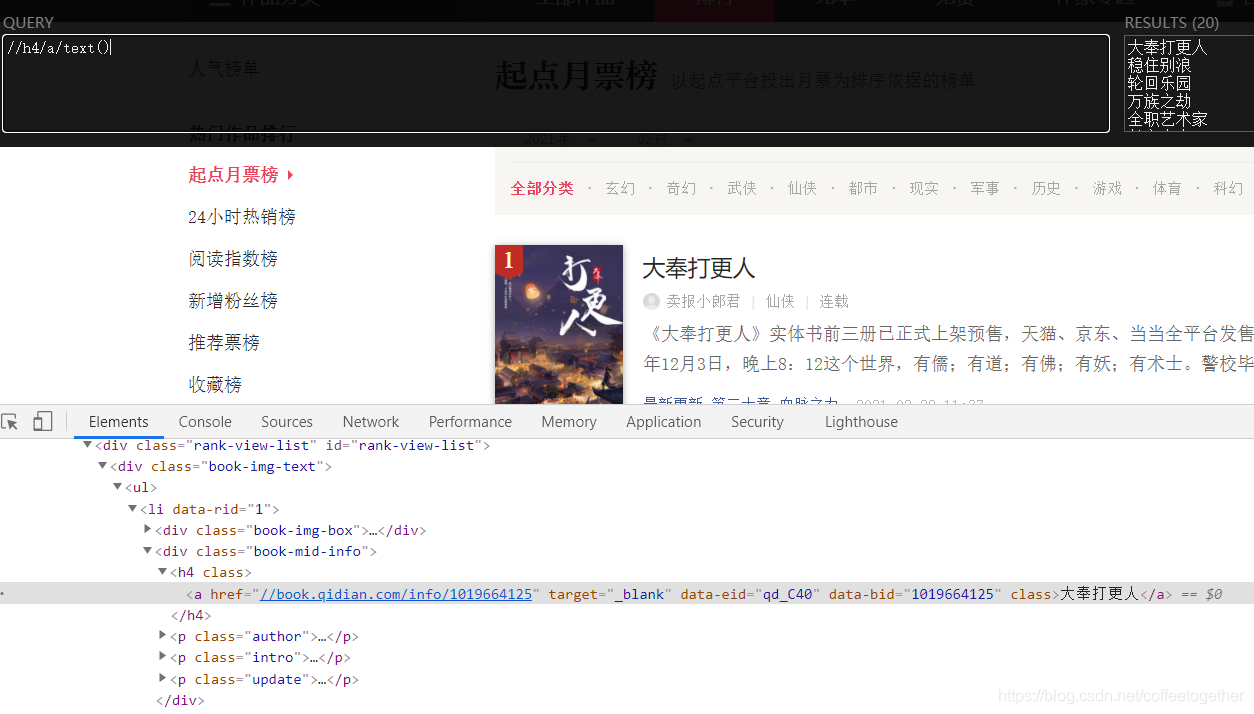
(右键检查)找到月票数所在的位置:
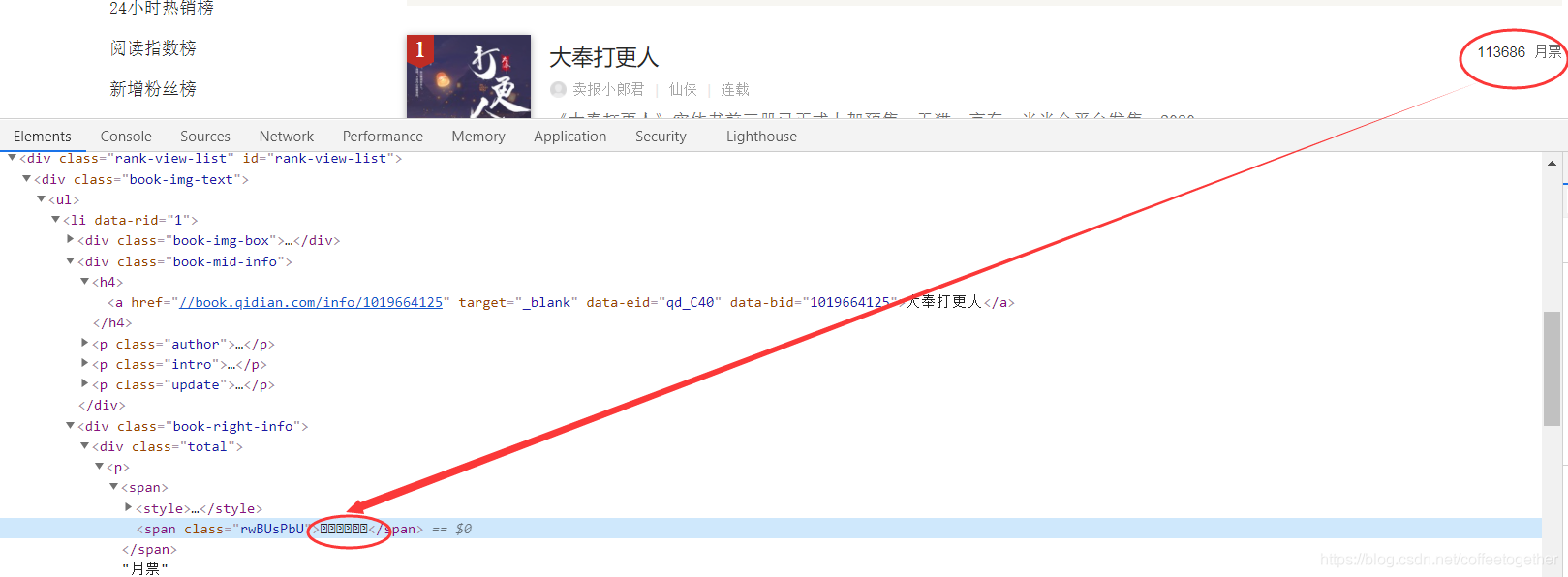
由上图发现,检查月票数据的文本,得到一串加密数据。
我们通过xpathhelper进行调试发现,无法找到加密数据的语法。因此,需要通过正则表达式进行提取。
通过正则进行数据提取。

