目录
- 1. python爬取网易财经不同板块股票数据
- 2. excel树状图
- 2.1. 简单的树状图
- 2.2. 带有增长率的树状图
- 2.3.1. 增长率配色
- 2.3.2. VBA填充色块颜色
- VBA思路:
- VBA代码:
大家好,最近大A的白马股们简直 跌妈不认,作为重仓了抱团白马股基金的养鸡少年,每日那是一个以泪洗面啊。
不过从金融界最近一个交易日的大盘云图来看,其实很多中小股还是红色滴,绿的都是白马股们。
以下截图来自金融界网站-大盘云图:
那么,今天我们试着用python爬取最近交易日的股票数据,并试着用excel简单绘制以下上面这个树状图。本文旨在抛砖引玉,吼吼。
1. python爬取网易财经不同板块股票数据
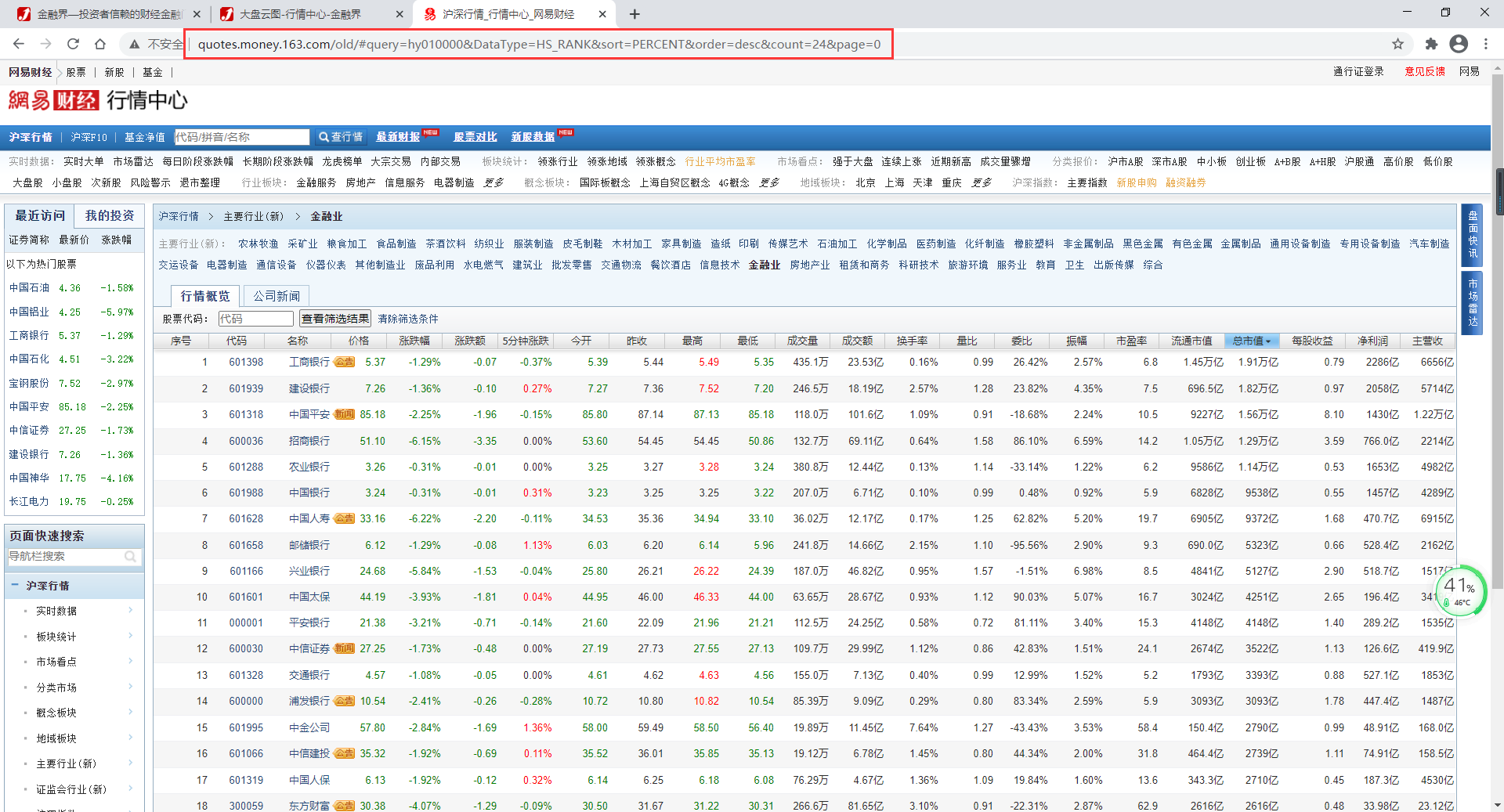
目标网址:
http://quotes.money.163.com/old/#query=hy010000DataType=HS_RANKsort=PERCENTorder=desccount=24page=0
由于这个爬虫部分比较简单,这里不做过多赘述,仅介绍一下思路并附上完整代码供大家参考。
爬虫思路:
- 请求目标网站数据,解析出主要行业(新)的数据:行业板块名称及对应id(如金融,hy010000)
- 根据行业板块对应id构造新的行业股票数据网页
- 由于翻页网址不变,按照《》的里的套路找到股票列表数据的真实地址
- 代入参数,获取全部页数,然后翻页爬取全部数据
爬虫代码:
# -*- coding: utf-8 -*-
"""
Created Feb 28 10:30:56 2021
@author: 可以叫我才哥
"""
import requests
import re
import pandas as pd
# 获取全部板块及板块id
url = 'http://quotes.money.163.com/old/#query=hy001000DataType=HS_RANKsort=PERCENTorder=desccount=24page=0'
