1.torch.optim优化器实现L2正则化
torch.optim集成了很多优化器,如SGD,Adadelta,Adam,Adagrad,RMSprop等,这些优化器自带的一个参数weight_decay,用于指定权值衰减率,相当于L2正则化中的λ参数,注意torch.optim集成的优化器只有L2正则化方法,你可以查看注释,参数weight_decay 的解析是:
weight_decay (float, optional): weight decay (L2 penalty) (default: 0)
使用torch.optim的优化器,可如下设置L2正则化
optimizer = optim.Adam(model.parameters(),lr=learning_rate,weight_decay=0.01)

但是这种方法存在几个问题,
(1)一般正则化,只是对模型的权重W参数进行惩罚,而偏置参数b是不进行惩罚的,而torch.optim的优化器weight_decay参数指定的权值衰减是对网络中的所有参数,包括权值w和偏置b同时进行惩罚。很多时候如果对b 进行L2正则化将会导致严重的欠拟合,因此这个时候一般只需要对权值w进行正则即可。(PS:这个我真不确定,源码解析是 weight decay (L2 penalty) ,但有些网友说这种方法会对参数偏置b也进行惩罚,可解惑的网友给个明确的答复)
(2)缺点:torch.optim的优化器固定实现L2正则化,不能实现L1正则化。如果需要L1正则化,可如下实现:
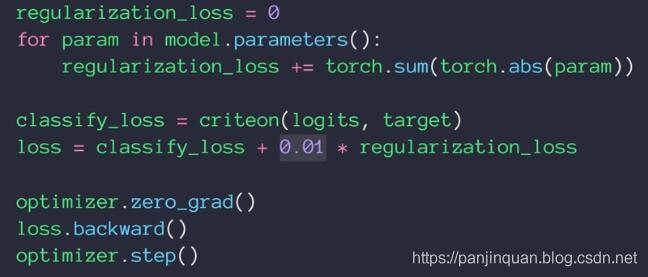
(3)根据正则化的公式,加入正则化后,loss会变原来大,比如weight_decay=1的loss为10,那么weight_decay=100时,loss输出应该也提高100倍左右。而采用torch.optim的优化器的方法,如果你依然采用loss_fun= nn.CrossEntropyLoss()进行计算loss,你会发现,不管你怎么改变weight_decay的大小,loss会跟之前没有加正则化的大小差不多。这是因为你的loss_fun损失函数没有把权重W的损失加上。
(4)采用torch.optim的优化器实现正则化的方法,是没问题的!只不过很容易让人产生误解,对鄙人而言,我更喜欢TensorFlow的正则化实现方法,只需要tf.get_collection(tf.GraphKeys.REGULARIZATION_LOSSES),实现过程几乎跟正则化的公式对应的上。
(5)Github项目源码:点击进入
为了,解决这些问题,我特定自定义正则化的方法,类似于TensorFlow正则化实现方法。
2. 如何判断正则化作用了模型?