正则表达式如下:

得到的加密数据如下:

破解加密数据是本次案例的关键:
既然是加密数据,就会有加密数据所对应的加密规则的Font文件。
通过找到Font字体文件中数据加密文件的url,发送请求,获取响应,得到加密数据的woff文件。
注:我们需要的woff文件,名称与加密月票数前面的class属性相同。

如下图,下载woff文件:
找到16进制的数字对应的英文数字。
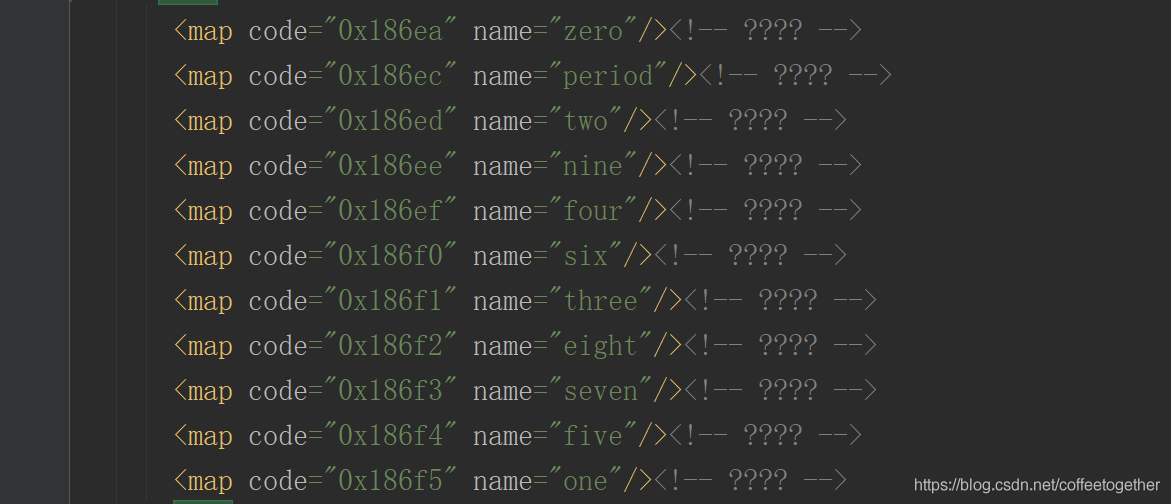
其次,我们需要通过第三方库TTFont将文件中的16进制数转换成10进制,将英文数字转换成阿拉伯数字。如下图:

解析出每个加密数据对应的对应的月票数的数字如下:

注意:
由于我们在上面通过正则表式获得的加密数据携带特殊符号
因此解析出月票数据中的数字之后,除了将特殊符号去除,还需把每个数字进行拼接,得到最后的票数。
最后,通过对比不同页的url,找到翻页的规律:



对比三个不同url发现,翻页的规律在于参数page
所以问题分析完毕,开始代码:
import requests
from lxml import etree
import re
from fontTools.ttLib import TTFont
import json
if __name__ == '__main__':
# 输入爬取的页数、
pages = int(input('请输入要爬取的页数:')) # eg:pages=1,2
for i in range(pages): # i=0,(0,1)
page = i+1 # 1,(1,2)
# 确认目标的url
url_ = f'https://www.qidian.com/rank/yuepiao?page={page}'
# 构造请求头参数
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.150 Safari/537.36'
}
# 发送请求,获取响应
response_ = requests.get(url_,headers=headers)
# 响应类型为html问文本
str_data = response_.text
# 将html文本转换成python文件
py_data = etree.HTML(str_data)
# 提取文本中的目标数据
title_list = py_data.xpath('//h4/a[@target="_blank"]/text() ')
# 提取月票数,由于利用xpath语法无法提取,因此换用正则表达式,正则提取的目标为response_.text
mon_list = re.findall('/style>span class=".*?">(.*?)/span>/span>',str_data)
print(mon_list)
# 获取字体反爬woff文件对应的url,xpath配合正则使用
fonturl_str = py_data.xpath('//p/span/style/text()')
font_url = re.findall(r"format\('eot'\); src: url\('(.*?)'\) format\('woff'\)",str_data)[0]
print(font_url)
# 获得url之后,构造请求头获取响应
headers_ = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.150 Safari/537.36',
'Referer':'https://www.qidian.com/'
}
# 发送请求,获取响应
font_response = requests.get(font_url,headers=headers_)
# 文件类型未知,因此用使用content格式
font_data = font_response.content
# 保存到本地
with open('加密font文件.woff','wb')as f:
f.write(font_data)
# 解析加密的font文件
font_obj = TTFont('加密font文件.woff')