r = requests.get(url)
html = r.text
# 替换非字符为空,便于下面的正则
html = re.sub('\s','',html)
# 正则获取 板块及id所在区域
labelHtml = re.findall(r'/span>主要行业\(新\)/a>(.*?)/span>证监会行业\(新\)',html)[0]
# 正则板块和id,结果为由元组组成的列表
label = re.findall(r'"qid="(hy.*?)"qquery=.*?"title="(.*?)">',labelHtml)
# 转化为dataframe类型
dfLabel = pd.DataFrame(label,columns=['id','板块'])
# 根据板块id和翻页获取页面数据(json格式)
def get_json(hy_id, page):
query = 'PLATE_IDS:' + str(hy_id)
params={
'host': 'http://quotes.money.163.com/hs/service/diyrank.php',
'page': page,
'query': query,
'fields': 'NO,SYMBOL,NAME,PRICE,PERCENT,UPDOWN,FIVE_MINUTE,OPEN,YESTCLOSE,HIGH,LOW,VOLUME,TURNOVER,HS,LB,WB,ZF,PE,MCAP,TCAP,MFSUM,MFRATIO.MFRATIO2,MFRATIO.MFRATIO10,SNAME,CODE,ANNOUNMT,UVSNEWS', #你可以不用这么多字段
'sort': 'PERCENT',
'order': 'desc',
'count': '24',
'type': 'query',
}
url = 'http://quotes.money.163.com/hs/service/diyrank.php?'