一般来说,正则化的主要作用是避免模型产生过拟合,当然啦,过拟合问题,有时候是难以判断的。但是,要判断正则化是否作用了模型,还是很容易的。下面我给出两组训练时产生的loss和Accuracy的log信息,一组是未加入正则化的,一组是加入正则化:
2.1 未加入正则化loss和Accuracy
优化器采用Adam,并且设置参数weight_decay=0.0,即无正则化的方法
optimizer = optim.Adam(model.parameters(),lr=learning_rate,weight_decay=0.0)
训练时输出的 loss和Accuracy信息
step/epoch:0/0,Train Loss: 2.418065, Acc: [0.15625]
step/epoch:10/0,Train Loss: 5.194936, Acc: [0.34375]
step/epoch:20/0,Train Loss: 0.973226, Acc: [0.8125]
step/epoch:30/0,Train Loss: 1.215165, Acc: [0.65625]
step/epoch:40/0,Train Loss: 1.808068, Acc: [0.65625]
step/epoch:50/0,Train Loss: 1.661446, Acc: [0.625]
step/epoch:60/0,Train Loss: 1.552345, Acc: [0.6875]
step/epoch:70/0,Train Loss: 1.052912, Acc: [0.71875]
step/epoch:80/0,Train Loss: 0.910738, Acc: [0.75]
step/epoch:90/0,Train Loss: 1.142454, Acc: [0.6875]
step/epoch:100/0,Train Loss: 0.546968, Acc: [0.84375]
step/epoch:110/0,Train Loss: 0.415631, Acc: [0.9375]
step/epoch:120/0,Train Loss: 0.533164, Acc: [0.78125]
step/epoch:130/0,Train Loss: 0.956079, Acc: [0.6875]
step/epoch:140/0,Train Loss: 0.711397, Acc: [0.8125]
2.1 加入正则化loss和Accuracy
优化器采用Adam,并且设置参数weight_decay=10.0,即正则化的权重lambda =10.0
optimizer = optim.Adam(model.parameters(),lr=learning_rate,weight_decay=10.0)
这时,训练时输出的 loss和Accuracy信息:
step/epoch:0/0,Train Loss: 2.467985, Acc: [0.09375]
step/epoch:10/0,Train Loss: 5.435320, Acc: [0.40625]
step/epoch:20/0,Train Loss: 1.395482, Acc: [0.625]
step/epoch:30/0,Train Loss: 1.128281, Acc: [0.6875]
step/epoch:40/0,Train Loss: 1.135289, Acc: [0.6875]
step/epoch:50/0,Train Loss: 1.455040, Acc: [0.5625]
step/epoch:60/0,Train Loss: 1.023273, Acc: [0.65625]
step/epoch:70/0,Train Loss: 0.855008, Acc: [0.65625]
step/epoch:80/0,Train Loss: 1.006449, Acc: [0.71875]
step/epoch:90/0,Train Loss: 0.939148, Acc: [0.625]
step/epoch:100/0,Train Loss: 0.851593, Acc: [0.6875]
step/epoch:110/0,Train Loss: 1.093970, Acc: [0.59375]
step/epoch:120/0,Train Loss: 1.699520, Acc: [0.625]
step/epoch:130/0,Train Loss: 0.861444, Acc: [0.75]
step/epoch:140/0,Train Loss: 0.927656, Acc: [0.625]
当weight_decay=10000.0
step/epoch:0/0,Train Loss: 2.337354, Acc: [0.15625]
step/epoch:10/0,Train Loss: 2.222203, Acc: [0.125]
step/epoch:20/0,Train Loss: 2.184257, Acc: [0.3125]
step/epoch:30/0,Train Loss: 2.116977, Acc: [0.5]
step/epoch:40/0,Train Loss: 2.168895, Acc: [0.375]
step/epoch:50/0,Train Loss: 2.221143, Acc: [0.1875]
step/epoch:60/0,Train Loss: 2.189801, Acc: [0.25]
step/epoch:70/0,Train Loss: 2.209837, Acc: [0.125]
step/epoch:80/0,Train Loss: 2.202038, Acc: [0.34375]
step/epoch:90/0,Train Loss: 2.192546, Acc: [0.25]
step/epoch:100/0,Train Loss: 2.215488, Acc: [0.25]
step/epoch:110/0,Train Loss: 2.169323, Acc: [0.15625]
step/epoch:120/0,Train Loss: 2.166457, Acc: [0.3125]
step/epoch:130/0,Train Loss: 2.144773, Acc: [0.40625]
step/epoch:140/0,Train Loss: 2.173397, Acc: [0.28125]
2.3 正则化说明