# 将文件转成明文的xml文件
font_obj.saveXML('加密font文件.xml')
# 获取字体加密的关系映射表,将16进制转换成10进制
cmap_list = font_obj.getBestCmap()
print('字体加密关系映射表:',cmap_list)
# 创建英文转英文的字典
dict_e_a = {'one':'1','two':'2','three':'3','four':'4','five':'5','six':'6',
'seven':'7','eight':'8','nine':'9','zero':'0'}
# 将英文数据进行转换
for i in cmap_list:
for j in dict_e_a:
if j == cmap_list[i]:
cmap_list[i] = dict_e_a[j]
print('转换为阿拉伯数字的映射表为:',cmap_list)
# 去掉加密的月票数据列表中的符号
new_mon_list = []
for i in mon_list:
list_ = re.findall(r'\d+',i)
new_mon_list.append(list_)
print('去掉符号之后的月票数据列表为:',new_mon_list)
# 最终解析月票数据
for i in new_mon_list:
for j in enumerate(i):
for k in cmap_list:
if j[1] == str(k):
i[j[0]] = cmap_list[k]
print('解析之后的月票数据为:',new_mon_list)
# 将月票数据进行拼接
new_list = []
for i in new_mon_list:
j = ''.join(i)
new_list.append(j)
print('解析出的明文数据为:',new_list)
# 将名称和对应的月票数据放进字典,并转换成json格式及进行保存
for i in range(len(title_list)):
dict_ = {}
dict_[title_list[i]] = new_list[i]
# 将字典转换成json格式
json_data = json.dumps(dict_,ensure_ascii=False)+',\n'
# 将数据保存到本地
with open('翻页起小点月票榜数据爬取.json','a',encoding='utf-8')as f:
f.write(json_data)
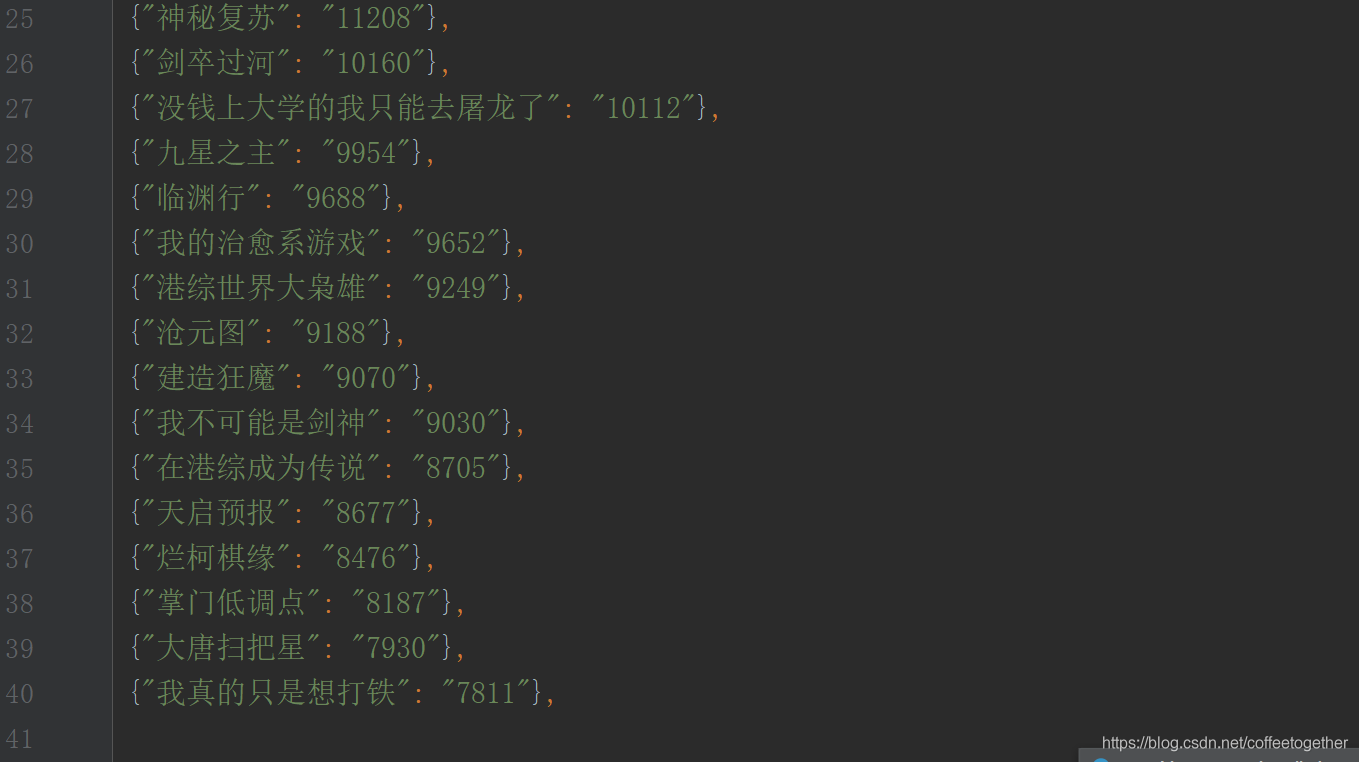
爬取了两页的数据,每一页包含20个数据
执行结果如下:
到此这篇关于python爬虫破解字体加密案例详解的文章就介绍到这了,更多相关python爬虫破解字体加密内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
您可能感兴趣的文章:- scrapy在python爬虫中搭建出错的解决方法
- scrapy-redis分布式爬虫的搭建过程(理论篇)
- Python爬虫代理池搭建的方法步骤
- windows下搭建python scrapy爬虫框架步骤
- windows7 32、64位下python爬虫框架scrapy环境的搭建方法
- 使用Docker Swarm搭建分布式爬虫集群的方法示例
- 快速一键生成Python爬虫请求头
- 一文读懂python Scrapy爬虫框架
- 快速搭建python爬虫管理平台


 咨 询 客 服
咨 询 客 服