r = requests.get(url,params=params)
j = r.json()
return j
# 空列表用于存取每页数据
dfs = []
# 遍历全部板块
for hy_id,板块 in dfLabel.values:
# 获取页数
j = get_json(hy_id, 0)
pages = j['pagecount']
for page in range(pages):
j = get_json(hy_id, page)
data = j['list']
df = pd.DataFrame(data)
df['板块'] = 板块
dfs.append(df)
print(f'已爬取{len(dfs)}个板块数据')
result = pd.concat(dfs)
2. excel树状图
excel树状图是在office2016级之后版本中新加的图表类型,想要绘制需要基于此版本及之后的版本哦。
2.1. 简单的树状图
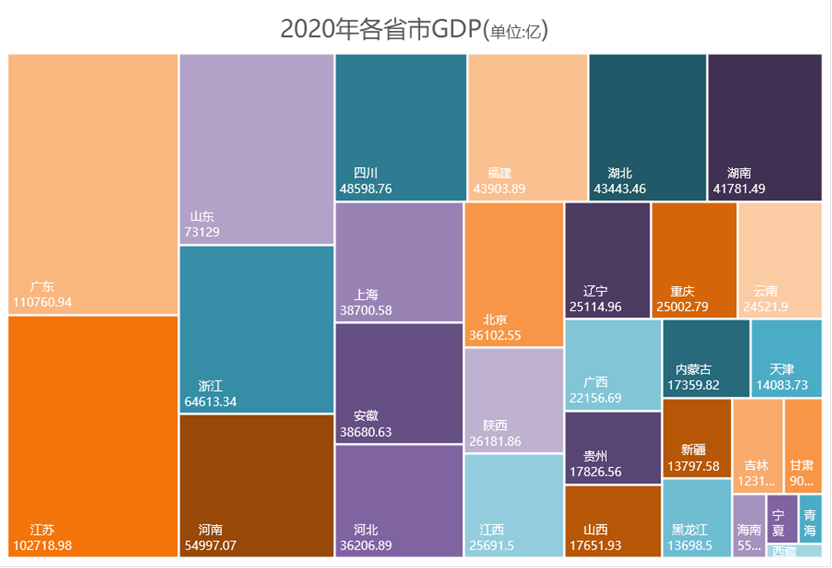
简单的树状图绘制流程:框选数据—>插入—>图表—>选中树状图 即可。
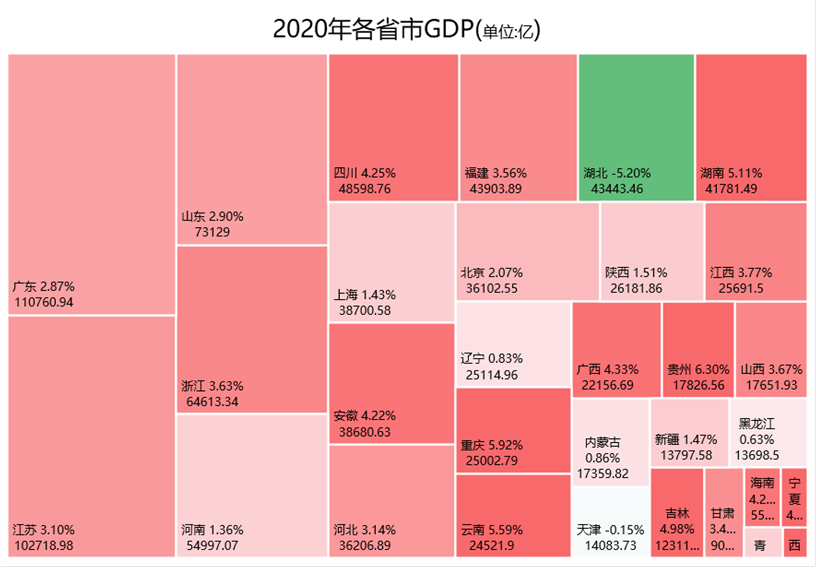
以下图为例,在树状图中,每个色块代表一个省份,色块面积大小则由其GDO值大小决定。
2.2. 带有增长率的树状图
我们发现,在基础的树状图中,色块颜色除了区别色块之外并没有其他特殊含义。拿GDP来说,除了值之外我们一般也会去看其增长率,那么是否可以让色块颜色和增长率有关联呢?
下面我们试着探究一下,如果成功的话,那么金融界的大盘云图似乎也可以用excel树状图来进行绘制了不是!