就整体而言,对比加入正则化和未加入正则化的模型,训练输出的loss和Accuracy信息,我们可以发现,加入正则化后,loss下降的速度会变慢,准确率Accuracy的上升速度会变慢,并且未加入正则化模型的loss和Accuracy的浮动比较大(或者方差比较大),而加入正则化的模型训练loss和Accuracy,表现的比较平滑。
并且随着正则化的权重lambda越大,表现的更加平滑。这其实就是正则化的对模型的惩罚作用,通过正则化可以使得模型表现的更加平滑,即通过正则化可以有效解决模型过拟合的问题。
3.自定义正则化的方法
为了解决torch.optim优化器只能实现L2正则化以及惩罚网络中的所有参数的缺陷,这里实现类似于TensorFlow正则化的方法。
3.1 自定义正则化Regularization类
这里封装成一个实现正则化的Regularization类,各个方法都给出了注释,自己慢慢看吧,有问题再留言吧
# 检查GPU是否可用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# device='cuda'
print("-----device:{}".format(device))
print("-----Pytorch version:{}".format(torch.__version__))
class Regularization(torch.nn.Module):
def __init__(self,model,weight_decay,p=2):
'''
:param model 模型
:param weight_decay:正则化参数
:param p: 范数计算中的幂指数值,默认求2范数,
当p=0为L2正则化,p=1为L1正则化
'''
super(Regularization, self).__init__()
if weight_decay = 0:
print("param weight_decay can not =0")
exit(0)
self.model=model
self.weight_decay=weight_decay
self.p=p
self.weight_list=self.get_weight(model)
self.weight_info(self.weight_list)
def to(self,device):
'''
指定运行模式
:param device: cude or cpu
:return:
'''
self.device=device
super().to(device)
return self
def forward(self, model):
self.weight_list=self.get_weight(model)#获得最新的权重
reg_loss = self.regularization_loss(self.weight_list, self.weight_decay, p=self.p)
return reg_loss
def get_weight(self,model):
'''
获得模型的权重列表
:param model:
:return:
'''
weight_list = []
for name, param in model.named_parameters():
if 'weight' in name:
weight = (name, param)
weight_list.append(weight)
return weight_list
def regularization_loss(self,weight_list, weight_decay, p=2):
'''
计算张量范数
:param weight_list:
:param p: 范数计算中的幂指数值,默认求2范数
:param weight_decay:
:return:
'''
# weight_decay=Variable(torch.FloatTensor([weight_decay]).to(self.device),requires_grad=True)
# reg_loss=Variable(torch.FloatTensor([0.]).to(self.device),requires_grad=True)
# weight_decay=torch.FloatTensor([weight_decay]).to(self.device)
# reg_loss=torch.FloatTensor([0.]).to(self.device)
reg_loss=0
for name, w in weight_list:
l2_reg = torch.norm(w, p=p)
reg_loss = reg_loss + l2_reg
reg_loss=weight_decay*reg_loss
return reg_loss
def weight_info(self,weight_list):
'''
打印权重列表信息
:param weight_list:
:return:
'''
print("---------------regularization weight---------------")
for name ,w in weight_list:
print(name)
print("---------------------------------------------------")
3.2 Regularization使用方法
使用方法很简单,就当一个普通Pytorch模块来使用:例如
# 检查GPU是否可用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print("-----device:{}".format(device))
print("-----Pytorch version:{}".format(torch.__version__))
weight_decay=100.0 # 正则化参数
model = my_net().to(device)
# 初始化正则化
if weight_decay>0:
reg_loss=Regularization(model, weight_decay, p=2).to(device)
else:
print("no regularization")
criterion= nn.CrossEntropyLoss().to(device) # CrossEntropyLoss=softmax+cross entropy
optimizer = optim.Adam(model.parameters(),lr=learning_rate)#不需要指定参数weight_decay
# train
batch_train_data=...
batch_train_label=...