思路:
- 我们希望色块颜色能代表增长率,比如红色是上涨,绿色是下降且颜色越深代表绝对值越大
- 再对每个色块进行对应的颜色填充即可
由于 树状图顶多支持多级,色块颜色也只能手动单一填充,怎么办呢?既然手动可以,那么其实就可以用VBA自动化这个过程咯。
2.3.1. 增长率配色
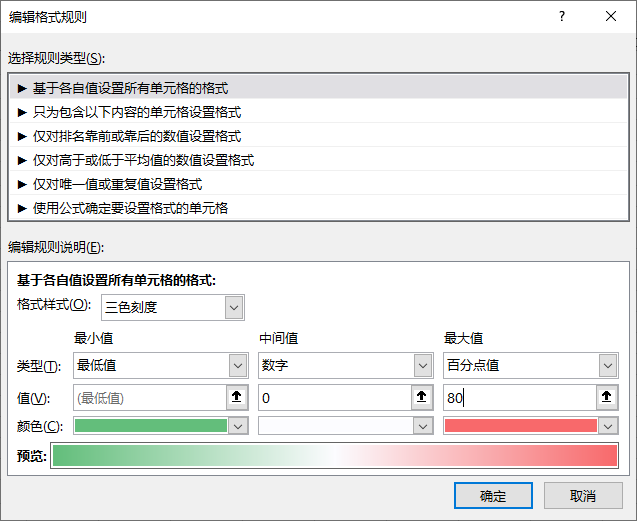
基于思路1,我们需要对增长率进行配色,最简单的就是用条件格式里的色阶。
框选增长率数据—>开始—>条件格式—>色阶(选中那个让值越大颜色越红的,由于这里有负增长率,所以选了带红绿的):

为了更好的展示区分正负增长率,我们在设置完色阶后再进行管理规则:
- 我们将中间值设为数字0,这样负增长率就是绿色,正增长率就是红色;
- 我们将最大值设置为百分点值80,也就是增长率前80%的值都是最红的。
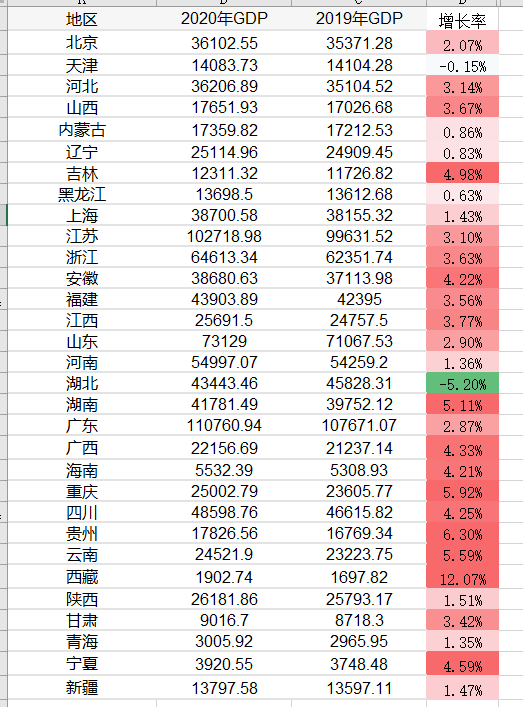
最终配色效果:
2.3.2. VBA填充色块颜色
先看效果:
湖北因为收到疫情影响最大,有接近小半年属于封省状态,全年增长率为负数。
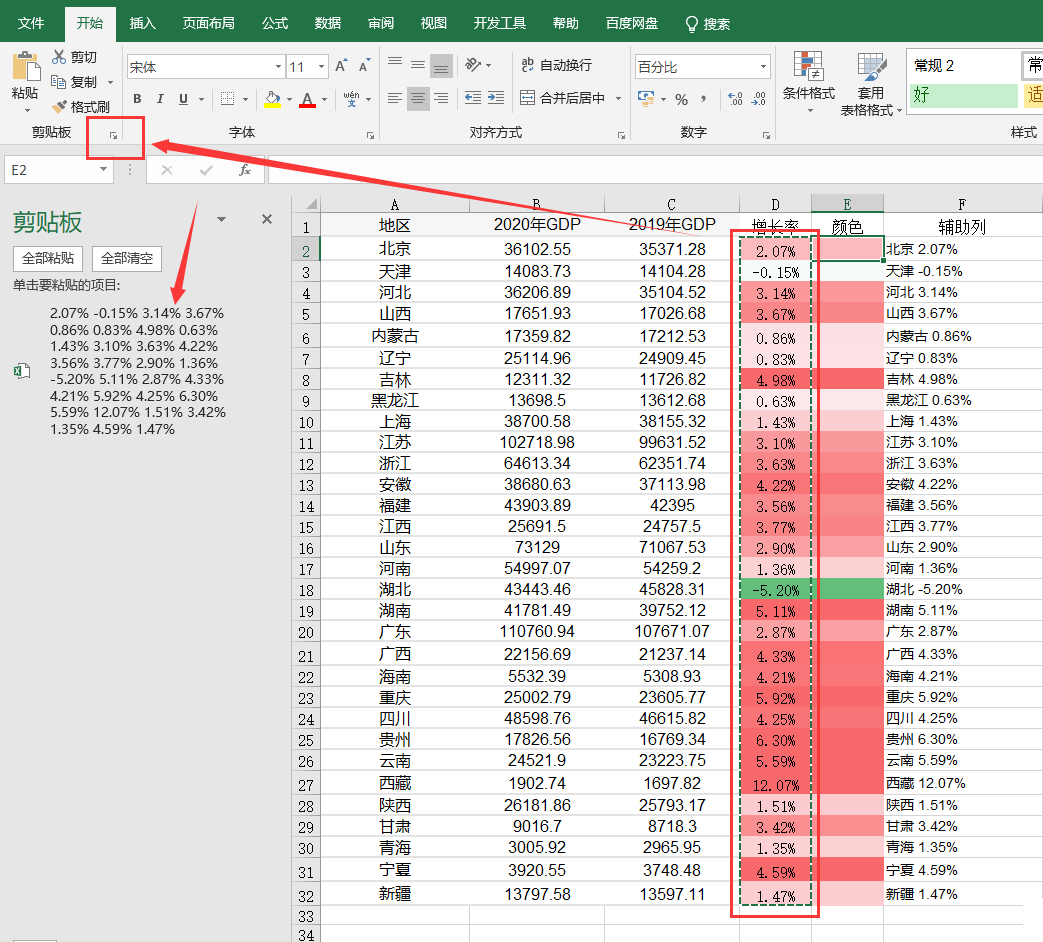
由于条件格式下单元格颜色是不固定的无法通过vba获取,我们需要将颜色赋值到新的一列中去,需要用到如下操作:
**选中增长率数据复制,然后点击剪切板最右下角会出现剪贴板,再鼠标左键选择需要粘贴的地方如E2,点击剪贴板中需要粘贴的数据即可。**这个时候,被粘贴的单元格区域的颜色就是固定的了,你可以选择删除数据只留颜色部分。
VBA思路:
激活需要操作的图表(Activate)
遍历全部的系列和数据点(ActiveChart.FullSeriesCollection(1).Points.Count)
从第一个数据点开始,获取对应增长率单元格颜色(ActiveSheet.Range("E" i + 1).Interior.Color)
将单元格赋值给该数据点(Selection.Format.Fill.ForeColor.RGB)
VBA代码:
Sub My_Color()
ActiveSheet.ChartObjects("图表 1").Activate
'遍历全部的数据点
For i = 1 To ActiveChart.FullSeriesCollection(1).Points.Count
'选中数据点
ActiveChart.FullSeriesCollection(1).Points(i).Select
'获取单元格颜色
MyColor = ActiveSheet.Range("E" i + 1).Interior.Color
'将单元格颜色赋值给对应数据点填充色
Selection.Format.Fill.ForeColor.RGB = MyColor
Next
End Sub
执行脚本过程如下:
好了,以上就是本次全部内容,大家可以试着爬取股票数据,然后试着绘制一下。
温馨提示:接近小5000股票数据,vba填充色块颜色会卡死,不建议全选操作。
以上就是python爬取股票最新数据并用excel绘制树状图的示例的详细内容,更多关于python 爬取股票数据并绘图的资料请关注脚本之家其它相关文章!
您可能感兴趣的文章:- Python爬虫回测股票的实例讲解
- 使用python爬虫实现网络股票信息爬取的demo
- python基于机器学习预测股票交易信号
- 如何用Python中Tushare包轻松完成股票筛选(详细流程操作)
- python实现马丁策略回测3000只股票的实例代码
- 基于Python爬取搜狐证券股票过程解析
- 基于Python爬取股票数据过程详解
- 关于python tushare Tkinter构建的简单股票可视化查询系统(Beta v0.13)
- Python爬取股票信息,并可视化数据的示例
- python用线性回归预测股票价格的实现代码
- python 简单的股票基金爬虫


 咨 询 客 服
咨 询 客 服