out = model(batch_train_data)
# loss and regularization
loss = criterion(input=out, target=batch_train_label)
if weight_decay > 0:
loss = loss + reg_loss(model)
total_loss = loss.item()
# backprop
optimizer.zero_grad()#清除当前所有的累积梯度
total_loss.backward()
optimizer.step()
训练时输出的 loss和Accuracy信息:
(1)当weight_decay=0.0时,未使用正则化
step/epoch:0/0,Train Loss: 2.379627, Acc: [0.09375]
step/epoch:10/0,Train Loss: 1.473092, Acc: [0.6875]
step/epoch:20/0,Train Loss: 0.931847, Acc: [0.8125]
step/epoch:30/0,Train Loss: 0.625494, Acc: [0.875]
step/epoch:40/0,Train Loss: 2.241885, Acc: [0.53125]
step/epoch:50/0,Train Loss: 1.132131, Acc: [0.6875]
step/epoch:60/0,Train Loss: 0.493038, Acc: [0.8125]
step/epoch:70/0,Train Loss: 0.819410, Acc: [0.78125]
step/epoch:80/0,Train Loss: 0.996497, Acc: [0.71875]
step/epoch:90/0,Train Loss: 0.474205, Acc: [0.8125]
step/epoch:100/0,Train Loss: 0.744587, Acc: [0.8125]
step/epoch:110/0,Train Loss: 0.502217, Acc: [0.78125]
step/epoch:120/0,Train Loss: 0.531865, Acc: [0.8125]
step/epoch:130/0,Train Loss: 1.016807, Acc: [0.875]
step/epoch:140/0,Train Loss: 0.411701, Acc: [0.84375]
(2)当weight_decay=10.0时,使用正则化
---------------------------------------------------
step/epoch:0/0,Train Loss: 1563.402832, Acc: [0.09375]
step/epoch:10/0,Train Loss: 1530.002686, Acc: [0.53125]
step/epoch:20/0,Train Loss: 1495.115234, Acc: [0.71875]
step/epoch:30/0,Train Loss: 1461.114136, Acc: [0.78125]
step/epoch:40/0,Train Loss: 1427.868164, Acc: [0.6875]
step/epoch:50/0,Train Loss: 1395.430054, Acc: [0.6875]
step/epoch:60/0,Train Loss: 1363.358154, Acc: [0.5625]
step/epoch:70/0,Train Loss: 1331.439697, Acc: [0.75]
step/epoch:80/0,Train Loss: 1301.334106, Acc: [0.625]
step/epoch:90/0,Train Loss: 1271.505005, Acc: [0.6875]
step/epoch:100/0,Train Loss: 1242.488647, Acc: [0.75]
step/epoch:110/0,Train Loss: 1214.184204, Acc: [0.59375]
step/epoch:120/0,Train Loss: 1186.174561, Acc: [0.71875]
step/epoch:130/0,Train Loss: 1159.148438, Acc: [0.78125]
step/epoch:140/0,Train Loss: 1133.020020, Acc: [0.65625]
(3)当weight_decay=10000.0时,使用正则化
step/epoch:0/0,Train Loss: 1570211.500000, Acc: [0.09375]
step/epoch:10/0,Train Loss: 1522952.125000, Acc: [0.3125]
step/epoch:20/0,Train Loss: 1486256.125000, Acc: [0.125]
step/epoch:30/0,Train Loss: 1451671.500000, Acc: [0.25]
step/epoch:40/0,Train Loss: 1418959.750000, Acc: [0.15625]
step/epoch:50/0,Train Loss: 1387154.000000, Acc: [0.125]
step/epoch:60/0,Train Loss: 1355917.500000, Acc: [0.125]
step/epoch:70/0,Train Loss: 1325379.500000, Acc: [0.125]
step/epoch:80/0,Train Loss: 1295454.125000, Acc: [0.3125]
step/epoch:90/0,Train Loss: 1266115.375000, Acc: [0.15625]
step/epoch:100/0,Train Loss: 1237341.000000, Acc: [0.0625]
step/epoch:110/0,Train Loss: 1209186.500000, Acc: [0.125]
step/epoch:120/0,Train Loss: 1181584.250000, Acc: [0.125]
step/epoch:130/0,Train Loss: 1154600.125000, Acc: [0.1875]
step/epoch:140/0,Train Loss: 1128239.875000, Acc: [0.125]
对比torch.optim优化器的实现L2正则化方法,这种Regularization类的方法也同样达到正则化的效果,并且与TensorFlow类似,loss把正则化的损失也计算了。
此外更改参数p,如当p=0表示L2正则化,p=1表示L1正则化。
4. Github项目源码下载
《Github项目源码》点击进入
以上为个人经验,希望能给大家一个参考,也希望大家多多支持脚本之家。如有错误或未考虑完全的地方,望不吝赐教。
您可能感兴趣的文章:- PyTorch 实现L2正则化以及Dropout的操作
- 在PyTorch中使用标签平滑正则化的问题
- Pytorch 如何实现常用正则化


 咨 询 客 服
咨 询 客 服